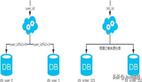
分库分表
分库分表是一种数据库水平扩展的方式,用于解决单一数据库的性能瓶颈和容量限制。
 图片
图片
分库:将一个逻辑数据库划分为多个物理数据库,每个数据库中存储部分数据。
分表:将一个表拆分为多个表,每个表中存储部分数据。
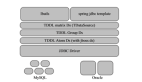
分库分表策略
常见的分库策略有按:范围、按哈希和按列表分片。
 图片
图片
1.按范围分片
根据某个字段的范围将数据划分到不同的数据库中,例如按照用户ID的范围划分。
2.按哈希分片
根据某个字段的哈希值将数据划分到不同的数据库中,例如根据用户ID的哈希值划分。
3.按列表分片
根据预定义的列表将数据划分到不同的数据库中,例如根据城市列表划分用户数据。
分库分表实战
下面是一个分库分表的示例,演示如何使用MyCAT进行分库分表。
1.创建数据库表
首先,创建需要进行分库分表的数据库表,例如user表。
CREATE TABLE `user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;2.配置分片规则
在MyCAT的配置文件中,配置分片规则和数据节点信息。
如下所示:
<?xml versinotallow="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:config PUBLIC "-//MyCat//DTD MyCat config//EN" "http://mycat.io/dtd/mycat.dtd">
<mycat:config xmlns:mycat="http://mycat.io/schema/mycat-config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://mycat.io/schema/mycat-config
http://mycat.io/schema/mycat-config.xsd">
<system>
<property name="schema" value="sharding_db"/>
</system>
<dataNode name="dn1" dataHost="localhost" database="db1" />
<dataNode name="dn2" dataHost="localhost" database="db2" />
<tableRule name="user_rule" dataNode="dn1,dn2">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
</mycat:config>在上述示例中,我们定义了两个数据节点dn1和dn2,分别对应了两个后端MySQL数据库db1和db2。
然后,我们定义了一个表规则:user_rule,使用mod-long算法将数据根据id字段进行分片。
3.分库分表代码
在Java代码中,使用JDBC连接到MyCAT数据库,并执行分库分表的操作。
如下所示:
import java.sql.*;
public class MyCatShardingExample {
public static void main(String[] args) {
try {
// 连接MyCAT数据库
String url = "jdbc:mysql://localhost:8066/sharding_db";
String username = "mycat_user";
String password = "mycat_password";
Connection conn = DriverManager.getConnection(url, username, password);
// 插入数据
String sql = "INSERT INTO user (name) VALUES (?)";
PreparedStatement statement = conn.prepareStatement(sql);
statement.setString(1, "John");
statement.executeUpdate();
// 查询数据
String querySql = "SELECT * FROM user";
Statement queryStatement = conn.createStatement();
ResultSet resultSet = queryStatement.executeQuery(querySql);
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println("User ID: " + id + ", Name: " + name);
}
// 关闭连接
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}在上述示例中,我们使用JDBC连接字符串连接到MyCAT数据库,并执行了插入和查询操作。
分库分表注意
分库分表后有几点很重要,需要重视,比如:
- 数据分布策略:选择合适的数据分布策略,避免数据倾斜;
- 复杂性增加:数据分布在多个库、或表中,管理、和维护变得更加复杂;
- 事务处理困难:跨库、或跨表的事务处理,难度陡增,还会需要分布式事务管理....等等,因为数据已经分布到:不同的环境、和服务器上了。
- 开发成本增加:需要修改、和优化现有的数据库访问代码,比如:需要引入中间件进行路由,比如:(ShardingSphere、MyCat......等等)来简化分库分表的管理。