有 AI 在的科技圈,似乎没有中场休息。除了大模型发布不断,各家科技大厂也在寻找着第一个「杀手级」AI 应用的落脚之地。
OpenAI 首先瞄准的是谷歌 1750 亿美元的搜索业务市场。7 月 25 日,OpenAI 带着 AI 搜索引擎——SearchGPT 高调入场。在演示 demo 中,搜索引擎的使用体验不再像以往一样,需要我们逐个点开网页链接,判断信息有没有用。SearchGPT 像端上了一桌精美的套餐,所有答案都帮你总结好了。

在演示 demo 中,SearchGPT 分析了在应季最适合种植哪种品种的番茄。
不过,鉴于年初发布的 Sora 到目前都还未正式开放,估计很多人排上 SearchGPT 的体验名额也遥遥无期。
然而,有一款国产的开源平替,在和能联网的 ChatGPT 和专攻 AI 搜索引擎的 Perplexity.ai 的 PK 中,它的回答在深度、广度和准确度方面都都秒了这两款明星产品。
它甚至可以在不到 3 分钟内收集并整合 300 多页相关信息。这换成人类专家,需要大约 3 小时才能做完。

这款「国货」就是多智能体框架 MindSearch(思・索),由来自中科大和上海人工智能实验室的研究团队联合研发。正如其名,MindSearch 是一个会「思索」的系统,面对你输入的问题,它将先调用负责充分「思」考问题的智能体,再启用全面搜「索」的智能体,这些智能体分工合作,理解你的需求,并为你呈上从互联网的五湖四海搜罗来的新鲜信息。

- 论文链接:https://arxiv.org/abs/2407.20183
- 项目主页:https://mindsearch.netlify.app/

MindSearch 演示 demo
那么,MindSearch 是凭什么打败 ChatGPT 和 Perplexity.ai 的呢?和别的 AI 搜索引擎相比,MindSearch 有什么独到之处吗?
答案还得从它的名字说起。MindSearch 的核心竞争力在于采用了多智能体框架模拟人的思维过程。
如果向 Perplexity.ai 提问「王者荣耀当前赛季哪个射手最强?」它会直接搜索这个问题,并总结网上已有的回复。把这个问题交给 MindSearch,它会把这个问题拆解成一个逻辑链:「当前赛季是哪个赛季?」,「从哪些指标可以衡量王者荣耀的射手的强度?」,再汇总所能查询到的答案。

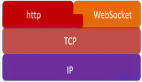
技术实现
WebPlanner:基于图结构进行规划
仅依靠向大型语言模型输入提示词的方式并不能胜任智能搜索引擎。首先,LLM 不能充分理解复杂问题中的拓扑关系,比如前一段挂在热搜上的大模型无法理解 9.9 和 9.11 谁大的问题,就是这个问题的生动注脚。字与字之间的关系,LLM 都很难在简单对话中理解,那么「这个季节种哪个品种的番茄最合适?」这种需要深入思考,分解成多个角度来回答的问题,对于 LLM 就更难了。换句话说,LLM 很难将用户的意图逐步转化为搜索任务,并提供准确的响应,因此它总是提供一些模版式的知识和套话。
基于此,研究团队设计了高级规划器 WebPlanner,它通过构建有向无环图(DAG)来捕捉从提问到解答之间的最优执行路径。对于用户提出的每个问题 Q,WebPlanner 将其解决方案的轨迹表示为 G (Q) = ⟨V, E⟩。在这个图中,V 代表节点的集合,每个节点 v 代表一个独立的网页搜索任务,包括一个辅助的起始节点(代表初始问题)和一个结束节点(代表最终答案)。E 代表有向边,指示节点之间的逻辑和推理关系。
研究团队进一步利用 LLM 优越的代码能力,引导模型编写代码与 DAG 图交互。为了实现这一点,研究团队预定义了原子代码函数,让模型可以在图中添加节点或边。在解答用户问题的过程中,LLM 先阅读整个对话,还有它在网上搜索到的信息。阅读完这些信息后,LLM 会根据这些信息产生一些思考和新的代码,这些代码将通过 Python 解释器添加在用于推理的图结构中。
一旦有新节点加入图中,WebPlanner 将启动 WebSearcher 来执行搜索任务,并整理搜索到的信息。由于新节点只依赖于之前步骤中生成的节点,所以这些节点可以并行处理,大大提高了信息收集的速度。当所有的信息收集完毕,WebPlanner 将添加结束节点,输出最终答案。

WebSearcher:分层检索网页
由于互联网上的信息实在太多,就算是 LLM 也不能一下子处理完所有的页面。针对这个问题,研究团队选择了先广泛搜索再精确选择的策略,设计了一个 RAG 智能体 ——WebSearcher。
首先,LLM 将根据 WebPlanner 分配的问题,生成几个类似的搜索问题,扩大搜索的范围。接下来,系统将调用不同搜索引擎的 API 查询问题,例如分别在 Google、Bing 和 DuckDuckGo 查一下,得到网页的链接、标题和摘要等关键信息。接着,LLM 将从这些搜索结果中选出最重要的网页来仔细阅读,汇总得出最终答案。

MindSearch 中,LLM 如何管理上下文
作为一个多智能体框架,MindSearch 为如何管理长上下文提供了全新尝试。当需要快速阅读大量网页时,由于最终答案只依赖 WebSearcher 的搜索结果,WebPlanner 将专注于分析用户提出的问题,不会被过长的网页信息分心。
这种明确的分工也大大减少了上下文计算量。如何在多个智能体之间高效共享信息和上下文并非易事,研究团队在实证中发现,如果只依靠 WebPlanner 的分析,有可能会在信息收集阶段由于 WebSearcher 内部的局部感知场丢失有用的信息。为了解决这个问题,他们利用有向图边构建的拓扑关系来简化上下文如何在不同智能体间传递。
具体来说,在 WebSearcher 执行搜索任务时,它的父节点以及根节点的回答将作为前缀添加在其回答中。因此,每个 WebSearcher 可以有效地专注于其子任务,同时不会丢失之前的相关上下文或者忘记最终的查询目标。
本地部署
7 月初,上海人工智能实验室已经开源了搭载 MindSearch 架构的 InternLM2.5-7B-Chat 模型。
除了直接点击链接,跳转到体验 Demo 试玩。研究团队还公开了 MindSearch 的完整前后端实现,基于智能体框架 Lagent,感兴趣的朋友可以在本地部署模型。
- 在线 Demo:https://mindsearch.openxlab.org.cn/
- 开源代码:https://github.com/InternLM/mindsearch
在 GitHub 下载 MindSearch 仓库后,输入如下命令就可以打造属于自己的 MindSearch 了:
# 启动服务
python -m mindsearch.app --lang en --model_format internlm_server
## 一键启动多种前端
# Install Node.js and npm
# for Ubuntu
sudo apt install nodejs npm
# for windows
# download from https://nodejs.org/zh-cn/download/prebuilt-installer
# Install dependencies
cd frontend/React
npm install
npm start