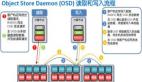
最近做了很多 Rook 的调研工作,边学习边梳理清楚了 Rook 如何管理 Ceph 集群。这篇文章就来讲解 Rook 如何将 Ceph 这么复杂的系统在 Kubernetes 中进行管理和维护。
Ceph 的架构
Ceph 包括多个组件:
- Ceph Monitors(Mon):负责监控集群的全局状态,包括集群的配置信息和数据的映射关系,所有的集群节点都会向 Mon 进行汇报,并在每次状态变更时进行共享信息;负责管理集群的内部状态,包括 OSD 故障后的恢复工作和数据的恢复;以及客户端的查询和授权工作。
- Ceph Object Store Devices(OSD):负责在本地文件系统保存对象,并通过网络提供访问。通常 OSD 守护进程会绑定在集群的一个物理盘上;同时负责监控本身以及其他 OSD 进程的健康状态并汇报给 Mon。
- Ceph Manager(MGR):提供额外的监控和界面给外部的监管系统使用。
- Ceph Metadata Server(MDS):CephFS 的元数据管理进程,主要负责文件系统的元数据管理,只有需要使用 CephFS 的时候才会需要。
Ceph 客户端首先会联系 Mon,获取最新的集群地图,其中包含了集群拓扑以及数据存储位置的信息。然后使用集群地图来获知需要交互的 OSD,从而和特定 OSD 建立联系。
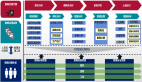
Rook 是一个提供 Ceph 集群管理能力的 Operator,使用 CRD CephCluster 来对 Ceph 集群进行部署和管理。以下是 Rook 的架构图:
 图片
图片
最下层是 Rook Operator 部署的 Ceph 集群的各种组件,通过 CSI Plugin 向上对应用提供不同的访问接口。
安装
本文演示使用的所有 Yaml 文件,均来自 Rook 仓库的 examples。
安装 Rook Operator
Rook Operator 的安装主要分两部分:RBAC 和 operator deployment,分别在两个文件下:
kubectl apply -f common.yaml
kubectl apply -f operator.yaml安装完成后可以看到集群里只有一个 operator pod,非常简洁:
$ kubectl -n rook-ceph get po
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-7d8898f668-2chvz 1/1 Running 0 2d16h安装 CephCluster
Ceph 要求每个存储节点都有一个块设备,建议尽量为所有存储节点分配同样的 CPU、内存和磁盘。
Rook 的 examples 下提供了一个默认配置的 CephCluster 文件 cluster.yaml,在 storage 中可以使用正则表达式 /dev/sd[a-z] 进行设备匹配:
storage:
useAllNodes: true
useAllDevices: false
deviceFilter: sd[a-z]如果节点异构,也可以分 node 写:
storage:
useAllNodes: true
useAllDevices: false
nodes:
- name: "172.17.4.201"
devices:
- name: "sdb"
- name: "nvme01"
- name: "172.17.4.301"
deviceFilter: "^sd."创建了 CephCluster,随后 operator 会安装一系列 ceph 的组件。首先会看到以下 pod:
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-868bf46b56-4xkx4 5/5 Running 0 3s
csi-cephfsplugin-provisioner-868bf46b56-qsxkg 5/5 Running 0 3s
csi-cephfsplugin-4jrsn 2/2 Running 0 3s
csi-cephfsplugin-wfzmm 2/2 Running 0 3s
csi-cephfsplugin-znn9x 2/2 Running 0 3s
csi-rbdplugin-6x94s 2/2 Running 0 3s
csi-rbdplugin-8cmfw 2/2 Running 0 3s
csi-rbdplugin-qm8jr 2/2 Running 0 3s
csi-rbdplugin-provisioner-d9b9d694c-s7vxg 5/5 Running 0 3s
csi-rbdplugin-provisioner-d9b9d694c-tlplc 5/5 Running 0 3s
rook-ceph-mon-a-canary-ddb95876f-wl26c 0/2 ContainerCreating 0 0s
rook-ceph-mon-b-canary-57dc9df878-7ntq9 0/2 ContainerCreating 0 0s
rook-ceph-mon-c-canary-685fdfb595-6cxjj 0/2 ContainerCreating 0 0s主要有 cephfs 和 rbd 的相关 CSI Driver 组件,以及 Mon canary。
Mon canary 是将 Ceph 的 Mon 组件的 command 改成 sleep 3600,并按 cluster 中指定的 placement 等调度信息进行合并后的 Deployment。
管理员可以在 Cluster 中通过 nodeSelector 等调度策略来决定如何部署 Mon。由于 Mon 使用 hostPath 作为其存储,所以 Mon pod 需要固定在特定的节点上。但 Kubernetes 无法做到在 Pod 被调度后,又自动设置上对所在节点的亲和性。
Rook 对这一问题的处理方式是,先部署一个相同配置的 Mon canary Deployment,任由调度器按照 cluster 中设置的调度策略部署 canary pod。再按照调度有 canary pod 的节点,部署一个 Mon deployment,其 nodeSelector 为 kubernetes.io/hostname:<nodeName>,从而实现将 Mon 固定在节点上。
 图片
图片
在 Mon cacnary 完成调度后随即被删除,然后开始部署 Monitor 组件,以及相关的 Mon Manager、CrashController 及 exporter:
NAME READY STATUS RESTARTS AGE
rook-ceph-crashcollector-cn-hongkong.192.168.0.55-66586f572zcg6 1/1 Running 0 15s
rook-ceph-crashcollector-cn-hongkong.192.168.0.56-748b6785dk7wl 1/1 Running 0 7s
rook-ceph-crashcollector-cn-hongkong.192.168.0.57-68774ff8hz42l 1/1 Running 0 15s
rook-ceph-exporter-cn-hongkong.192.168.0.55-789684674-26vwv 1/1 Running 0 15s
rook-ceph-exporter-cn-hongkong.192.168.0.56-694f674bdc-z9znh 1/1 Running 0 7s
rook-ceph-exporter-cn-hongkong.192.168.0.57-bbf8db8c6-2zjbq 1/1 Running 0 15s
rook-ceph-mgr-a-6c4b684b9f-4dx79 2/3 Running 0 15s
rook-ceph-mgr-b-75d5658884-pmq99 2/3 Running 0 15s
rook-ceph-mon-a-5c5dbf577c-2bssb 2/2 Running 0 61s
rook-ceph-mon-b-8d8c56989-g7znk 2/2 Running 0 37s
rook-ceph-mon-c-6677fc9f7c-slhvj 2/2 Running 0 26s当 Monitor 部署成功后,operator 为 OSD 做准备,在每个数据节点创建一个 Job,查询每个节点上是否存在满足以下条件的设备:
- 设备没有分区
- 设备没有格式化的文件系统
 图片
图片
如果有,才会进入下一步部署 OSD 的阶段。
NAME READY STATUS RESTARTS AGE
rook-ceph-osd-prepare-cn-hongkong.192.168.0.55-9fq2t 0/1 Completed 0 11s
rook-ceph-osd-prepare-cn-hongkong.192.168.0.56-bdptk 0/1 Completed 0 11s
rook-ceph-osd-prepare-cn-hongkong.192.168.0.57-7f7bx 0/1 Completed 0 10s 图片
图片
在满足条件的节点上创建 OSD:
NAME READY STATUS RESTARTS AGE
rook-ceph-osd-0-5bbb5d965f-k8k7z 1/2 Running 0 17s
rook-ceph-osd-1-56b689549b-8gj47 1/2 Running 0 16s
rook-ceph-osd-2-5946f9684f-wkwmm 1/2 Running 0 16s至此,整个 Ceph Cluster 算是安装完成了,除了查看各个组件是否 ready 外,还可以使用 Rook 提供的 Ceph Tool 来检查 Ceph 集群是否 work。安装 Ceph Tool:
kubectl apply -f toolbox.yaml在 tool pod 中检查集群状态,在输出中不仅可以可以查看当前 ceph 集群是否健康,还可以查看各个组件的个数及状态:
bash-4.4$ ceph status
cluster:
id: 0212449b-1184-43ff-9d24-e6765d75ac3f
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 7m)
mgr: a(active, since 5m), standbys: b
osd: 3 osds: 3 up (since 6m), 3 in (since 6m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 80 MiB used, 60 GiB / 60 GiB avail
pgs: 1 active+clean访问 Ceph
Ceph 提供 3 种访问方式,分别为对象存储接口(radosgw)、块设备接口(rbd)、文件系统接口(POSIX)。
 图片
图片
其中文件系统接口的访问需要部署元数据服务 MDS;rbd 和 fs 都是通过 CSI Driver 的方式提供挂载到应用容器内,也就是前面看到的两个 CSI Driver。
rgw
rgw 的访问需要 cephobjectstore 这个 CR:
$ kubectl apply -f object.yaml
cephobjectstore.ceph.rook.io/my-store created随后可以看到组件 RGW 被创建出来:
NAME READY STATUS RESTARTS AGE
rook-ceph-rgw-my-store-a-6f6768f457-tq625 1/2 Running 0 33s检查集群状态,可以观察到 RGW:
bash-4.4$ ceph status
cluster:
id: 0212449b-1184-43ff-9d24-e6765d75ac3f
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 11m)
mgr: a(active, since 10m), standbys: b
mds: 1/1 daemons up, 1 hot standby
osd: 3 osds: 3 up (since 11m), 3 in (since 4d)
rgw: 1 daemon active (1 hosts, 1 zones)
...具体使用可以参考 Rook 官方文档
rbd
rbd 接口需要创建 replicapool 这个 CR 和 rbd 的 StorageClass:
$ kubectl apply -f csi/rbd/storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created再创建应用 pod 和 pvc:
kubectl apply -f csi/rbd/pvc.yaml
kubectl apply -f csi/rbd/pod.yaml上述资源都创建完毕后,进入示例 pod 中可查看其中的挂载设备:
$ kubectl exec -it csirbd-demo-pod -- bash
root@csirbd-demo-pod:/#
root@csirbd-demo-pod:/#
root@csirbd-demo-pod:/# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
rbd0 252:0 0 1G 0 disk /var/lib/www/html
vda 253:0 0 120G 0 disk
|-vda1 253:1 0 2M 0 part
|-vda2 253:2 0 200M 0 part
`-vda3 253:3 0 119.8G 0 partfilesystem
fs 接口需要创建 cephfilesystem 和 cephfilesystemsubvolumegroup 两个 CR:
$ kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs created
cephfilesystemsubvolumegroup.ceph.rook.io/myfs-csi created创建完毕后,可以观察集群中已经创建出元数据服务 MDS:
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-9d8c6b7f8-f84pm 2/2 Running 0 17s
rook-ceph-mds-myfs-b-dff454bf6-wxln6 2/2 Running 0 16s这时在 tool pod 中查看集群状态,可以看到 mds 的状态:
bash-4.4$ ceph status
cluster:
id: 0212449b-1184-43ff-9d24-e6765d75ac3f
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 13m)
mgr: a(active, since 12m), standbys: b
mds: 1/1 daemons up, 1 hot standby
osd: 3 osds: 3 up (since 13m), 3 in (since 13m)
...最后部署 StorageClass 、PVC 以及示例应用 pod:
$ kubectl apply -f csi/cephfs/storageclass.yaml
storageclass.storage.k8s.io/rook-cephfs created
$ kubectl apply -f csi/cephfs/pvc.yaml
persistentvolumeclaim/cephfs-pvc created
$ kubectl apply -f csi/cephfs/pod.yaml
pod/csicephfs-demo-pod created进入 pod 查看文件系统挂载点:
$ kubectl exec -it csicephfs-demo-pod -- bash
root@csicephfs-demo-pod:/# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 20G 9.9G 8.4G 54% /
tmpfs 64M 0 64M 0% /dev
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/vdb 20G 9.9G 8.4G 54% /etc/hosts
shm 64M 0 64M 0% /dev/shm
172.16.233.104:6789,172.16.38.236:6789,172.16.112.253:6789:/volumes/csi/csi-vol-37584a87-0dfb-48f2-8eee-647af351a695/fc5823e6-0c7e-4ce3-8565-4429d366ac64 1.0G 0 1.0G 0% /var/lib/www/html
tmpfs 30G 12K 30G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs 16G 0 16G 0% /proc/acpi
tmpfs 16G 0 16G 0% /proc/scsi
tmpfs 16G 0 16G 0% /sys/firmwareCeph 的挂载点名称会显示 Mon 的连接信息。
总结
Rook 对 Ceph 的支持远不止管理其集群,还包括很多数据面的支持,比如对 osd pool 的创建等,还提供了一系列的状态管理和查询。本文只针对 Ceph 集群的创建和管理做了简单的分析和梳理,希望对如何在 Kubernetes 中管理和使用 Ceph 有所帮助。