一、背景
事情的背景就是产品初期,需求急、周期短,同事在完成该需求时以结果导向为主,先实现需求。
就在最近,测试时发现该接口的响应为 2s 多,页面中可以感觉到明显的延迟,所以有了本文,提升一下接口响应速度。

在工作中一定要有产品思维,站在用户的角度,怎么做才能更好。只有当自己站在一个更高的层面,才不会让你受制于当下,并助你突破现状。
先说一下目前的代码逻辑,概括一下就是最外层一个循环,然后循环里面查询数据库,而且是一次循环最少 4 次数据库查询。
- 根据查询条件获取一个总的 list。
- 遍历该 list,读取每个对象中的属性值。
- 根据每个对象属性值再去数据库中获取该子对象。
- 封装返回数据。
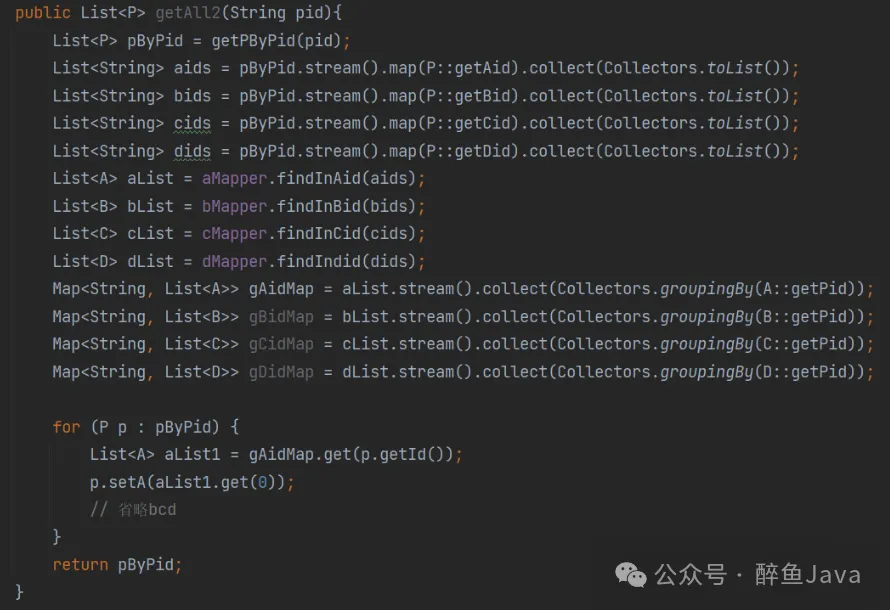
上述代码是根据实际业务改造的,实际业务还是个嵌套的循环,就拿上图中的代码为例,如果让你来优化,你想选择哪些优化方式呢?欢迎评论区交流一下。
二、接口优化
先说下我对于接口提升响应速度解决思路吧。首先想到的是定位代码哪个位置慢,其次慢的原因是什么,最后选择合适的方案解决问题。
- 使用 Arthas 定位代码处理慢的点。
- 选择适合的优化方案。
- 测试优化结果。
对于 Arthas 不了解的可以自己扩展学一下,这里不做过多介绍,只说一句,这是个在线解决生产问题的 Java 诊断工具。
1.定位
对于这个 test 方法我是这样做的,Idea 中有个 Arthas 插件,所以我们直接在 Idea 中复制对应的命令,粘贴到 Arthas 中进行监控,此处使用的是 trace 命令。
test 方法名位置,右键选择 Arthas Command 中的 Trace 或者 Trace Multiple Class Method Trace -E 命令进行复制。
将该命令粘贴到 Arthas 的终端之后,发起对该接口的请求,即可看到每一行代码花费的时间,此处我拿一个其他接口来做示例,参考如下:
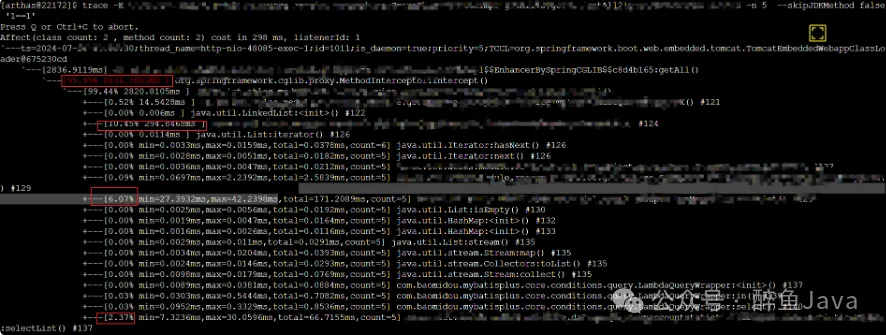
在这个图片中,我们重点关注红框起来的位置,此处打印了该处代码处理时间的占比,占比越高处理时长越长。所以我们只需要关注一下大头,也就是占比多的代码位置进行优化,该接口的响应速度肯定可以提升。
上图中代码位置已经脱密处理,在实际的接口调用栈打印中,每一行输出的末尾都会有代码所在行数。
2.分析
通过上图中使用 Arthas 工具的定位,已经知道了方法中哪一块是处理比较慢的,现在只需要梳理业务逻辑,进行优化即可了。
就以文章开头的 test 方法举例,我的优化方案如下:
- 循环遍历时多次查询数据库进行合并,尽量减少数据库链接查询次数,调用数据库查询代码移动到循环外。
- 根据遍历的对象属性获取数据库中对应信息时,改为 in 查询,多条 SQL 合并为一条 SQL。
- 根据查询 SQL 中使用的参数,创建对应的索引,并确保索引生效。
所以简单概括优化方案就是:使用 IN 查询、避免循环查询数据库、增加索引三种方式。
修改之后的代码结构如下:
- 根据查询条件获取基础对象。
- 取出 list 中某一个值例如 aid,生成新 list,当作下一次查询的查询条件。
- 封装对应数据。
最后就是根据查询条件增加索引,这个本文就不再详细说明了。
3.小结
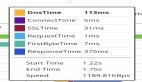
通过使用 In 查询,减少循环中调用数据库,创建索引等手段,再次请求同一个接口,实现了 2s 到 100ms 的优化。其中索引加入之后,速度快了一倍达到 1s 左右,再通过业务逻辑重构最终实现 100ms 的接口响应速度。
留个讨论题,上面优化完成的代码再让你进行优化,你还可以在哪些方面进行优化呢,或者说上面代码可能会留下哪些坑呢?
三、接口常用优化方式
上述的优化方式可以总结为加索引,业务代码重构两个方式。其中减少循环调用数据库是业务代码重构的内容之一。
数据库层面,加索引需要注意的是索引是否生效,是否选错索引等,如果你对 SQL 优化感兴趣,点个关注,后续更新一篇 SQL 优化的小技巧。
除了加索引,当数据量起来之后,常用的优化方式还有分库分表、数据异构、缓存。
1.分库分表
当系统发展到一定程度之后,用户的并发量大,会带来大量的数据库请求,占用大量的数据库连接,同时会带来磁盘IO等方面的问题。
并且随着系统的长时间使用,产生的数据越来越多,造成单表数据量过大,最终造成查询缓慢,即使加了索引查询速度也非常耗时,此时我们就可以使用分库分表的方式进行数据库层的优化。
分库分表大部分同学应该都听过了,这里大概介绍一下。(点个关注,后续深入分析一下分库分表)
- 分库分表有水平与垂直之分,垂直就是业务方向的拆分,水平就是数据方向。
- 分库解决的是数据库连接资源不足的问题。
- 分表解决的是单表数据量过大,SQL 语句即使走了索引查询也非常耗时的问题。
- 在某些业务场景中,用户并发量大,但是保存的数据量很少时,可以只分库,不分表。
- 用户并发量不大,但是保存的数据量很多,可以只分表,不分库。
- 当用户并发量大,数据量也很多时,可以考虑分库分表。

图中将用户库分为3个,在请求到来的时候,可以根据用户ID进行路由到某一个库,然后再定位到某张表。路由规则是可以自己定义的。
2.数据异构
数据异构相当于数据进行冗余,在业务接口中,一般返回前端的数据是需要进行多个数据进行封装的。举个例子,用户信息返回,在返回时封装用户的部门信息,角色信息一起返回。
现在我们在封装好上述数据之后,存入 Redis中,只需要读取一次Redis即可。

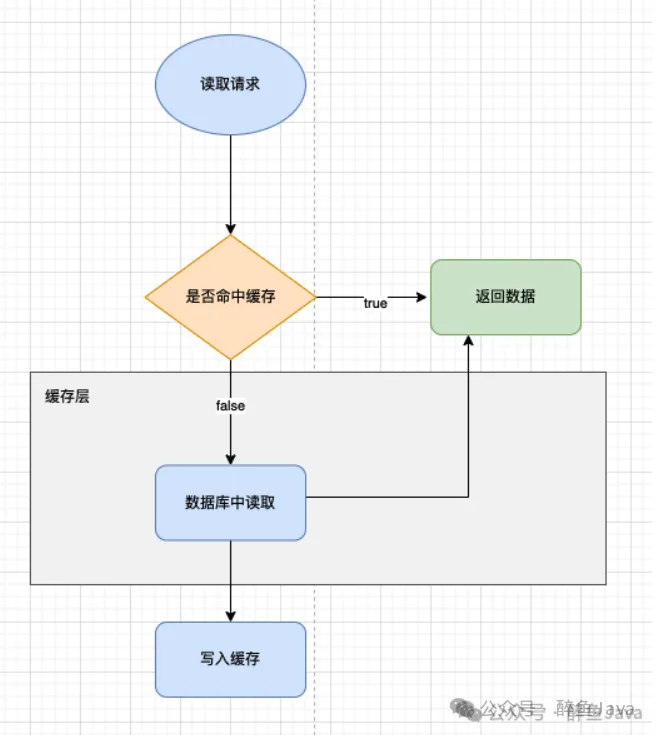
3.缓存
缓存相当于把当前请求的响应结果进行缓存,再次读取时只需要读取缓存,无需复杂的业务逻辑。比如菜单树这种数据。
不管是数据异构还是加缓存,都有可能产生数据不一致问题,而MySQL 与Redis如何保持数据一致可以参考之前写的这篇MySQL与Redis缓存一致性的实现与挑战。
除了上述的数据方面进行优化外,还可以对代码进行业务逻辑的重构,或者说是在代码层面进行优化。常用的方式有异步、避免大事务、减小锁粒度等。
4.异步
异步的方式有很多,使用@Async注解,线程池或者MQ都可以实现异步。我们关注的重点是哪些业务可以使用异步处理,在业务逻辑处理中,保留核心业务逻辑,非核心业务逻辑异步处理。

在上面这个接口逻辑中,可以发现除了核心业务外,远程调用,记录日志都可以放入到异步线程中执行,这样就无需主线程等待。不过对于远程调用有的需要返回结果,核心业务需要返回结果支持的另说,这些细节需要好好设计一番了。
5.避免大事务
在使用 @Transaction 注解时,需要注意避免在类上使用该注解,在方法上使用该注解时也要注意方法逻辑不要过于复杂。
大事务可能引发问题如下:
- 死锁。
- 接口超时。
- 并发情况下数据库连接池资源耗尽。
- 回滚时间长。
为了避免大事务的产生,在开发时可以注意以下几点。
- select 查询方法拿到事务外。
- 避免在事务中进行远程调用。
- 事务中避免一次处理太多数据,可以拆分为多个小事务。
- 个别功能可以异步处理或者非事务运行。
6.减小锁粒度
有的场景中,需要进行加锁操作,防止多线程并发修改,造成数据异常。
但是锁要是加的不好,还不如不加,如果锁的粒度太粗,非常影响接口性能。
(1) synchronized
Java 中的关键字加锁,可以写在方法上或者代码块上,举个例子讲一下如何减小锁粒度。
public synchronized saveFile(String filePath) {
mkdir(filePath);
uploadFile(filePath);
saveMessage(filePath);
}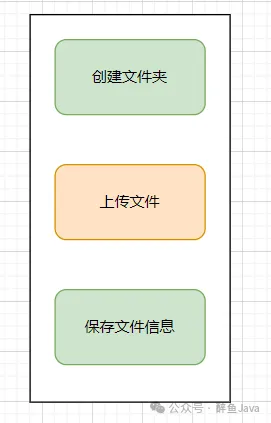
这里加锁是为了防止多次触发创建文件报错,影响业务。
上传文件的操作中,随着文件越来越大,耗费的时间也越长。(此处分片上传不考虑)
这三个过程放入一个方法中,当前锁定的就是这三个操作。
所以我们修改一下代码。
public void saveFile(String filePath) {
synchronized(this) {
if(!exists(filePath)) {
mkdir(filePath);
}
}
uploadFile(filePath);
saveMessage(filePath);
}修改之后锁定范围仅限于创建文件夹,对于上传文件这种耗时的操作将不再持有锁,提升接口性能。
(2) Redis 分布式锁
使用 Redis 实现分布式锁与 Synchronized 类似,在编写代码时尽量控制锁的范围,锁的粒度越小越好。
Redis 实现分布式锁虽说好用,但是还有8个坑,如果你还不知道可以看下之前写的这篇文章。
(3) 数据库锁
MySQL 为例,锁有表锁、行锁之分,这里主要说这两种锁。
表锁:加锁快,锁的粒度最大,发生冲突的概率最高,并发度最低。
行锁:加锁慢,会出现死锁现象,但是锁的粒度小,发生锁冲突的概率低,并发度也是最高的。
所以在数据库锁的优化方向上,优先行锁,其次表锁。
有的同学可能会说还有间隙锁等等,那些本文就不再多说了,大部分场景下使用行锁,尽量不使用表锁即可。
四、总结
在本文中,我们深入探讨了接口性能优化的多种策略,从技术细节到实践应用,讲解了接口优化的9种方式:
- 加索引。
- 禁止嵌套for循环。
- 分库分表。
- 数据异构。
- 缓存。
- 异步。
- 避免大事务。
- 减小锁粒度。
- 优化SQL。
通过这些优化措施,我们可以显著提高接口的响应速度和系统的整体性能,为用户提供更流畅的体验。