译者 | 朱先忠
审校 | 重楼
本文将通过一个最小但功能强大的实例教程,引导你进入异步机器学习推理开发领域。
简介
大多数机器学习服务教程都专注于实时同步服务的介绍,这允许对预测请求做出即时响应。然而,这种方法可能难以应对流量激增,对于长时间运行的任务来说并不理想。因此,类似于这样的任务还需要更强大的机器来快速响应;否则,一旦客户端或服务器发生故障,预测结果通常会丢失。
在本文中,我们将演示如何使用分布式任务调度框架Celery和开源分布式键值对数据库Redis作为异步工作线程来运行机器学习模型。试验中,我们将使用微软开源的统一视觉基础模型Florence 2,这是一种以其令人印象深刻的性能而闻名的视觉语言模型。本教程将提供一个最小但功能强大的示例;当然,您可以根据自己的实战场景进一步进行调整和扩展。
您可以在下面链接处查看该应用程序的演示:
https://coral-app-qdy8z.ondigitalocean.app/
总体来看,我们提供的解决方案的核心基于Celery框架,这是一个支持我们实现客户端/工作线程逻辑的Python库。它允许我们将计算工作分配给许多工作线程,从而提高机器学习推理应用场景对高负载和不可预测负载的可扩展性。
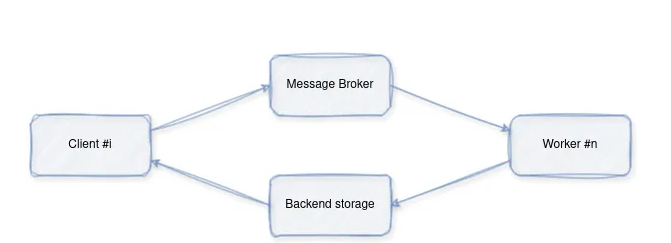
总体运行流程如下:
- 客户端向代理管理的队列(在我们的示例中为Redis)提交一个带有一些参数的任务。
- 由一个(或多个工作线程)持续监控队列,并在任务到来时接收任务。然后,它执行它们并将结果保存在后端存储中。
- 客户端可以通过轮询后端或订阅任务的通道,使用其id获取任务的结果。
简化实例
让我们从一个简化的例子开始:
图片由作者本人提供
首先,通过如下命令运行Redis:
下面给出的是工作线程代码:
相应的客户端代码如下:
运行上面代码,将给出了我们期望的结果:“Result: 10”。
实战案例
下面,我们继续讨论构建一个真正的基于Florence 2模型服务的实用型案例。
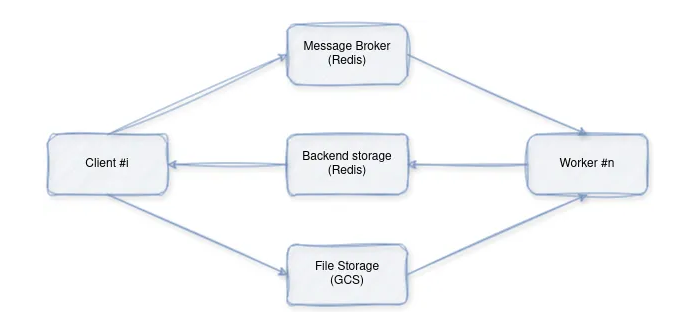
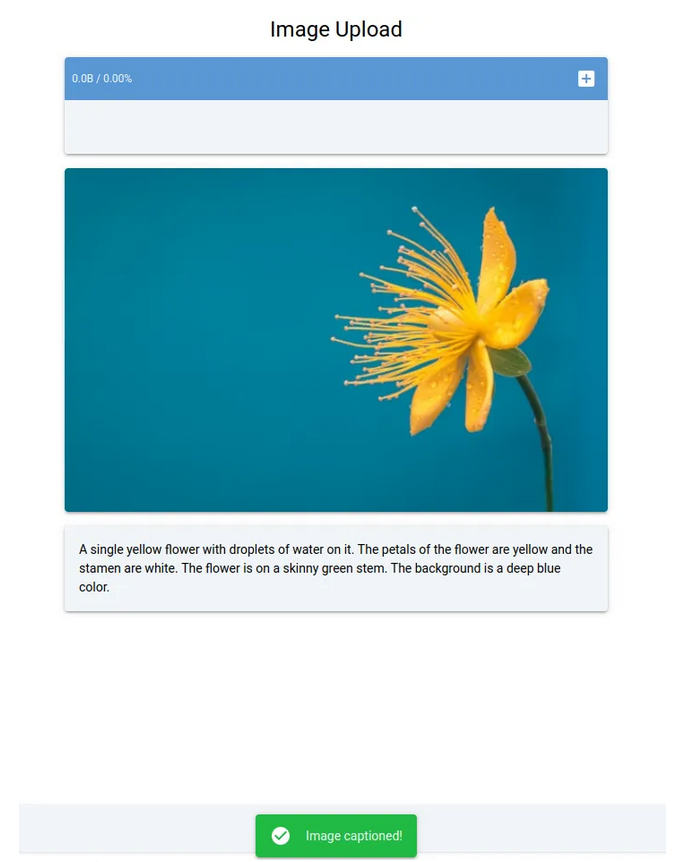
具体地说,我们将构建一个多容器图像字幕应用程序,该应用程序使用Redis进行任务排队,使用Celery进行任务分发,并使用本地卷或谷歌云存储实现潜在的图像存储。该应用程序的设计包含几个核心组件:模型推理、任务分配、客户端交互和文件存储。
架构概述
图片由作者本人提供
各组件分工如下:
- 客户端(Client):通过将图像字幕请求发送给工作线程(通过代理)来发起图像字幕请求。
- 工作线程(Worker):接收请求,下载图像,使用预训练的模型进行推理,并返回结果。
- 分布式键值对数据库Redis:充当消息代理,促进客户端和工作线程之间的通信。
- 文件存储:图像文件的临时存储。
接下来,我们进行各组件功能的更具体的剖析。
1.模型推理(Model.py)
首先,实现依赖关系和初始化:
上面代码完成的任务如下:
- 导入图像处理、Web请求、谷歌云存储交互和日志记录所需的库。
- 初始化预训练的Florence-2模型和处理器以生成图像字幕。
然后,进行图像下载(Download_Image):
归纳一下的话,上面代码完成的任务如下:
- 从提供的URL下载图像。
- 支持HTTP/HTTPS URL、谷歌云存储路径(gs://)和本地文件路径。
接下来,执行推理(run_Inference):
上面代码实现了编排图像字幕的过程,具体实现如下:
- 使用download_image下载图像。
- 为模型准备图像和任务提示。
- 使用加载的Florence-2模型生成字幕。
- 对生成的字幕进行解码和后处理。
- 返回最终字幕。
2.任务分配(worker.py)
首先,进行Celery设置:
这段代码完成的任务是:将Celery设置为使用Redis作为任务分发的消息代理。
接下来,定义任务(inference_task):
启动一个监听并执行任务的Celery工作线程。
3.客户端交互(Client.py)
首先,实现Celery连接:
使用Redis作为消息代理建立与Celery的连接。
接下来,进行任务提交(send_inference_Task):
上述代码完成了两项任务:
- 向Celery工作线程发送图像字幕任务(推理任务)。
- 等待工作线程完成任务并检索结果。
再接下来,实现Docker集成(Docker compose.yml)。
这一步主要是使用Docker Compose定义多容器设置:
- redis:运行redis服务器进行消息代理。
- model:构建和部署模型推理工作线程。
- app:构建和部署客户端应用程序。
此处花朵图片由RoonZ nl在Unsplash(https://unsplash.com/photos/yellow-and-blue-petaled-flower-vjDbHCjHlEY?utm_cnotallow=creditCopyText&utm_medium=referral&utm_source=unsplash)上提供
- flower:运行一个基于Web的Celery任务监控工具。
图片由作者本人提供
其实,您可以使用以下一句命令运行上面完整的栈操作:
小结
至此,整个任务完成!归纳一下,我们刚刚探索了使用Celery、Redis和Florence 2构建异步机器学习推理系统的全过程。具体地说,本文演示了如何有效地使用Celery进行任务分配,使用Redis进行消息代理,使用Florence 2模型进行图像字幕处理。通过采用异步工作流方案,您可以处理大量请求,提高性能,并增强ML推理应用程序的整体弹性。最后,我们提供的Docker Compose设置允许您使用单个命令来自行运行整个系统。
准备好下一步操作了吗?将本文介绍的这种架构部署到云端可能会遇到一系列挑战。
项目源码地址:https://github.com/CVxTz/celery_ml_deploy
项目演示地址: https://coral-app-qdy8z.ondigitalocean.app/
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Asynchronous Machine Learning Inference with Celery, Redis, and Florence 2,作者:Youness Mansar
链接:https://towardsdatascience.com/asynchronous-machine-learning-inference-with-celery-redis-and-florence-2-be18ebc0fbab。