译者 | 李睿
审校 | 重楼
BERT通过使用其双向方法帮助机器理解人类语言的场景,从而增强NLP的性能。本文探讨BERT如何实现这一目标。
大型语言模型(LLM)对人类语言的理解和处理起到了重要的催化作用。自然学习处理(NLP)弥合了人类与机器之间的沟通鸿沟,带来了无缝的客户体验。
NLP对于解释具有直接意图的简单语言非常有用。但是,当涉及到解释由同音异义词、同义词、反义词、讽刺等引起的文本歧义时,它还有很长的路要走。
“来自Transformers的双向编码器表示”(BERT)通过帮助NLP理解给定句子中每个单词的场景和含义,在增强NLP性能方面发挥了关键作用。
以下理解BERT的工作原理及其在NLP中的重要作用。
一、理解BERT
BERT是谷歌公司为NLP开发的开源机器学习框架。它通过使用双向方法为给定文本提供适当的场景来增强NLP。它从文本的两端(即前面和后面)的单词进行分析。
BERT的双向方法帮助它产生精确的单词表示。通过生成单词、短语和句子的深度场景表示,BERT提高了NLP在各种任务中的表现。
二、BERT的工作原理
BERT的卓越性能可归功于其基于Transformers的架构。Transformers是一种神经网络模型,在处理顺序数据(例如语言处理)的任务中表现得非常好。
BERT采用多层双向Transformer编码器对单词进行串联处理。Transformer可以捕捉句子中的复杂关系,以理解语言的细微差别。它还能捕捉到意义上的细微差异,这些差异会显著改变句子的场景。这与NLP相反,NLP利用单向方法预测序列中的下一个单词,可能阻碍场景学习。
BERT的主要目标是生成语言模型,因此它只使用编码器机制。令牌按顺序送入Transformers编码器。它们首先被嵌入到向量中,然后在神经网络中进行处理。生成一系列向量,每个向量对应一个输入令牌,提供场景化表示。BERT部署了两种训练策略来解决这个问题:掩模语言模型(MLM)和下句预测(NSP)。
掩码语言模型(MLM)
这种方法包括屏蔽每个输入序列中单词的某些部分。该模型接受训练,根据周围单词提供的场景来预测被屏蔽单词的原始值。
为了更好地理解这一点,看下这个例子:
“我在喝苏打水。”(I am drinking soda)
在上面的句子中,如果把“喝”这个词去掉,还可以使用哪些其他恰当的单词?其他可以用的单词还有“啜饮、分享、吮吸等”,但不能用“吃”、“切”等随意的单词。
因此,大型语言模型必须了解语言结构以选择正确的单词。为模型提供模型输入,其中包含一个空白的单词或以及应该存在的单词。这个过程通过获取文本并遍历它来创建数据。
下句预测(NSP)
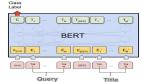
这个过程训练一个模型来确定第二个句子是否符合第一个句子的含义。BERT预测第二个句子是否与第一个句子相连。这是通过使用分类层将[CLS]令牌的输出转换为2 x 1形状的向量来实现的。
第二句出现在第一句之后的概率是通过SoftMax计算出来的。本质上,BERT模型包括将上述两种方法一起训练。这产生了一个健壮的语言模型,具有增强的功能,可以理解句子中的场景及其之间的关系。
三、BERT在NLP中的作用
 BERT如何增强NLP的性能-AI.x社区
BERT如何增强NLP的性能-AI.x社区
BERT在NLP中起着不可缺少的作用。它在各种NLP任务中的作用概述如下:
文本分类
文本分类用于情感分析,将文本分为积极、消极和中性。这里可以通过在Transformers输出上添加一个分类层来使用BERT,即[CLS]令牌。这个令牌表示从整个输入序列中收集的信息。然后,它可以用作分类层的输入,以预测特定的任务。
问题回答
它可以通过获取关于标记答案开始和结束的两个额外向量的知识进行训练来回答问题。BERT通过问题和附带的段落进行训练,使其能够预测给定段落中答案的开始和结束位置。
命名实体识别(NER)
使用文本序列来识别和分类实体,例如人员、公司、日期等。通过从Transformer中获取每个令牌的输出向量来训练NER模型,然后将其输入分类层。
语言翻译
用来翻译语言,关键语言输入和相关的翻译输出可用于训练模型。
谷歌智能搜索
BERT利用一个Transformer同时研究多个令牌和句子,使谷歌引擎能够识别搜索文本并产生相关结果的目标。
文本摘要
BERT为抽取和抽象模型推广了一个流行的框架。前者通过识别文档中最重要的句子来创建摘要。相比之下,后者使用新句子来创建摘要,这包括重新措辞或使用新词,而不仅仅是提取关键句子。
四、BERT NLP模型的优缺点
作为一个大型语言模型,BERT有其优点和缺点。为了清楚起见,需要参考以下几点:
优点
- BERT的多种语言训练使其非常适合用于英语以外的项目。
- 对于特定于任务的模型来说,这是一个很好的选择。
- 由于BERT是用大量的数据库进行训练的,因此它很容易用于小型、定义明确的任务。
- BERT可在微调之后立即使用。
- 频繁更新,准确性高。
缺点
- BERT规模巨大,因为它接受了大量数据的训练,这影响了它如何预测和从数据中学习。
- 考虑到它的大小,其成本高昂,需要更多的计算。
- BERT对下游任务进行了微调,这些任务往往比较繁琐。
- 训练BERT很耗时,因为它有很多权重,需要更新。
- BERT在训练数据中容易出现偏差,人们需要意识到并努力克服这些偏差,以创建具有包容性和道德性的人工智能系统。
五、BERT NLP模型的未来趋势
目前开发人员正在进行研究,以解决NLP中的挑战,例如稳健性、可解释性和伦理考虑。零样本学习、少样本学习和常识推理的进展将用于开发智能学习模型。
这些都有望推动NLP的创新,并为开发更智能的语言模型铺平道路。这些版本将有助于解锁洞察力,并加强专业领域的决策。
将BERT与人工智能和机器学习技术(如计算机视觉和强化学习)相结合,必将带来一个创新和可能性的新时代。
结论
随着BERT的不断发展,先进的NLP模型和技术正在出现。BERT将通过增强人工智能理解和处理语言的能力,让人工智能的未来发展具有更广阔的前景。BERT的潜力远远超越了普通的NLP任务。
BERT模型正在为医疗保健、金融和法律开发专门的或特定于领域的模型版本,实现了对语言的场景理解。它是NLP的一个重要里程碑,在文本分类、命名实体识别和情感分析等多种任务上取得了突破。
原文标题:How BERT Enhances the Features of NLP,作者:Matthew McMullen
链接:https://dzone.com/articles/how-bert-enhances-the-features-of-nlp。