还记得这些天大模型被揪出来的低级错误吗?
不知道 9.11 和 9.9 哪个大,数不清 Strawberry 单词里面有多少个 r…… 每每被发现一个弱点,大模型都只能接受人们的无情嘲笑。

嘲笑之后,大家也冷静了下来,开始思考:低级错误背后的本质是什么?
大家普遍认为,是 Token 化(Tokenization)的锅。
在国内,Tokenization 经常被翻译成「分词」。这个翻译有一定的误导性,因为 Tokenization 里的 token 指的未必是词,也可以是标点符号、数字或者某个单词的一部分。比如,在 OpenAI 提供的一个工具中,我们可以看到,Strawberry 这个单词就被分为了 Str-aw-berry 三个 token。在这种情况下,你让 AI 大模型数单词里有几个 r,属实是为难它。
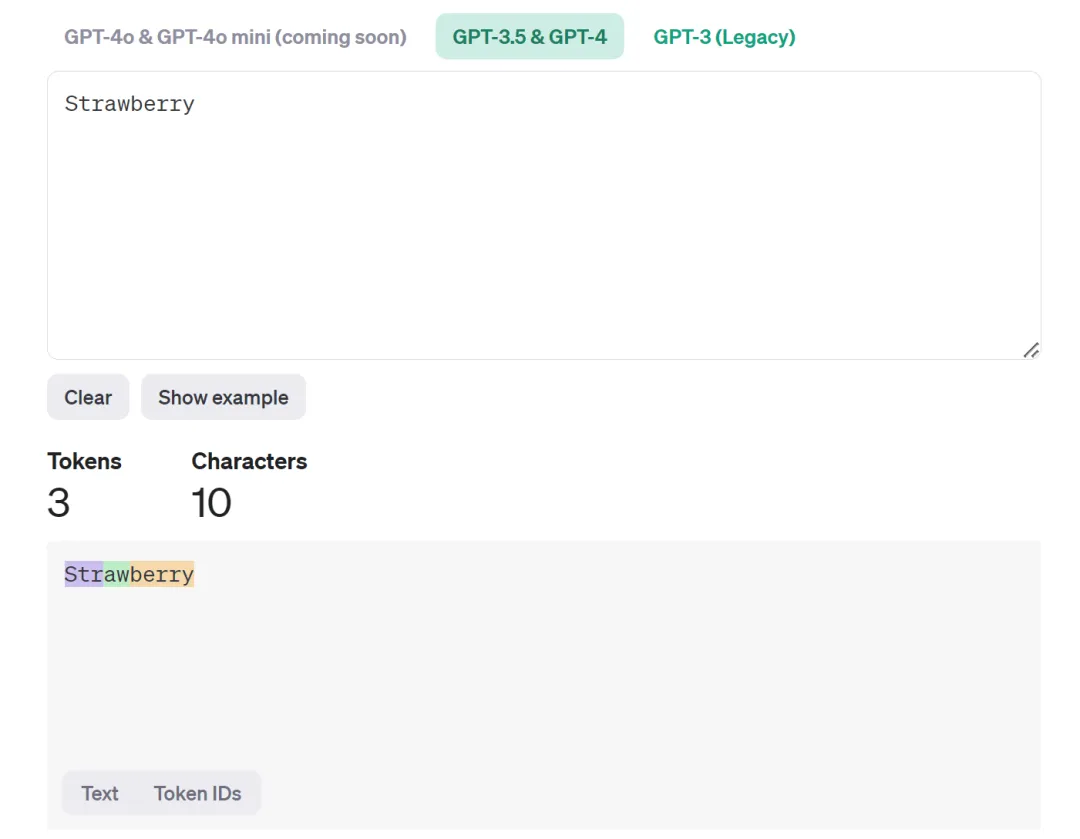
除了草莓 (Strawberry) 之外,还有一个很好的例子就是「Schoolbooks」这个词,AI 模型会把它分为 school 和 books 两个 token。


这个问题也吸引了刚刚投身 AI + 教育行业的 Karpathy 的注意。为了让大家直观地看到大模型眼里的文字世界,他特地写了一个小程序,用表情符号(emoji)来表示 token。

按照小程序被设计的表示方法,「How many letters 'r' in the word'strawberry'?」在 LLM 看来是这样的:

一段文本在 LLM 看来会是这样:

但这种解释也引起了另一种疑问:如果你让大模型把 Strawberry 这个词的每个字母都列出来,然后删掉 r 以外的字母,大模型就能数对了,那大模型为什么自己不这么做呢?它好像不太会利用自己的能力。


对此,Karpathy 给出的回复是「因为没有人教它这么做」。

其实,如果你在 Prompt 里加上「think step by step」等思维链相关「咒语」,大模型是可以分步骤解决问题的,而且很有可能数对「r」的数量。那它之前不假思索就给出答案,是不是因为过度自信?

对此,有人猜测说,大模型公司给 LLM 的设定可能就是让它在一个问题上花费尽可能少的时间,因此,除非你明确要求,不然它不会主动去深入思考。

对于这种说法,我们也测试了一下。结果发现,如果明确要求深入思考,模型确实立马就会数了:

这就类似于它有两套系统:快速、依靠直觉的系统 1 和较慢、较具计划性且更仰赖逻辑的系统 2,平时默认使用系统 1。

当然,这些只是猜测。
综合最近的新闻来看,我们会发现一个有意思的现象:一方面,大模型都能在人类奥数中拿银牌了;而另一方面,它们又在数数、比大小方面集体翻车。类似的例子还有不会玩几岁小孩都会玩的井字棋,不会判断两个圆是否重叠等。

Karpathy 给这种现象取了个名字 ——Jagged Intelligence(Jagged 的意思是参差不齐的)。这种参差不齐的智能表现和人类是不一样的,人类的知识体系和解决问题的能力在成长过程中是高度相关的,并且是同步线性发展的,而不是在某些领域突然大幅度提升,而在其他领域却停滞不前。
Karpathy 认为,这一问题的核心在于目前的大模型缺乏「认知自我知识(cognitive self-knowledge)」( 模型自身对其知识和能力的自我认知 )。如果模型具备这种能力,它可能会在面对「数字母」这样的问题时回答说,「我不太擅长数字母,让我使用代码解释器来解决这个问题」。

这一问题的解决方案可能包括但不限于扩大规模,可能需要在整个技术栈的各个方面都做一些工作,比如在后训练阶段采用更复杂的方法。
对此,Karpathy 推荐阅读 Llama 3 论文的 4.3.6 章节。在此章节中,Meta 的研究者提出了一些方法来让模型「只回答它知道的问题」。

该章节写到:
我们遵循的原则是,后训练应使模型「知道它知道什么」,而不是增加知识。我们的主要方法是生成数据,使模型生成与预训练数据中的事实数据子集保持一致。为此,我们开发了一种知识探测技术,利用 Llama 3 的 in-context 能力。数据生成过程包括以下步骤:
1、从预训练数据中提取数据片段。
2、通过提示 Llama 3 生成一个关于这些片段(上下文)的事实问题。
3、采样 Llama 3 关于该问题的回答。
4、以原始上下文为参照,以 Llama 3 为裁判,评估生成的回答的正确性。
5、以 Llama 3 为裁判,评估生成回答的信息量。
6、对于 Llama 3 模型在多个生成过程中提供的信息虽多但内容不正确的回答,使用 Llama 3 生成拒绝回答的内容。
我们使用知识探测生成的数据来鼓励模型只回答它知道的问题,而拒绝回答它不确定的问题。此外,预训练数据并不总是与事实一致或正确。因此,我们还收集了一组有限的标注事实性数据,这些数据涉及与事实相矛盾或不正确的陈述。
最后,Karpathy 表示,这种参差不齐的智能问题值得注意,尤其是在生产环境中。我们应该致力于让模型只完成他们擅长的任务,不擅长的任务由人类及时接手。