












出品 | 51CTO技术栈(微信号:blog51cto)
Llama 3.1 405B被吐槽太笨重?
英伟达对手AI新星Groq一招绝杀:上LPU直接速度翻倍,直接让Llama 3.1飞升AGI!
Meta 最新发布的 Llama 3.1 405B 的开源让AI圈不平静了!
追捧者感慨"GPT-4o的能力已握在手中”,而批评者反驳说,大体量消耗这么多算力,有些结果跑得还不如GPT-4o mini,太失望了!
不过, Meta与英伟达劲敌Groq 的联手直接让速度问题从此消失了!
Groq 利用自己的超级速度向社区提供最新的 Llama 3.1 模型,包括 405B Instruct、70B Instruct 和 8B Instruct。
网友试完后惊讶地说:我的天啊,@GroqInc + @AIatMeta Llama 3.1 405b,我们问出的问题获得了实时的答案,真的做到了!!!
 图片
图片
看了这个视频展示,不得不感叹Groq + Llama 3.1的速度太猛了!
小扎对这场令人惊叹的合作表示,“真的很高兴看到 Groq 为 Llama 3.1 模型的云部署提供超低延迟推理......通过向社区提供我们的模型和工具,Groq 这样的公司可以在我们的工作基础上再接再厉,帮助推动整个生态系统向前发展"。
Groq首席执行官乔纳森-罗斯(Jonathan Ross)说:"Meta正在为人工智能开发一个类似于Linux的开放操作系统——不仅仅是为提供快速人工智能推理的Groq LPU,而是为整个生态系统。”
他补充说,Meta已经赶上了领先的专有模型,超越闭源模型只是时间问题。
前OpenAI研究员、AI大佬Andrej Karpathy称赞Groq的推理速度说:"这太酷了。这感觉就像 AGI——你只需与电脑对话,它就能立即完成任务。
 图片
图片
在过去的几个月里,Groq 以其比竞争对手更快、更经济高效地执行人工智能任务的承诺而备受关注。这要归功于它的语言处理单元(LPU),由于其线性操作,在执行这些任务时比 GPU 更有效率。虽然 GPU 对模型训练至关重要,但部署中的人工智能应用(称为 "推理")需要更高的效率和更低的延迟。
由于试玩者的热情涌入,GroqCloud 负责人Sunny Madra在X上宣布Llama 3.1 405b体验暂时关闭了。
他写道,看到 Groq 上对 Llama 3.1 的需求和兴奋程度令人难以置信!我们被公众对 405b 的需求所淹没,很抱歉你们中的许多人经历了漫长的排队时间。我们将暂时关闭405b,直到我们能够增加容量并确保增加容量并提供更高水平的服务。
 图片
图片
1.速度称王:Groq+ Llama 3-70B是GPT-4o mini两倍快
"Groq的速度快得惊人,目前每秒可处理1200多个令牌。”
Groq甚至开源了一款快如闪电的炒股机器人。
Groq的人工智能应用工程师 Benjamin Klieger 介绍说:"StockBot——一个由 Groq 上的 Llama 3-70B 支持的快如闪电的开源人工智能聊天机器人,可提供实时股票图表、财务信息、新闻和筛选器。
 图片
图片
StockBot运行起来的速度是这样的:
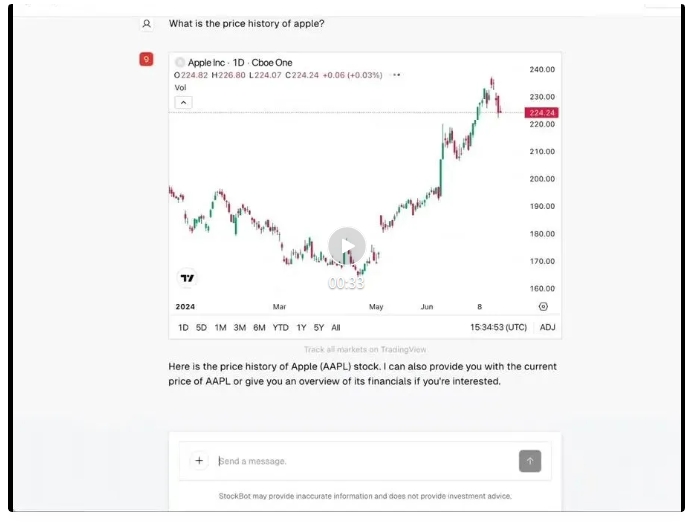
根据 Artificial Analysis 的报告,在比较不同供应商提供的Llama 3 70B(一种人工智能模型)的性能时,GPT-4o Mini的速度明显快于大多数供应商。然而,Groq公司提供的Llama 70B模型,每秒能输出约340个输出令牌(tokens),这比GPT-4o Mini快了两倍多。
 图片
图片
Groq 项目负责人 Rick Lamers 最近发布了 8B 和 70B 版本的 Llama 3 Groq Tool Use 型号。
 图片
图片
他在 X 上分享说,这些模型是开源的,并针对工具使用进行了全面微调,在 BFCL 基准测试中名列前茅,超越了所有其他模型,包括 Claude Sonnet 3、GPT-4 Turbo、GPT-4o 和 Gemini 1.5 等专有模型。5、GPT-4 Turbo、GPT-4o 和 Gemini 1.5 Pro 等专有型号。
 图片
图片
感兴趣的朋友可以移步抱抱脸:
https://huggingface.co/Groq/Llama-3-Groq-8B-Tool-Use
自推出以来的 16 周内,Groq 免费提供了为 LLM 工作负载提供支持的服务,因此得到了开发人员的广泛欢迎,据 Ross 称,目前已有超过 28.2 万名开发人员。
"Groq的使用非常简单,而且不需要任何费用。你只需使用我们的应用程序接口(API),我们与大多数已开发的应用程序都兼容,"罗斯说。他补充说,如果客户有大规模需求,每秒要生成数百万个令牌,公司可以为客户部署内部硬件。
2.抛弃GPU,Groq神秘的LPU——不仅快还省电
Groq由罗斯于2016年创立,其与众不同之处在于摒弃了GPU,转而使用其专有硬件LPU。
在加入Groq之前,罗斯曾在谷歌工作,创建了张量处理单元(TPU)。他负责设计和实现原始 TPU 芯片的核心元件,该芯片在谷歌的人工智能工作(包括 AlphaGo 竞赛)中发挥了关键作用。
LPU 仅用于运行 LLM,而不是训练它们。罗斯说:"在推理或实际运行模型时,LPU的速度大约是GPU的10倍,"他补充说,在训练LLM时,那是GPU的任务。
当被问及这种速度的目的时,罗斯说:"人类不喜欢这样阅读,就像老式电传打字机打印出来的东西一样。眼睛扫描页面的速度非常快,几乎在一瞬间就能判断出是否得到了想要的东西。"
Groq 的 LPU 对英伟达、AMD 和英特尔等传统 GPU 制造商构成了巨大挑战。Groq专门为加速深度学习计算而打造了张量流处理器,而不是为人工智能修改通用处理器。
LPU旨在克服两个LLM瓶颈:计算密度和内存带宽。就 LLM 而言,LPU 的计算能力大于 GPU 和 CPU。这就减少了每个单词的计算时间,从而可以更快地生成文本序列。
此外,由于消除了外部内存瓶颈,LPU 推理引擎在 LLM 上的性能比 GPU 高出数个数量级。LPU 的设计优先考虑数据的顺序处理,这是语言任务所固有的。这与 GPU 形成鲜明对比,后者针对图形渲染等并行处理任务进行了优化。"
Ross说:"在生成第99个字之前,你无法生成第100个字,因此它们有一个顺序部分,而GPU根本无法做到这一点。
此外,他还补充说,GPU是出了名的耗电大户,每个芯片所需的电量往往相当于普通家庭的电量。"他说:"LPU 的耗电量仅为 GPU 的十分之一。
参考链接: https://analyticsindiamag.com/ai-origins-evolution/groq-makes-llama-3-1-agi/






























