近日,来自清华大学智能产业研究院(AIR)助理教授赵昊老师的团队,联合戴姆勒公司,提出了一种无需训练的多域感知模型融合新方法。研究重点关注场景理解模型的多目标域自适应,并提出了一个挑战性的问题:如何在无需训练数据的条件下,合并在不同域上独立训练的模型实现跨领域的感知能力?团队给出了“Merging Parameters + Merging Buffers”的解决方案,这一方法简单有效,在无须访问训练数据的条件下,能够实现与多目标域数据混合训练相当的结果。

论文题目:
Training-Free Model Merging for Multi-target Domain Adaptation
作者:Wenyi Li, Huan-ang Gao, Mingju Gao, Beiwen Tian, Rong Zhi, Hao Zhao
1 背景介绍
一个适用于世界各地自动驾驶场景的感知模型,需要能够在各个领域(比如不同时间、天气和城市)中都输出可靠的结果。然而,典型的监督学习方法严重依赖于需要大量人力标注的像素级注释,这严重阻碍了这些场景的可扩展性。因此,多目标域自适应(Multi-target Domain Adaptation, MTDA)的研究变得越来越重要。多目标域自适应通过设计某种策略,在训练期间同时利用来自多个目标域的无标签数据以及源域的有标签合成数据,来增强这些模型在不同目标域上的鲁棒性。
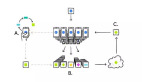
与传统的单目标域自适应 (Single-target Domain Adaptation, STDA)相比,MTDA 面临更大的挑战——一个模型需要在多个目标域中都能很好工作。为了解决这个问题,以前的方法采用了各种专家模型之间的一致性学习和在线知识蒸馏来构建各目标域通用的学生模型。尽管如此,这些方法的一个重大限制是它们需要同时使用所有目标数据,如图1(b) 所示。
但是,同时访问到所有目标数据是不切实际的。一方面原因是数据传输成本限制,因为包含数千张图像的数据集可能会达到数百 GB。另一方面,从数据隐私保护的角度出发,不同地域间自动驾驶街景数据的共享或传输可能会受到限制。面对这些挑战,在本文中,我们聚焦于一个全新的问题,如图1(c) 所示。我们的研究任务仍然是MTDA,但我们并没有来自多个目标域的数据,而是只能获得各自独立训练的模型。我们的目标是,通过某种融合方式,将这些模型集成为一个能够适用于各个目标域的模型。
 图1:不同实验设置的对比
图1:不同实验设置的对比
2 方法
如何将多个模型合并为一个,同时保留它们在各自领域的能力?我们提出的解决方案主要包括两部分:Merging Parameters(即可学习层的weight和bias)和 Merging Buffers(即normalization layers的参数)。在第一阶段,我们从针对不同单目标域的无监督域自适应模型中,得到训练后的感知模型。然后,在第二阶段,利用我们提出的方法,在无须获取任何训练数据的条件下,只对模型做合并,得到一个在多目标域都能工作的感知模型。
 图2:整体实验流程
图2:整体实验流程
下面,我们将详细介绍这两种合并的技术细节和研究动机。
2.1 Merging Parameters
2.1.1 Permutation-based的方法出现退化
事实上,如何将模型之间可学习层的 weight 和 bias 合并一直是一个前沿研究领域。在之前的工作中,有一种称为基于置换 (Permutation-based) 的方法。这些方法基于这样的假设:当考虑神经网络隐藏层的所有潜在排列对称性时,loss landscape 通常形成单个盆地(single basin)。因此,在合并模型参数 和时,这类方法的主要目标是找到一组置换变换 ,确保 在功能上等同于 ,同时也位于参考模型 附近的近似凸盆地(convex basin)内。之后,通过简单的中点合并 以获得一个合并后的模型 ,该模型能够表现出比单个模型更好的泛化能力,
在我们的实验中,模型 和 在第一阶段都使用相同的网络架构进行训练,并且,源数据都使用相同的合成图像和标签。我们最初尝试采用了一种 Permutation-based 的代表性方法——Git Re-Basin,该方法将寻找置换对称变换的问题转化为线性分配问题 (LAP),是目前最高效实用的算法。
 图3:Git Re-basin和mid-point的实验结果对比
图3:Git Re-basin和mid-point的实验结果对比
但是,如图3所示,我们的实验结果出乎意料地表明,不同网络架构(ResNet50、ResNet101 和 MiT-B5)下 Git Re-Basin 的性能与简单中点合并相同。进一步的研究表明,Git Re-Basin 发现的排列变换在解决 LAP 的迭代中保持相同的排列,这表明在我们的领域适应场景下,Git Re-Basin 退化为一种简单的中点合并方法。
2.1.2 线性模式连通性的分析
我们从线性模式连通性(linear mode connectivity)的视角进一步研究上述退化问题。具体来说,我们使用连续曲线 在参数空间中连接模型 和模型 。在这种特定情况下,我们考虑如下线性路径,
接下来,我们通过对 做插值遍历评估模型的性能。为了衡量这些模型在两个指定目标域(分别表示为 和 )上的有效性,我们使用调和平均值 (Harmonic Mean) 作为主要评估指标,
我们之所以选择调和平均值作为指标,是因为它能够赋予较小的值更大的权重,这能够更好应对世界各地各个城市中最差的情况。它有效地惩罚了模型在一个目标域(例如,在发达的大城市)的表现异常高,而其他目标域(例如,在第三世界乡村)表现低的情况。不同插值的实验结果如图4(a)所示。“CS”和“IDD”分别表示目标数据集 Cityscapes 和 Indian Driving Dataset。
 图4:线性模式连通性的分析实验
图4:线性模式连通性的分析实验
2.1.3 理解线性模式连通性的原因
在上述实验结果的基础上,我们进一步探究:在先前域自适应方法中观察到的线性模式连通性,背后的根本原因是什么?为此,我们进行了消融实验,来研究第一阶段训练 和 期间的几个影响因素。
- 合成数据。使用相同的合成数据可以作为两个域之间的桥梁。为了评估这一点,我们将合成数据集 GTA 中的训练数据划分为两个不同的非重叠子集,每个子子集包含原始训练样本的 30%。在划分过程中,我们将合成数据集提供的具有相同场景标识的图像分组到同一个子集中,而具有显着差异的场景则放在单独的子集中。我们使用这两个不同子集分别作为源域,训练两个单目标域自适应模型(目标域为 CityScapes 数据集)。随后,我们研究这两个 STDA 模型的线性模式连通性。结果如图 4(b) 所示,可以观察到,在参数空间内连接两个模型的线性曲线上,性能没有明显下降。这一观察结果表明,使用相同的合成数据并不是影响线性模式连通性的主要因素。
- 自训练架构。使用教师-学生模型可能会将最后的模型限制在 loss landscape 的同一 basin 中。为了评估这种可能性,我们禁用了教师模型的指数移动平均 (EMA) 更新。相应地,我们在每次迭代中将学生权重直接复制到教师模型中。随后,我们继续训练两个单目标域自适应模型,分别利用 GTA 作为源域,Cityscapes 和 IDD 作为目标域。然后,我们研究在参数空间内连接两个模型的线性曲线,结果如图 4(c) 所示。我们可以看到线性模式连接属性保持不变。
- 初始化和预训练。 使用相同的预训练权重初始化 backbone 的做法,可能会使模型在训练过程中难以摆脱的某一 basin。为了验证这种潜在情况,我们初始化两个具有不同权重的独立 backbone,然后继续针对 Cityscapes 和 IDD 进行域自适应。在评估两个收敛模型之间的线性插值模型时,我们观察到性能明显下降,如图 4(d) 所示。为了更深入地了解潜在因素,我们继续探究,是相同的初始权重,还是预训练过程导致了这种影响? 我们初始化两个具有相同权重但没有预训练的主干,然后再次进行实验。有趣的是,我们发现,在参数空间的线性连接曲线仍然遇到了巨大的性能障碍,如图 4(e) 所示。这意味着预训练过程在模型中的线性模式连接方面起着关键作用。
2.1.4 关于合并参数的小结
我们通过大量实验证明,当领域自适应模型从相同的预训练权重开始时,模型可以有效地过渡到不同的目标领域,同时仍然保持参数空间中的线性模式连通性。因此,这些训练模型可以通过简单的中点合并,得到在两个领域都有效的合并模型。
2.2 Merging Buffers
Buffers,即批量归一化 (BN) 层的均值和方差,与数据域密切相关。因为数据不同的方差和均值代表了域的某些特定特征。在合并模型时如何有效地合并 Buffers 的问题通常被忽视,因为现有方法主要探究如何合并在同一域内的不同子集上训练的两个模型。在这样的前提下,之前的合并方法不考虑 Buffers 是合理的,因为来自任何给定模型的 Buffers 都可以被视为对整个总体的无偏估计,尽管它完全来自随机数据子样本。
但是,在我们的实验环境中,我们正在研究如何合并在完全不同的目标域中训练的两个模型,这使得 Buffers 合并的问题不再简单。由于我们假设在模型 A 和模型 B 的合并阶段无法访问任何形式的训练数据,因此我们可用的信息仅限于 Buffers 集 。其中, 表示 BN 层的数量,而 、 和 分别表示第 层的平均值、标准差和 tracked 的批次数。生成 BN 层的统计数据如下:
以上方程背后的原理可以解释如下:引入 BN 层是为了缓解内部协变量偏移(internal covariate shift)问题,其中输入的均值和方差在通过内部可学习层时会发生变化。在这种情况下,我们的基本假设是,后续可学习层合并的 BN 层的输出遵循正态分布。由于生成的 BN 层保持符合高斯先验的输入归纳偏差,我们根据从 和 得到的结果估计 和 。如图5所示,我们获得了从该高斯先验中采样的两组数据点的均值和方差,以及这些集合的大小。我们利用这些值来估计该分布的参数。
 图5:合并BN层的示意图
图5:合并BN层的示意图
当将 Merging Buffers 方法扩展到 个高斯分布时,tracked 的批次数 、均值的加权平均值 和方差的加权平均值可以按如下方式计算。
3 实验与结果
3.1 数据集
在多目标域适应实验中,我们使用 GTA 和 SYNTHIA 作为合成数据集,并使用 Cityscapes 、Indian Driving Dataset 、ACDC 和 DarkZurich 的作为目标域真实数据集。在训练单个领域自适应模型时,使用带有标记的源域数据和无标记的目标域数据。接下来,我们采用所提出的模型融合技术,直接从训练好的模型出发构建混合模型,这个过程中无需使用训练数据。
3.2 与Baseline模型的比较
在实验中,我们将我们的模型融合方法在 MTDA 任务上的结果与几种 baseline 模型进行对比。baseline 模型包括数据组合(Data Comb.)方法,其中单个域自适应模型在来自两个目标域的混合数据上进行训练(这个baseline仅供参考,因为它们与我们关于数据传输带宽和数据隐私问题的设定相矛盾)。baseline 模型还包括单目标域自适应(STDA),即为单一目标域训练的自适应模型,评估其在两个域上的泛化能力。
 表1:与Baseline模型的比较
表1:与Baseline模型的比较
表 1 展示了基于 CNN 架构的 ResNet101和基于 Transformer 架构的 MiT-B5 的结果。与最好的单目标域自适应模型相比,当将我们的方法分别应用于 ResNet101 和 MiT-B5 两种不同 Backbone 时,在两个目标域上性能的调和平均值分别提高 +4.2% 和 +1.2%。值得注意的是,这种性能水平(ResNet101架构下的调和平均值为 56.3%)已经与数据组合(Data Comb.)方法(56.2%)相当,而且我们无需访问任何训练数据即可实现这一目标。
此外,我们探索了一种更为宽松的条件,其中仅合并 Encoder backbone,而 decoder head 则针对各个下游域进行分离。值得注意的是,这种条件下,分别使两种 backbone 下的调和平均性能显著提高 +5.6% 和 +2.5%。我们还发现,我们提出的方法在大多数类别中能够始终实现最佳调和平均,这表明它能够增强全局适应性,而不是偏向某些类别。
3.3 与SoTA模型的比较
我们首先将我们的方法与 GTACityscapes 任务上的单目标域自适应 (STDA) 进行比较,如表 2 所示。值得注意的是,我们的方法可以应用于任何这些方法,只要它们使用相同的预训练权重适应不同的域。这使我们能够使用单个模型推广到所有目标域,同时保持 STDA 方法相对优越的性能。
 表2:与SoTA模型的比较
表2:与SoTA模型的比较
我们还将我们的方法与表 2 中的域泛化(DG)方法进行了比较,域泛化旨在将在源域上训练的模型推广到多个看不见的目标域。我们的方法无需额外的技巧,只需利用参数空间的线性模式连接即可实现卓越的性能。在多目标域自适应领域,我们的方法也取得了领先。我们不需要对多个学生模型做显式的域间一致性正则化或知识提炼,但能使 STDA 方法中的技术(如多分辨率训练)能够轻松转移到 MTDA 任务。可以观察到,我们对 MTDA 任务的最佳结果做出了的显著改进,同时消除了对训练数据的依赖。
3.4 多目标域拓展
我们还扩展了我们的模型融合技术,以涵盖四个不同的目标领域:Cityscapes 、IDD 、ACDC 和 DarkZurich 。每个领域都面临着独特的挑战和特点:Cityscapes 主要关注欧洲城市环境,IDD 主要体现印度道路场景,ACDC 主要针对雾、雨或雪等恶劣天气条件,DarkZurich 则主要处理夜间道路场景。我们对针对每个领域单独训练后的模型,以及用我们的方法融合后的模型进行了全面评估。
 表3:在4个目标域上的实验结果
表3:在4个目标域上的实验结果
如表 3 所示,我们提出的模型融合技术表现出显著的性能提升。虽然我们将来自单独训练模型的调和平均值最高的方法作为比较的基线,但所有基于模型融合的方法都优于它,性能增长高达 +5.8%。此外,尽管合并来自多个不同领域模型的复杂性不断增加,但我们观察到所有领域的整体性能并没有明显下降。通过进一步分析,我们发现我们的方法能够简化领域一致性的复杂性。现有的域间一致性正则化和在线知识提炼方法的复杂度为 ,而我们的方法可以将其减少到更高效的 ,其中 表示考虑的目标域数量。
3.5 消融实验
我们使用 ResNet101 和 MiT-B5 作为分割网络中的图像编码器,对我们提出的 Merging Parameters 和 Merging Buffers 方法进行了消融研究,结果如表 4 所示。我们观察到单目标域自适应 (STDA) 模型在不同域中的泛化能力存在差异,这主要源于所用目标数据集的多样性和质量差异。尽管如此,我们还是选择 STDA 模型中的最高的调和平均值作为比较基线。
 表4:消融实验
表4:消融实验
表 4(a) 和 4(b) 中的数据显示,采用简单的中点合并方法对参数进行处理,可使模型的泛化能力提高 +2.7% 和 +0.6%。此外,当结合 Merging Buffers 时,这种性能的增强会进一步放大到 +4.2% 和+1.2%。我们还观察到 MiT-B5 作为 backbone 时的一个有趣现象:在 IDD 域中进行评估时,融合模型的表现优于单目标自适应模型。这一发现意味着模型可以从其他域获取域不变的知识。这些结果表明,我们提出的模型融合技术的每个部分都是有效的。
3.6 模型融合在分类任务上的应用
我们还通过实验验证了我们所提出的模型融合方法在图像分类任务上的有效性。通过将 CIFAR-100 分类数据集划分为两个不同的、不重叠的子集,我们在这些子集上独立训练两个 ResNet50 模型,标记为 A 和 B。这种训练要么从一组共同的预训练权重中进行,要么从两组随机初始化的权重中进行。模型 A 和 B 的性能结果如图 6 所示。结果表明,从相同的预训练权重进行融合的模型优于在任何单个子集上训练的模型。相反,当从随机初始化的权重开始时,单个模型表现出学习能力,而合并模型的性能类似于随机猜测。
 图6:CIFAR-100 分类任务上的模型融合结果
图6:CIFAR-100 分类任务上的模型融合结果
随机初始化会破坏模型线性平均性,而相同的预训练主干会导致线性模式连接。我们在另一个预训练权重上再次验证了这个结论。图 7 中的结果表明,DINO 预训练和 ImageNet 预训练在模型参数空间中具有不同的loss landscape,模型的融合必须在相同的loss landscape内进行。
 图7:ImageNet和DINO预训练权重对线性模式连接的影响
图7:ImageNet和DINO预训练权重对线性模式连接的影响
4 结论
本文介绍了一种新颖的模型融合策略,旨在解决多目标域自适应 (MTDA)问题,同时无需依赖训练数据。研究结果表明,在大量数据集上进行预训练时,基于 CNN 的神经网络和基于 Transformer 的视觉模型都可以将微调后模型限制在 loss landscape 的相同 basin 中。我们还强调了 Buffers 的合并在 MTDA 中的重要性,因为 Buffers 是捕获各个域独特特征的关键。我们所提出的模型融合方法简单而高效,在 MTDA 基准上取得了最好的评测性能。我们期待本文所提出的模型融合方法能够激发未来更多关于这个领域的探索。