你好,我是悟空。
在日趋实时的数据分析领域,一个开源项目在国内数据库圈逐渐崭露头角,它就是 StarRocks,这个分析型数据库正在重新定义我们对实时数据处理的认知。
StarRocks 是一款怎样的产品?处于大数据生态的什么位置上?有什么功能特性?性能如何?
系好安全带,数据库知识分享发车了。
一、StarRocks 是什么?
StarRocks 是 Linux 基金会旗下项目,是新一代极速全场景 MPP 数据库,遵循 Apache 2.0 开源协议。其架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO 优化器,实现亚秒级的查询速度,尤其是多表关联查询表现尤为突出。StarRocks 还支持现代化物化视图,进一步加速查询。
二、StarRocks 在数据生态的定位
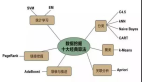
随着数据量的增长,需求的不断迭代,原有的以 Hadoop 为核心的大数据生态,在性能、实效性、运维难度及灵活性等方面都难以满足企业的需求,OLAP 数据库面临着越来越多的挑战,很难有一种数据库能够适配大部分的业务,这时就出现诸如 Hive 、Druid、CK、ES、Presto 等多技术栈堆叠应用的情况,虽然能解决问题,但是开发和运维的成本、难度也随之上升。
作为一款 MPP 架构的分析性数据库,StarRocks 能够支撑 PB 级别的数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、位图索引、稀疏索引等优化手段构建极速统一的分析层数据存储系统。
在整体的大数据生态中:
- 从上层应用往下看,StarRocks 兼容了 MySQL 协议,可以平稳的对接各种开源或者商业 BI ⼯具,⽐如说 Tableau,FineBI,SmartBI,Superset 等;
- 数据同步环节,StarRocks 可以从 Oceanbase 等事务性数据库中拉取业务数据,通过 CloudCanal 等数据采集工具写入 StarRocks。
- 中间的 ETL 工作可以在计算引擎中完成,例如使用 Flink 或 Spark。StarRocks 还提供了相应的 Flink Connector 和 Spark Connector。
- 也可以采用 ELT 模式,在数据加载到 StarRocks 之后,利用 StarRocks 的物化视图和实时 Join 能力进行数据建模。在 StarRocks 中可以选择多种数据模型,如预聚合、宽表或灵活性较高的星型/雪花模型。
- 同时,可以借助 Iceberg、Hive、Hudi 外表功能构建一套湖仓一体的架构。数据湖中的有价值数据可以流入 StarRocks 进行关联查询;而 StarRocks 中的隐藏价值数据或价值不高的数据也可以流入数据湖,以低成本方式存储。
在经过一系列的建模后,StarRocks 中的数据可以服务于多种消费场景,比如说报表业务、实时指标监控、智能多维分析、客群圈选、自助 BI 业务。
三、架构和功能特性
StarRocks 的架构设计融合了 MPP 数据库和分布式系统的设计思想,具有极简的架构特点。整个系统由前端节点(FE)、后端节点(BE 和 CN)组成。这种设计使得 StarRocks 在部署和维护上更为简单,同时提升了系统的可靠性和扩展性。
- 向量化引擎:StarRocks 采用向量化查询引擎,通过并行执行和减少数据访问次数,极大提升了数据处理速度。
- CBO(基于代价的优化器):StarRocks 利用 CBO 智能选择最优的查询执行计划,通过精确的成本估算优化查询性能。
- 高并发查询:通过优化查询调度和资源分配,确保在多用户同时访问时,系统能够稳定运行并快速响应每个查询请求。
- 灵活数据建模:允许用户根据业务需求构建复杂的数据模型,如星型模型和雪花模型。这种灵活性支持了复杂的数据分析流程,提高了数据的组织和查询效率。
- 智能物化视图:用户可以预定义和存储复杂的查询结果,通过预聚合数据提高查询速度、降低存储成本。StarRocks 同步和异步物化视图均支持智能的透明改写,可以按需灵活创建和删除,在查询时无需修改 SQL,自动进行改写,性能及体验俱佳。
 图片
图片
- 湖仓一体能力:结合了数据湖的灵活性和数据仓库的分析能力,提供了一个统一的数据平台,简化了数据存储、处理和分析的流程,无需在不同系统间迁移数据。
- 存算分离:StarRocks3.0 版本引入存算分离架构,实现计算与存储的完全解耦,计算节点可以实现秒级的动态扩缩容。实现更灵活的数据分享、资源弹性伸缩、资源隔离,总体性能追平存算一体。
- 兼容性:提供 MySQL 协议接口,支持标准 SQL 语法,用户可以通过 MySQL 客户端方便地查询和分析 StarRocks 中的数据
 图片
图片
这些特性使得 StarRocks 在数据处理和分析方面表现出色,还能在多租户和资源管理方面提供有效的支持。
四、性能对比测试
SSB 单表场景性能测试:StarRocks、ClickHouse 和 Druid
在标准测试数据集的 13 个查询上,StarRocks 整体查询性能是 ClickHouse 的 2.1 倍,Apache Druid 的 8.7 倍。
StarRocks 启用 Bitmap Index 后整体查询性能是未启用的 1.3 倍,此时整体查询性能是 ClickHouse 的 2.8 倍,Apache Druid 的 11.4 倍。
 图片
图片
采用 3x16core 64GB 内存的云主机,在 6 亿行的数据规模进行测试。
来源:https://docs.starrocks.io/zh/docs/benchmarking/SSB_Benchmarking/
TPC-H 基准测试:StarRocks Hive 外表和 Trino 查询
TPC-H 100G 规模的数据集上进行对比测试,StarRocks 本地存储查询总耗时为 17s,StarRocks Hive 外表查询总耗时为 92s,Trino 查询总耗时为 187s。
 图片
图片
该测试共包含 8 张表,数据量可设定从 1 GB~3 TB 不等。
来源:https://docs.starrocks.io/zh/docs/benchmarking/TPC-H_Benchmarking/
TPC-DS 性能测试:StarRocks 与 Trino
采用 TPC-DS1TB 数据集进行测试,分别使用 StarRocks 和 Trino 查询以 Apache Iceberg 表格式存储的 Parquet 文件的相同数据副本, StarRocks 的整体查询响应时间比 Trino 快 5.54 倍。

来源:https://mp.weixin.qq.com/s/kEqyRO_aOnOnsROXllwA2g
五、StarRocks 是数据分析的最佳解决方案吗?
在数据分析这个复杂多变的领域,不太可能存在一个放之四海而皆准的解决方案。StarRocks 在某些方面的确表现出色,例如尤其是在处理大规模数据集时的查询速度。
不过并非所有企业都需要如此高度的实时性,对于某些业务来说,批处理或准实时分析可能已经足够。如果你处理的是小型数据集或简单查询,它可能有点大材小用。但对于需要通过实时分析进行商业决策和洞察的企业来说,StarRocks 或许是最佳解决方案,至于是否选择 StarRocks,应该基于对自身需求进行技术对比和测试,也要看企业对资源和长期战略进行深入评估。
参考:
https://zhuanlan.zhihu.com/p/532302941
https://docs.starrocks.io/docs/introduction/StarRocks_intro/