













译者 | 李睿
审校 | 重楼
在软件开发中,有效地管理大型数据集至关重要。而检索策略在提高性能和可扩展性方面起着至关重要的作用,特别是在响应时间非常关键的情况下。分页是有效管理数据的一项核心技术,它对于优化性能和资源管理至关重要。本文将探讨适用于不同场景和需求的两种分页策略:基于偏移量的分页和基于游标的分页。这些策略将帮助用户了解分页的重要性,以及它们如何使他们的系统受益。

利用Jakarta Data,本文将探索这些分页技术集成到使用Quarkus和MongoDB开发的REST API中。这种组合展示了实际应用的实现,并突出了现代技术和先进数据处理方法之间的协同作用。
本文旨在全面理解每种分页方法的机制、优点和权衡,使开发人员能够做出适合复杂和高需求应用程序的明智决策。
分页:从古代卷轴到现代数据库
分页是数据组织中的一个重要概念,其根源可以追溯到最早的书面记录形式。在现代应用方法中,分页将内容划分为离散的页面,无论是印刷页面还是数字页面。通过使信息访问易于管理和直观,以及通过限制在任何时间加载或呈现的数据量来增强数据检索系统的性能来改进用户体验。
有效数据组织的必要性是一个复杂的难题。像罗马这样的古代文明发展了早期管理大量书面信息的方法。尽管古罗马人没有像现代人所理解的那样使用分页——将文本划分为页面,但他们实施了预示着现代分页系统的组织方法。
在罗马,长文本通常写在纸莎草或牛皮纸制成的卷轴上。这些卷轴很长,采用索引和标记来导航。这种标记的作用类似于现代目录,引导读者阅读不同的文本部分。虽然按照当今的标准来看,这种方法很简陋,但它代表了一种早期的分页形式,原因是它将信息组织成可以独立访问的片段。
此外,罗马人还使用蜡板来记录较短的文件。这些蜡板可以装订在一起,形成一种类似于当今书籍的结构——手抄本(codex)。手抄本的出现是文本组织的一次重大演变,使人们能够更快、更有效地获取信息。用户可以翻页,这显然是当前分页系统的前身,显著地提高了查看信息的速度和便利性。
在数字时代,分页对于有效处理大型数据集至关重要。数字分页通过分段交付内容而不是要求同时加载整个数据集,有助于管理服务器负载并缩短响应时间。它通过提供无缝的导航体验来节省资源,并改进用户与应用程序的交互。
古罗马的文本组织方法和现代数字分页之间的相似之处突出了贯穿历史的持续需求:有效地管理大量信息。无论是通过卷轴上的物理标记、手抄本的开发,还是复杂的数字分页算法,其核心挑战仍然是一样的——使信息可访问和可管理。
现代应用中的分页:必要性和策略
分页是现代软件应用程序中的一个基本特性,它有助于将数据组织成可管理的部分。这种方法通过防止信息过载来增强用户体验,并通过减少后端系统的负载来优化应用程序性能。当对数据进行分页时,系统一次只能查询和呈现必要的数据子集,从而减少内存使用并改善响应时间。它在大型数据集或用户高并发性应用程序中尤其重要。在这些应用程序中,高效的数据处理可以显著提高可扩展性和用户满意度。
分页非常有用,但它也带来了一些挑战。开发人员需要仔细平衡用户体验和服务器性能。实现分页需要在客户端和服务器端附加逻辑,这会使其开发变得更加复杂。虽然分页可以通过只获取部分数据来减少初始加载时间,但它可能会增加用户在多个页面中导航时的总等待时间。而维护页面之间的场景,例如排序和过滤器,也需要仔细的状态管理,并增加了复杂性。
在现代网页(Web)开发中,有两种主要的分页策略:基于偏移量的分页和基于游标的分页。每种分页策略都有优点和缺点,使其更适合不同的场景。
基于偏移量的分页
基于偏移量的分页是将数据划分为可管理数据块的传统方法。在返回一定数量的记录之前,跳过指定数量的记录来访问数据。这种技术经常用于Web和数据库应用程序中,以便使用简单的数字偏移量直接导航到特定的页面。
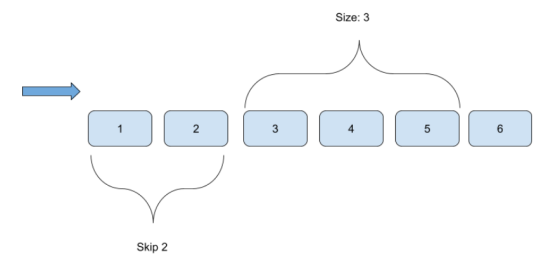 图1基于偏移量的分页示意图
图1基于偏移量的分页示意图
基于偏移量的分页实现通常涉及数据库查询中的两个关键参数:
- LIMIT:该参数指定在单个页面中返回的最大记录数。它定义了每个数据块的大小,与分页中的“页面”概念保持一致。
- OFFSET:该参数表示从数据集开头跳过的记录数。OFFSET的值通常计算为(页面-1)*页面大小,允许用户直接跳转到任何页面的开头。
基于偏移量的分页因其简单和直接的实现而备受青睐。在用户可以直接跳转到特定页面,并且记录总数已知且相对稳定的应用程序中,这种方法尤其有效。这使得它非常适合用户友好的导航和简单性至关重要的情况。
基于偏移量的分页的主要限制是它在大型数据集上的可扩展性。随着数据集的增长和用户请求的页面数量的增加,跳过许多记录的成本也会增加。这将导致查询性能变慢,因为每个后续页面都需要计数和跳过更多记录才能到达所需页面的起始点。
如果底层数据需要插入、删除或修改,用户在页面之间导航时可能会遇到“幻读”或跳过记录。发生这种情况是因为偏移量没有考虑初始页面加载后数据集大小或顺序的变化。
基于偏移量的分页由于其用户友好的方法和易于实现的特点,仍然是许多应用程序的热门选择。然而,了解其局限性并正确规划其使用对于确保系统在数据扩展时保持响应并提供良好的用户体验至关重要。
基于游标的分页
基于游标的分页是在大型或动态更新的数据集中管理数据检索的有效方法。它使用游标(对数据集中特定点的引用)从游标位置开始顺序获取数据。
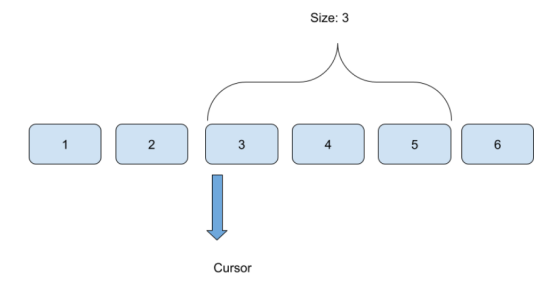 图2基于游标的分页示意图
图2基于游标的分页示意图
基于游标的分页依赖于游标来指导数据获取。游标可以包含多个字段,以确保精确的数据检索和维护排序顺序。以下是它的结构:
(1)游标字段
一个或多个字段唯一标识数据集中每条记录的位置。这些字段应该是稳定的(即设置之后不更改)和唯一的,以防止重复和确保数据完整性。常用的字段包括时间戳、唯一ID或多个字段的组合,以支持复杂的排序需求。
(2)查询方向
这个指定数据检索相对于游标位置是向前移动还是向后移动。它在社交媒体订阅源或日志监控系统等可能感兴趣的新条目或旧条目的应用程序中非常有用。
(3)多个字段的使用
当按多个条件排序时(例如,按creation_date和title对博客文章进行排序),游标可以包含这些字段,以确保分页在查询之间保持指定的排序顺序。它对于一致性至关重要,特别是在数据集很大或经常更新的情况下。
在分页中使用游标对于大型或频繁更新的数据集特别有利,因为它避免了跳过记录的性能开销,并确保对数据的一致访问。
虽然基于游标的分页提供了显著的性能优势并增强了数据一致性,但其实现可能很复杂。它需要设置一个稳定且唯一的游标,这可能具有挑战性,特别是在没有明显唯一标识符的数据集中。此外,它将用户限制为顺序导航,这在需要随机访问数据的用例中可能是一个限制。调整用户界面以平滑地使用基于游标的分页,特别是在游标中使用多个字段时,也会增加开发的复杂性。
在应用程序中实现分页时,开发人员通常必须在基于偏移量的分页和基于游标的分页之间进行选择。每种方法都有不同的优势和挑战。为了做出明智的决策,了解这些方法在各个方面的比较是至关重要的,例如实现的容易程度、性能、数据一致性和用户导航。为了帮助确定最适合软件开发中不同场景的分页策略,下表提供了基于偏移量和基于游标的分页的全面比较,突出了关键特性和典型用例。此外,该表还考虑了可扩展性。
功能 | 基于偏移量的分页 | 基于游标的分页 |
描述 | 使用数字偏移量对数据进行分页,以便在返回下一组记录之前跳过几条记录 | 使用游标(通常是唯一标识符)从指定位置按顺序获取数据 |
实施 | 使用LIMIT和OFFSET参数实现基本的SQL或NoSQL查询很简单 | 实现起来比较复杂,需要一个稳定且唯一的字段作为游标 |
最佳用例 | 非常适合中小型数据集和应用程序,其中总数据计数和对任何页面的直接访问是有益的 | 非常适合大型或动态变化的数据集,其中性能和数据一致性至关重要 |
性能 | 性能随着数据集大小的增加而下降,特别是当访问由于跳过记录的负载增加而导致的更高页码时 | 始终如一的高性能,因为它避免了跳过记录和直接从游标位置开始访问数据的开销 |
数据一致性 | 如果底层数据发生变化,在分页过程中容易出现幻读或数据重复等问题 | 提供更好的一致性,因为每个页面加载取决于游标的位置,这可以适应数据的变化 |
用户导航 | 允许用户直接跳转到任何特定页面,方便随机访问 | 通常将用户限制为顺序导航,这可能不适合所有应用程序 |
查询的复杂性 | 简单的查询,直接的分页逻辑 | 查询可能很复杂,特别是当多个字段用作游标以维护顺序和唯一性时 |
可扩展性 | 由于较高偏移量增加了查询负载,因此在较大数据集的情况下可扩展性较差 | 高度可扩展,特别有效地处理庞大的数据集 |
在处理大型数据集时,了解分页策略的效率和局限性至关重要。基于偏移量的分页的一个主要挑战是,随着偏移量的增加,访问数据变得更加困难,特别是在大型数据集中。例如,如果一个数据集有100万条记录,并被分成100个页面,那么访问最后一个页面(第10000页)将要求数据库在传递最后100条记录之前处理并丢弃最初的999,900条记录。随着数据集的增长,它可能导致更长的加载时间,使得基于偏移量的分页在处理大量数据时不太实用。
与基于偏移量的分页相比,基于游标的分页是管理广泛数据集的更有效的解决方案。对于基于偏移量的分页,高偏移量可能会导致性能问题,但是基于游标的分页通过使用游标跟踪最后获取的记录来避免这些缺陷。该方法允许后续查询从最后一个查询结束的地方开始,从而提高数据检索速度。为了说明这一点,本文附带的图表比较了基于偏移量的分页和基于游标的分页在处理730万条记录的数据集时的性能,显示了使用游标进行分页的速度优势显著。
这种可视化表示强调了在考虑数据集大小和访问模式等因素的情况下选择适当分页方法的战略重要性。这确保了最佳的性能和用户体验,这是大规模数据处理的关键考虑因素。
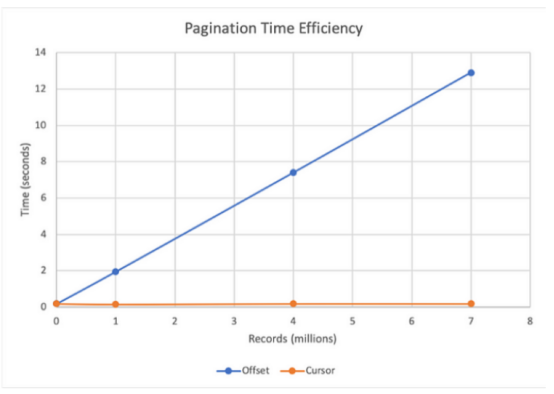 图3 MySQL中730万条记录的基于偏移量和游标的分页(来源)
图3 MySQL中730万条记录的基于偏移量和游标的分页(来源)
选择基于偏移量的分页还是基于游标的分页取决于应用程序的特定需求。基于偏移量的分页对于较小的数据集或需要直接页面访问时效果很好,而基于游标的分页更适合大型或动态数据集。接下来,将在一个示例应用程序中演示这两种方法,以展示每种方法的实际含义。
实用的分页介绍
本节将从关于分页的理论讨论过渡到实际演示,重点介绍实现基于偏移量的分页和基于游标的分页的不同方法。以下将探索这些概念,在与MongoDB配对的Quarkus应用程序中使用Jakarta Data。这种设置能够通过操作可管理的数据集来直接比较两种分页技术。
设定的目标是提供一个清晰的示例,说明如何使用Jakarta Data无缝集成和管理这两种分页策略,这是Java应用程序中用于数据处理的强大工具集。虽然这个演示的重点是一个只涉及10个元素的简单场景,但重要的是要注意,所讨论的原则和方法并不局限于小数据集。它们是可扩展的,适用于更大的数据集,让用户有信心在现实场景中应用这些策略。
此外,开发一个全面的REST API(包括使用查询参数和实现用于分页的HATEOAS(超媒体作为应用程序状态引擎))的更广泛的场景值得进行详细的讨论。设计此类API所涉及的复杂性以及有效合并分页的策略是在这里不深入研究的重要主题。与其相反,这一演示旨在介绍使用Jakarta Data进行分页的核心概念,重点关注分页机制的技术实现,而不是REST API设计的复杂性。最后将在文章结尾处为那些有兴趣深入探索REST API构建的更广泛背景和细节的人员提供参考。
本文专门讨论了Jakarta Data中可用的分页特性。但是,需要注意的是,Jakarta Data提供了广泛的功能,旨在简化Jakarta EE应用程序的持久性集成。
Jakarta Data通过其API促进分页,在管理大型数据集或需要复杂查询功能的应用程序中实现高效的数据处理和检索。两个主要组件支持分页功能:
1.创建PageRequest
Jakarta Data提供了PageRequest类来封装分页请求。以下是如何指定不同类型的分页:
(1)基于偏移量的分页
当想要为数据检索指定特定的页面和大小时,使用这个方法。它很简单,适合于已知项目总数的许多标准用例。
(2)基于游标的分页
这一方法用于处理连续数据流或数据集较大且经常更新的情况。它允许从某一点连续获取数据,而无需重新查询先前获取的记录。
这两种方法都旨在通过限制每个查询检索的记录数量来优化数据获取过程,从而提高性能和资源利用率。
2.特殊参数
Jakarta Data还允许使用特殊参数来增强存储库接口的功能。这些参数可用于进一步优化分页策略,包括限制、排序和更复杂的分页机制。
分页查询的标准返回结构是页面(Page)接口,它提供了一种处理分页数据的简单方法。Jakarta Data提供了一个名为CursoredPage的专门版本,用于基于游标的分页。这种结构对于传统的基于页面的导航不足或不实用的场景是有益的。
实际的例子
根据之前关于Jakarta Data分页特性的讨论,希望通过一个实际示例展示如何在实际应用程序中实现这些功能。所展示的示例将Jakarta Data与Eclipse JNoSQL、Quarkus和MongoDB结合使用,以展示Jakarta Data的灵活性和强大功能,特别是它如何通过Jakarta Persistence与NoSQL和关系数据库进行接口。
对于那些有兴趣探索完整代码并深入了解其功能的人,可以在这里找到样例项目:Quarkus Pagination with JNoSQL and MongoDB.
示例中的FruitRepository扩展了BasicRepository,利用Jakarta Data的功能以一种简化的方式与数据库进行交互。这个存储库演示了Jakarta Data获取和管理数据的三种主要方法:
(1)使用@Find注释:通过允许直接基于注释的查询,简化了查询过程。
(2)使用Jakarta Query Language:支持类似于SQL的更复杂的查询,适合高级数据操作。
(3)按查询约定使用方法:促进基于方法命名约定的查询,使代码更易于阅读和维护。
在FruitRepository中,实现了两个特定的方法来处理分页:
- 基于游标的分页:它利用CursoredPage<Fruit>来有效地管理大型数据集。这种方法在数据不断更新的应用程序中特别有用,因为它提供了一种稳定和高性能的方式来处理顺序数据检索。
- 基于偏移量的分页:它使用一个简单的Page<Fruit>来以更传统的逐页方式访问数据。这种方法简单明了,许多开发人员都很熟悉,非常适合具有稳定和可预测数据集的应用程序。
这些示例说明了Jakarta Data在处理不同分页策略方面的多功能性,为开发人员提供了基于其特定应用程序需求的强大选项。这种方法不仅强调了Jakarta Data的实际应用,而且强调了它在不同类型的数据库和数据管理策略之间的适应性。
在使用Jakarta Data的实际实现的基础上,Quarkus应用程序中的FruitResource类为基于偏移量的分页和基于游标的分页方法提供REST端点。这个设置有效地展示了这两种策略之间的细微差别,以及如何将它们应用于RESTful数据服务。
在FruitResource类中,为不同的分页策略定义了两个不同的REST端点。
这个端点演示偏移分页,其中客户端可以将页面和大小指定为查询参数。它很简单,允许用户直接跳转到特定的页面。这种方法对于总大小已知且需要在页面之间进行可预测导航的数据集特别有效。
这个端点满足了基于游标的分页,这对于处理大型或频繁更新的数据集至关重要。游标充当指针,便于连续获取记录,而不会跳过之前的数据。这种方法确保了效率和一致性,特别是在处理实时数据流时。客户端可以根据需要的导航方向提供前后游标。
两个端点都使用定义为ASC或DESC的Sort<Fruit>来确定获取记录的顺序。通过确保数据按逻辑顺序呈现,这种排序顺序增强了分页的可用性。
FruitResource类设计是一个很好的例子,说明了如何定制不同的分页方法以适应特定的应用程序需求。通过在单个应用程序中比较这两种方法,开发人员可以获得基于其数据特征和用户需求选择和实现最合适分页策略的实际见解。这种方法不仅展示了Jakarta Data在使用Quarkus和MongoDB的微服务架构中的能力,还增强了对RESTful服务设计和数据管理的理解。
结论
当在Quarkus和MongoDB环境中使用Jakarta Data应用基于偏移量的分页和基于游标的分页的复杂性时,已经实现了Jakarta Data在管理数据检索过程中的适应性和有效性。这种探索提供了实际的用例,并强调了每种分页方法的战略优势,使开发人员能够根据他们的应用程序需求做出明智的决策。
本文为进一步探索Jakarta Data的功能及其与Quarkus等现代应用程序框架的集成提供了基础。通过理解这些分页技术,开发人员将能够更好地构建可扩展且高效的应用程序,这些应用程序可以轻松地处理大型数据集。而在将来,选择和实现最合适的分页策略对于优化应用程序性能和增强用户体验至关重要。
参考文献
原文标题:Efficient Data Management With Offset and Cursor-Based Pagination in Modern Applications,作者:Otavio Santana
























