













什么是目标检测
目标检测算法是计算机视觉领域的一类算法,主要用于从图像或视频中识别出特定的对象,并确定它们的位置和大小。这些算法可以识别多种对象,并能同时输出这些对象的边界框(bounding boxes)位置。目标检测在许多实际应用中非常关键,例如自动驾驶、安防监控、人脸识别和增强现实等。
现在让我们借助下图稍微简化一下这个陈述。
 图片
图片
我们不必对这些图片中的狗进行分类,而是要实际定位图片中的狗。也就是说,我必须找出图片中狗的位置?是在中间还是在左下角?我们可以在图像中的狗周围创建一个框,并指定该框的 x 和 y 坐标。
 图片
图片
现在,假设图像中物体的位置可以用这些框的坐标来表示。
图像中物体周围的这个框被称为边界框。现在,这变成了一个图像定位问题,我们得到一组图像,我们必须确定图像中物体的位置。
请注意,这里我们只有一个类。如果我们有多个类怎么办?
 图片
图片
在这张图片中,我们必须找到图像中的物体,但请注意,并非所有物体都是狗。这里有一只狗和一辆车。
所以我们不仅要找到图像中的物体,还要将找到的物体分类为狗或汽车。所以这变成了一个目标检测问题。
对于目标检测问题,我们必须对图像中的物体进行分类,并确定这些物体在图像中的位置。
而图像分类问题只有一个任务,即对图像中的物体进行分类。
 图片
图片
总的来说,对于目标检测任务,我们需要确认以下三个问题。
- 要识别图像中是否存在物体?
- 这个物体位于哪里?
- 这是什么物体?
 图片
图片
具体到这个例子,我们在图像中有一个物体。我们可以在这个物体周围创建一个边界框,这个物体是一辆紧急车辆。
用于目标检测的训练数据
在本节中,我们将了解使用深度学习进行目标检测的数据是什么样的。
我们首先从分类问题中举一个例子。在下图中,我们有一个输入图像和针对这个输入图像的目标类。
 图片
图片
现在,假设手头的任务是检测图像中的汽车。因此,在这种情况下,不仅要有一张输入图像,还要有一个目标变量,该变量具有表示图像中物体位置的边界框。
 图片
图片
因此,在这种情况下,这个目标变量有五个值,值 p 表示物体出现在上图中的概率,而四个值 Xmin、Ymin、Xmax 和 Ymax 表示边界框的坐标。
下面让我们了解如何计算这些坐标值。
请考虑图像上方的 x 轴和 y 轴。在这种情况下,Xmin 和 Ymin 将是边界框的左上角,而 Xmax 和 Ymax 将是边界框的右下角。
现在,目标变量只回答了两个问题?
- 图像中是否存在物体?
如果不存在物体,则 p 将为零,而当图像中存在物体时,p 将为 1。 - 如果图像中存在一个物体,那么该物体位于哪里?
你可以使用边界框的坐标找到对象的位置。
当有更多类别时会发生什么?在这种情况下,目标变量将如下所示。
 图片
图片
因此,如果你有两个类别,即紧急车辆和非紧急车辆,那么你将有两个附加值 c1 和 c2 表示上图中的物体属于哪个类别。
如果我们考虑这个例子,我们将图像中存在物体的概率定为一个。我们给定 Xmin、Ymin、Xmax 和 Ymax 作为边界框的坐标。然后,由于这是一辆紧急车辆,因此 c1 等于 1,而由于这是一辆非紧急车辆,因此 c2 为 0。
 图片
图片
现在,训练数据应该像上图那样。
假设我们建立了一个模型并从模型中得到了一些预测,这是你可以从模型中获得的可能输出。
物体出现在这个预测边界框中的概率为 0.8。你有这个蓝色边界框的坐标,也就是预测的边界框,分别是 (40,20) 和 (210,180),最后是 c1 和 c2 的类值。
所以现在我们了解了什么是目标检测,以及目标检测问题的训练数据是什么样的。
边界框评估
在本节中,我们将讨论一个非常有趣的概念,即并集与交集 (IoU)。我们将使用它来确定我们创建的各个块的目标变量。
考虑以下场景,这里我们有两个边界框,box1 和 box2。现在如果我问你这两个框中哪一个更准确,显然答案是 box1。
 图片
图片
为什么?因为它有 WBC(白细胞) 的主要区域,并且正确检测到了 WBC(白细胞)。但是我们如何从数学上找出这一点?
如果我们能够找出实际和预测边界框的重叠,我们将能够决定哪个边界框是更好的预测。
 图片
图片
可以看到,边界框 box1 与实际边界框重叠度更高,交集面积约为实际边界框的 70%。所以我们可以说,在这两个边界框中,box1 显然是更好的预测。
让我们考虑另一个例子,假设我们创建了多个不同大小的边界框或补丁。
 图片
图片
在这里,左侧边界框的交集肯定是 100%,而在第二张图片中,这个预测边界框交集只有 70%。所以在这个阶段,你会说左侧边界框的预测更好吗?显然不是。右侧边界框更准确。
因此,为了处理这种情况,我们还考虑了并集面积。
 图片
图片
我们可以说,这个并集面积(蓝色区域)越大,预测的边界框的准确度就越低。
现在,这被称为并集交集 (IoU),即交集的面积除以并集的面积。
 图片
图片
那么,IoU 的取值范围是多少呢?让我们考虑一些极端的情况。
如果我们有实际边界框和预测边界框,并且它们之间完全没有重叠,那么交集的面积将为零,而并集的面积将是这两块面积的总和。因此,总体而言,IoU 将为零。
 图片
图片
另一种可能的情况是预测边界框和实际边界框完全重叠,在这种情况下,交集的面积将等于重叠的面积,并集的面积也将相同。由于在这种情况下分子和分母相同,因此 IoU 将为 1。
 图片
图片
所以,IoU 范围在 0 到 1 之间。
现在需要定义一个阈值,以确定预测的边界框是否是正确的预测。假设 IoU 大于阈值(可以是 0.5 或 0.6)。在这种情况下,我们会认为实际边界框和预测边界框非常相似。
 图片
图片
而如果 IoU 小于特定阈值,我们会说,预测的边界框与实际边界框完全不接近。
 图片
图片
计算 IoU
在上一节中,我们讨论了如何计算 IoU 值。我们需要交集面积和并集面积。
现在的问题是,我们如何找出这两个值?
要找出交集面积,我们需要这个蓝色框的面积。我们可以使用此蓝色框的坐标来计算。
为了找出 Xmin 的值,我们将使用这两个边界框的 Xmin 值,表示为 X1min 和 X2min。
 图片
图片
现在,正如你在图上看到的,这个蓝色边界框的 Xmin 完全等同于 X2min。我们还可以说,这个蓝色框的 Xmin 始终是 X1min 和 X2min 这两个值中的最大值。
对于这个蓝色边界框的 Xmax,我们将比较 X1max 和 X2max 的值。我们可以看到,这个蓝色边界框的 Xmax 等于 X1max。它也可以写成 X1max 和 X2max 中的最小值。
 图片
图片
同样,为了找出 Ymin 和 Ymax 的值。我们将比较 Y1min 和 Y2min 以及 Y1max 和 Y2max。Ymin 的值将是 Y1min 和 Y2min 中的最大值,Ymax 将是 Y1max 和 Y2max 中的最小值。
现在我们有了这四个值,即 Xmin、Ymin、Xmax 和 Ymax。我们可以通过将这个矩形的长乘以宽来计算出交点的面积,这个矩形就是这里的蓝色矩形。
 图片
图片
接下来,重点是计算并集面积。因此,为了计算并集面积,我们将使用这两个边界框(即绿色边界框和红色边界框)的坐标值。
 图片
图片

现在请注意,当我们计算 box1 和 box2 的面积时,我们实际上计算了这个蓝色阴影区域两次。因为,这是绿色矩形和红色矩形的一部分。由于这部分被计算了两次,因此我们必须减去一次,才能得到并集面积。
所以,最终的并集面积将是 box1 的面积与 box2 的面积之和,之后必须减去交集面积。
 图片
图片
现在我们得到了两个边界框的交集面积,也得到了两个边界框的并集面积。现在我们可以简单地用交集面积除以并集面积来计算 IoU。
评估指标
现在,我们将讨论目标检测中常用的评估指标。
目标检测的评估指标主要有:
- 交并比 (IoU)
- 平均准确率(mAP)
我们之前讨论了 IoU,这里我们重点介绍 mAP
精度
精确度是在所有预测为正类的样本中,真正属于正类的比例。它重点评估了分类器在预测正类上的表现。
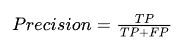
现在,让我们举一个例子来了解如何计算精度。
假设我们有一组边界框预测。除此之外,我们还通过将这些边界框预测与实际边界框进行比较来计算 IoU 分数。
假设我们的阈值是 0.5。
 图片
图片
因此,在这种情况下,我们可以将这些预测分为真阳性和假阳性。一旦我们得到了真阳性和假阳性的总数,我们就可以计算出精确率。在这种情况下,精确率为 0.6。
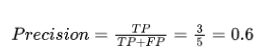
AP(平均精度)
对于每个类别,计算其平均精度(AP),步骤如下。
































