从今年开始,人们对大型语言模型 (LLM) 及其在 GPU 基础设施上的部署的兴趣显着增加。这种不断增长的热情是由人工智能和机器学习的进步推动的,这需要 GPU 能够有效提供大量的计算能力。GPU 领先制造商 Nvidia 的股价也因这一趋势而飙升。同样诞生了大量的大模型,对于这些模型的部署和管理也变得越来越重要,在这方面 Ollama 和 OpenUI 是一个不错的选择。
Ollama 是一个开源的机器学习模型部署工具,它可以帮助您将模型部署到生产环境中,简化大型语言模型 (LLM) 的管理和交互。Ollama 拥有各种一流的开源模型,例如 Llama 3、Phi 3、Mistral 等等,我们可以将 Ollama 看成是 Docker,但是专注于机器学习模型。
使用 Ollama 部署模型非常简单,就类似于使用 Docker 部署应用程序一样。但是,如果你对 CLI 不熟悉,那么使用 Ollama 会有点痛苦。为了解决这个问题,我们可以使用一个 open-webui 的项目,它提供了一个漂亮的界面,可以让您更轻松地部署模型。
为了更好地管理 Ollama,我们可以将 Ollama 部署到 Kubernetes 集群中。这样,我们就可以更好地管理 Ollama,而不需要担心 Ollama 的高可用性、扩展性等问题。
当然首先需要一个 Kubernetes 集群,最好带有 GPU,但即使没有 GPU,llama3 模型在仅使用 CPU 的情况下也能表现得相对较好。
部署 Ollama 到 Kubernetes
要部署 Ollama 和 Open-WebUI 到 Kubernetes 很简单,因为 Open-WebUI 项目提供了一个 Helm Chart,可以让我们更轻松地部署 Ollama 和 Open-WebUI。这个 charts 包被托管在 https://helm.openwebui.com,我们可以使用 Helm 添加这个 repo:
open-webui 这个 charts 包默认情况下会部署 Ollama,我们可以根据自己的需求进行配置,例如我们可以配置 Ollama 是否使用 GPU,是否开启数据持久化等等,我们可以覆盖默认的配置来进行配置,如下:
在上面的配置中,我们可以配置 Ollama 是否使用 GPU,是否开启数据持久化等等,对于 open-webui 部分,我们配置的是一个 NodePort 类型的 Service,这样我们就可以通过 Node 的 IP 和 NodePort 来访问 Open-WebUI 项目,当然你也可以配置 Ingress 来访问。
注意:Open-WebUI 项目默认会去访问 huggingface 的模型仓库,因为某些原因,默认情况下国内是无法访问的,所以我们需要配置 HF_ENDPOINT 环境变量来指定一个镜像地址 https://hf-mirror.com,否则会出错。
然后我们可以使用 Helm 安装这个 charts 包:
部署完成后,会在 kube-ai 这个命名空间下运行几个 Pod,我们可以查看 Pod 的状态:
因为上面我们配置的是 NodePort 类型的 Service,所以我们可以通过 Node 的 IP 和 NodePort 来访问 Open-WebUI 项目:
使用
现在我们就可以通过 http://NodeIP:31009 来访问 Open-WebUI 项目了。

第一次使用的时候需要注册一个账号,然后我们就可以登录到 Open-WebUI 项目主页了。

如果你有 Ollama 在其他地方运行,我们可以将其添加为另一个连接。
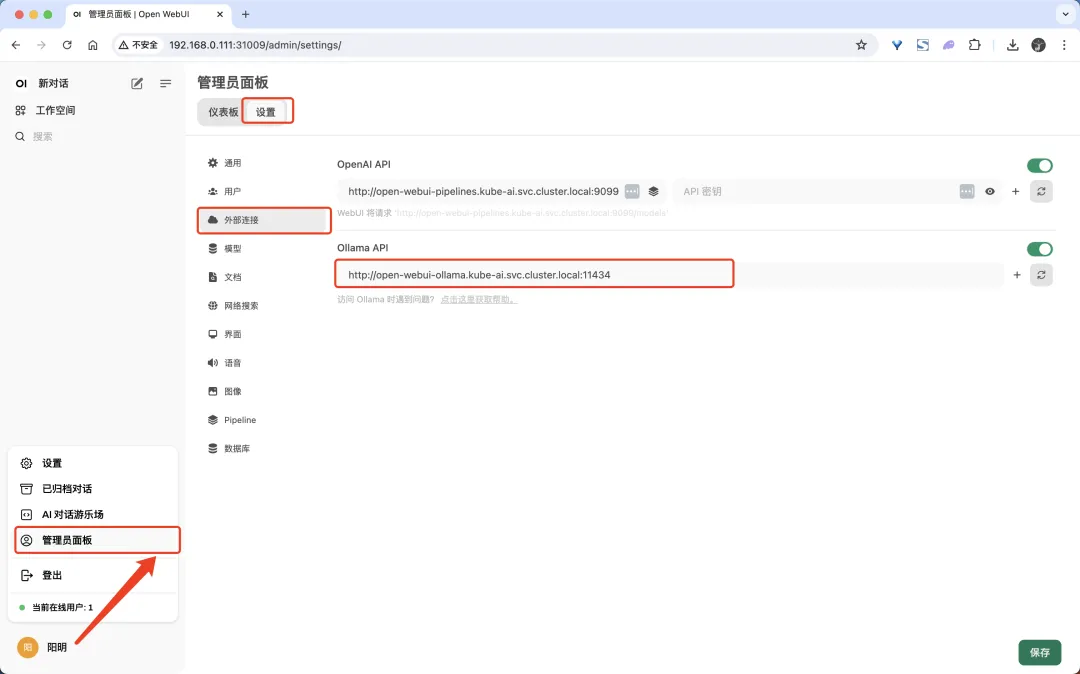
首先需要配置连接 Ollama 的地址,然后我们就可以连接到 Ollama 了,连接成功后,我们就可以看到 Ollama 的模型列表了。
点击左下角的用户头像,然后选择 管理员面板,在管理员面板页面选择 设置 标签页,然后切换到 外部连接 配置项,我们可以设置 Ollama API 地址,我们这里使用的是 Helm 部署的 Ollama,默认已经为我们配置好了 Ollama API 地址。
接下来切换到 模型 标签页,我们就可以从 Ollama 的模型仓库中拉取模型了,可以下载的模型可以从 https://ollama.com/library 查看。比如我们这里选择 llama3 模型,输入 llama3 然后点击右侧的拉取下载按钮,就会开始下载这个模型了,在页面中也可以看到下载的进度。

模型拉取完成后,切回到首页,我们就可以选择切换到 Llama3 模型了。

接下来我们就可以使用 Llama3 模型为我们服务了。

总结
在本文中,我们探讨了使用 Open WebUI 在 Kubernetes 集群上部署 Llama3 的过程。通过容器化和编排技术,我们成功地将 AI powered 的聊天机器人部署到了可扩展和维护的环境中。Open WebUI 的简洁界面和 Kubernetes 的强大自动化能力,让我们简化了部署过程,减少了手动干预。随着世界对 AI 驱动解决方案的不断依赖,这种技术组合将扮演关键角色,快速地带领创新应用程序 Llama3 告诉市场。AI Powered 的聊天机器人的未来看起来非常光明,Open WebUI 和 Kubernetes 将继续领先,期待着下一个令人兴奋的发展!(这一段就来自 Llama3 模型生成)