













译者 | 朱先忠
审校 | 重楼
当前,许多强大的开源基础模型的发布,加上微调技术的不断进步,已经带来了机器学习和人工智能的新范式。整体来看,这场革命的核心在于转换器模型(https://arxiv.org/pdf/1706.03762)。
虽然除了资金充足的公司之外,所有公司都曾经无法获得高精度的特定领域模型;但是如今,基础模型范式甚至能够允许学生或独立研究人员获得适度的资源,以实现与最先进的专有模型相抗衡的结果。

微调技术可以极大地提高模型任务的性能
本文旨在探讨Meta公司的分割一切模型(SAM:Segment Anything Model)在河流像素分割遥感任务中的应用。如果您想直接跳到有关项目代码,那么这个项目的源文件可以在GitHub(https://github.com/geo-smart/water-surf/blob/main/book/chapters/masking_distributed.ipynb)上获得,数据也可以在HuggingFace(https://huggingface.co/datasets/stodoran/elwha-segmentation-v1)上找到。当然,我还是建议您先阅读一下本文。
项目需求
第一个任务是找到或创建一个合适的数据集。根据现有文献,一个良好的SAM微调数据集将至少包含200–800张图像。过去十年深度学习进步的一个关键教训是,数据越多越好,这样一来,更大规模的微调数据集就不会出错。然而,基础模型研究的一个重要目标是,允许即使是相对较小的数据集也足以实现强大的性能。
此外,我们还需要有一个HuggingFace帐户,这可以在链接https://huggingface.co/join处创建。使用HuggingFace,我们可以随时从任何设备轻松存储和获取数据集,这使得协作和再现性更加容易。
最后一个需求是,具备一台带有GPU的设备,我们可以在其上运行训练工作流程。通过Google Colab(https://colab.research.google.com/)免费提供的Nvidia T4 GPU足够强大,可以在12小时内对1000张图像进行50个时期的最大SAM模型检查点(sam-vit-huge)训练。
为了避免在托管运行时因使用限制而影响进度,您可以安装Google Drive并将每个模型检查点保存在那里。或者,部署并连接到GCP虚拟机(https://console.cloud.google.com/marketplace/product/colab-marketplace-image-public/colab)以完全绕过限制。如果您以前从未使用过GCP,那么您就有资格获得300美元的免费信贷,这足以支持对模型进行至少十几次的训练了。
理解SAM架构
在开始训练之前,我们需要先来了解一下SAM模型的架构。该模型包含三个组件:一个是从稍经修改的掩码自动编码器(https://arxiv.org/pdf/2111.06377)得到的图像编码器,一个能够处理各种提示类型的相当灵活的提示编码器,还有一个快速轻量级的掩码解码器。这种设计架构背后的一个重要动机是允许在边缘设备上(例如在浏览器中)进行快速、实时的分割,因为图像嵌入只需要计算一次,并且掩码解码器可以在CPU上运行约50ms。
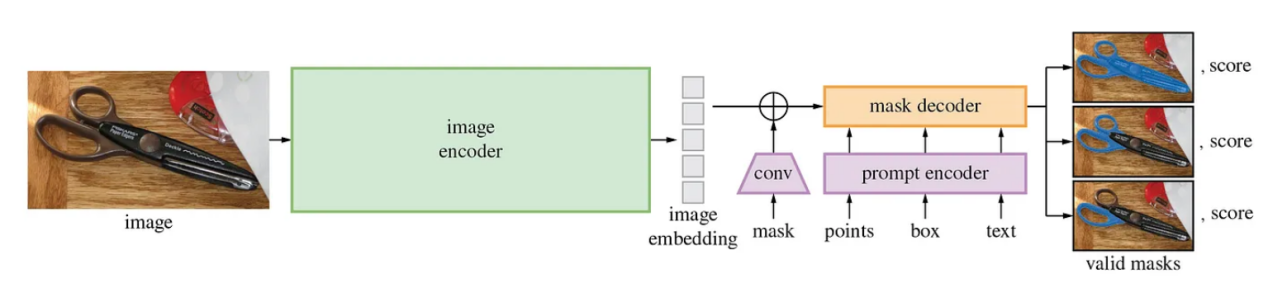
SAM的模型架构向我们展示了模型接受哪些输入以及需要训练模型的哪些部分(图片来源于SAM GitHub:https://github.com/facebookresearch/segment-anything)。
理论上,图像编码器已经学会了嵌入图像的最佳方式,包括识别形状、边缘和其他一般视觉特征等。类似地,在理论上,提示编码器已经能够以最优方式对提示进行编码。掩码解码器是模型架构的一部分,它采用这些图像和提示嵌入,并通过对图像和提示嵌入式进行操作来实际创建掩码。
因此,一种方法是在训练期间冻结与图像和提示编码器相关联的模型参数,并且仅更新掩码解码器权重。这种方法的优点是允许有监督和无监督的下游任务,因为控制点和边界框提示都是自动的,并且可供人工使用。
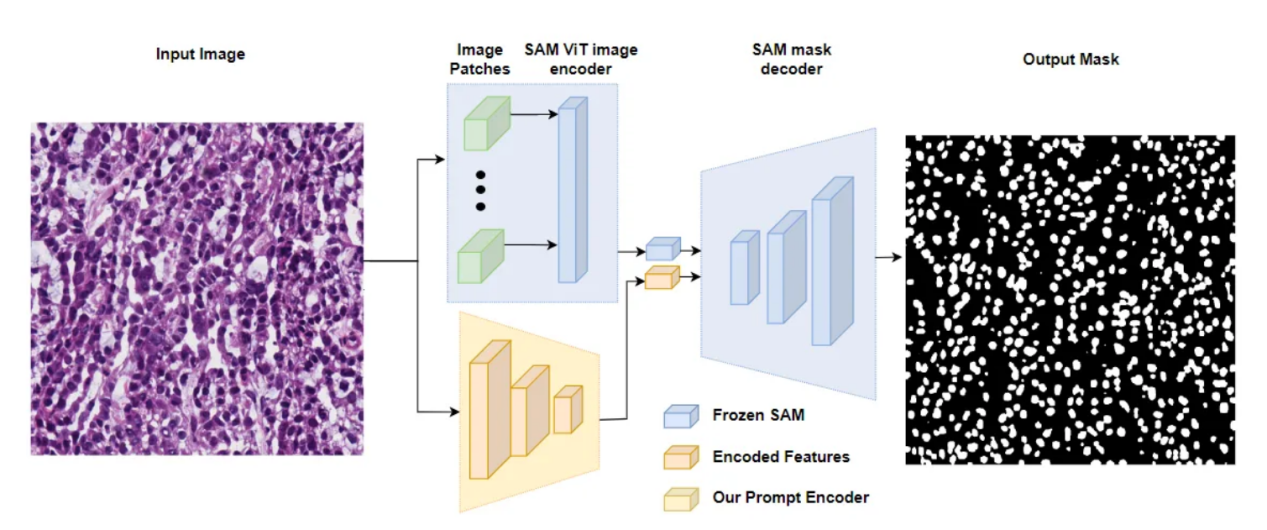
图中显示了AutoSAM体系架构中使用的冻结SAM图像编码器和掩码解码器,以及过载提示编码器(来源于AutoSAM论文:https://arxiv.org/pdf/2306.06370)。
另一种方法是使提示编码器过载,冻结图像编码器和掩码解码器,并且只是简单地不使用原始SAM掩码编码器。例如,AutoSAM体系架构使用基于Harmonic Dense Net的网络来基于图像本身生成提示嵌入。在本教程中,我们将介绍第一种方法,即冻结图像和提示编码器,只训练掩码解码器,但这种替代方法的代码可以在AutoSAM GitHub(https://github.com/talshaharabany/AutoSAM/blob/main/inference.py)和论文(https://arxiv.org/pdf/2306.06370)中找到。
配置提示
接下来的一步是确定模型在推理过程中会收到什么类型的提示,以便我们可以在训练时提供这种类型的提示。就我个人而言,考虑到自然语言处理的不可预测/不一致性,我不建议在任何严肃的计算机视觉项目架构中使用文本提示。剩下的解决方案就需要依赖控制点和边界框技术了;但是,最终的选择还要取决于特定数据集的特定性质,尽管有关文献中已经指出边界框方案的表现相当一致地优于控制点方案。
造成这种情况的原因尚不完全清楚,但可能是以下任何因素之一,或者是这些因素的组合:
- 在推理时(当真实值掩码未知时),好的控制点比边界框更难选择。
- 可能的点提示的空间比可能的边界框提示的空间大几个数量级,因此它没有经过彻底的训练。
- 最初的SAM模型作者主要专注于模型的零样本和少样本(根据人工提示交互计算)功能,因此预训练可能更多地关注边界框。
无论如何,河流分割实际上是一种罕见的情况;在这种情况下,点提示方案实际上优于边界框(尽管只是轻微的,即使是在非常有利的域中)。假设在河流的任何图像中,水体将从图像的一端延伸到另一端,任何包含的边界框几乎总是覆盖图像的大部分。因此,河流非常不同部分的边界框提示看起来非常相似。理论上,这意味着边界框为模型提供的信息比控制点少得多;因此,导致性能较差。

控制点、边界框提示和叠加在两个样本训练图像上的真实分割
请注意,在上图中,尽管两条河流部分的真实分割掩码完全不同,但它们各自的边界框几乎相同,而它们的点提示(相对而言)差异更大。
另一个需要考虑的重要因素是在推理时生成输入提示的容易程度。如果您希望在循环执行阶段有人工介入,那么请注意边界框和控制点在推理阶段都是相当琐碎的。然而,如果您打算使用一个完全自动化的架构方案,那么回答这些问题将变得更加复杂。
无论是使用控制点还是边界框,生成提示通常首先包括估计感兴趣对象的粗略掩码。边界框可以只是包裹粗略掩码的最小框,而控制点需要从粗略掩码中采样。这意味着,当真实值掩码未知时,边界框更容易获得,因为感兴趣对象的估计掩码只需要大致匹配真实对象的相同大小和位置;而对于控制点,估计掩码将需要更紧密地匹配对象的轮廓。
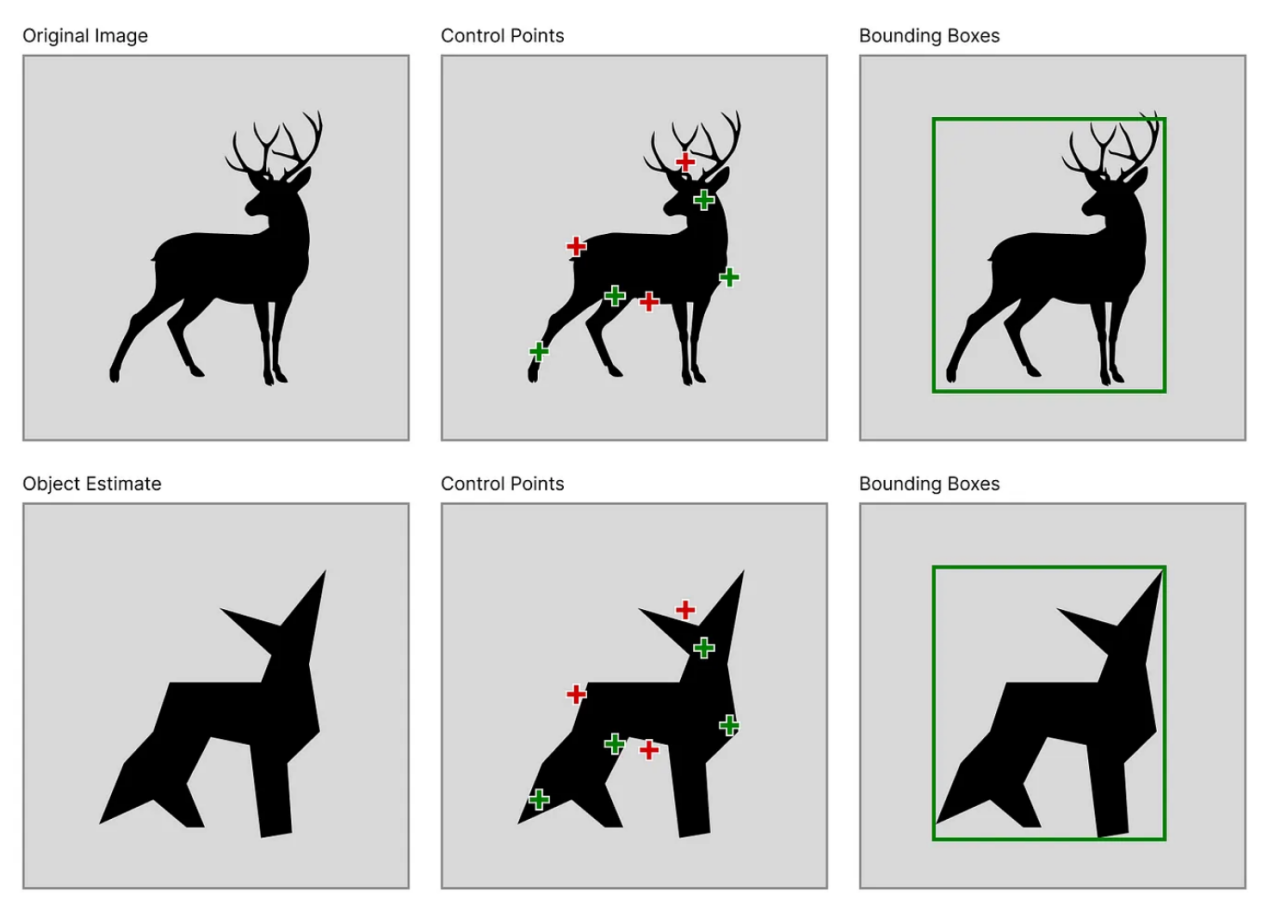
当使用估计的掩码而不是真实值时,控制点的放置可能包括错误标注的点,而边界框通常位于正确的位置
对于河流分割,如果我们可以同时使用RGB和NIR,那么我们可以使用光谱指数阈值方法来获得我们的粗略掩模。如果我们只能使用RGB模式,我们可以将图像转换为HSV模式,并对特定色调、饱和度和值范围内的所有像素设置阈值。然后,我们可以移除低于特定大小阈值的连接内容,并使用skimage.morphology子模块中的erosion函数来确保我们的掩模中只有1个像素是朝向蓝色大斑点中心的像素。
模型训练
为了训练我们的模型,我们需要一个包含所有训练数据的数据加载器,我们可以在每个训练时期对这些数据进行迭代。当我们从HuggingFace加载数据集时,它采用datasets.Dataset类的形式。如果数据集是私有的,请确保首先安装HuggingFace CLI并使用“!huggingface-cli login”方式登录。
from datasets import load_dataset, load_from_disk, Dataset
hf_dataset_name = "stodoran/elwha-segmentation-v1"
training_data = load_dataset(hf_dataset_name, split="train")
validation_data = load_dataset(hf_dataset_name, split="validation")然后,我们需要编写自己的自定义数据集类,该类不仅返回任何索引的图像和标签,还返回提示词信息。下面是一个可以同时处理控制点和边界框提示的实现。要完成初始化工作,需要一个HuggingFace datasets.Dataset实例和SAM模型的处理器实例。
from torch.utils.data import Dataset
class PromptType:
CONTROL_POINTS = "pts"
BOUNDING_BOX = "bbox"
class SAMDataset(Dataset):
def __init__(
self,
dataset,
processor,
prompt_type = PromptType.CONTROL_POINTS,
num_positive = 3,
num_negative = 0,
erode = True,
multi_mask = "mean",
perturbation = 10,
image_size = (1024, 1024),
mask_size = (256, 256),
):
#将所有值赋给self
...
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
datapoint = self.dataset[idx]
input_image = cv2.resize(np.array(datapoint["image"]), self.image_size)
ground_truth_mask = cv2.resize(np.array(datapoint["label"]), self.mask_size)
if self.prompt_type == PromptType.CONTROL_POINTS:
inputs = self._getitem_ctrlpts(input_image, ground_truth_mask)
elif self.prompt_type == PromptType.BOUNDING_BOX:
inputs = self._getitem_bbox(input_image, ground_truth_mask)
inputs["ground_truth_mask"] = ground_truth_mask
return inputs我们还必须定义SAMDataset_getitem_ctrlpts和SAMDataset_getitem_box函数,尽管如果您只计划使用一种提示类型,那么您可以重构代码以直接处理SAMDataset.__getitem__中的该类型,并删除帮助类工具函数。
class SAMDataset(Dataset):
...
def _getitem_ctrlpts(self, input_image, ground_truth_mask):
# 获取控制点提示。请参阅GitHub获取该函数的源代码,或将其替换为您自己的点选择算法。
input_points, input_labels = generate_input_points(
num_positive=self.num_positive,
num_negative=self.num_negative,
mask=ground_truth_mask,
dynamic_distance=True,
erode=self.erode,
)
input_points = input_points.astype(float).tolist()
input_labels = input_labels.tolist()
input_labels = [[x] for x in input_labels]
# 为模型准备图像和提示。
inputs = self.processor(
input_image,
input_points=input_points,
input_labels=input_labels,
return_tensors="pt"
)
#删除处理器默认添加的批次维度。
inputs = {k: v.squeeze(0) for k, v in inputs.items()}
inputs["input_labels"] = inputs["input_labels"].squeeze(1)
return inputs
def _getitem_bbox(self, input_image, ground_truth_mask):
#获取边界框提示。
bbox = get_input_bbox(ground_truth_mask, perturbation=self.perturbation)
#为模型准备图像和提示。
inputs = self.processor(input_image, input_boxes=[[bbox]], return_tensors="pt")
inputs = {k: v.squeeze(0) for k, v in inputs.items()} # 删除处理器默认添加的批次维度。
return inputs将所有这些功能组合到一起,我们可以创建一个函数,该函数在给定HuggingFace数据集的任一部分的情况下创建并返回PyTorch数据加载器。编写返回数据加载器的函数,而不仅仅是用相同的代码执行单元,这不仅是编写灵活和可维护代码的好方法,而且如果您计划使用HuggingFace Accelerate(https://huggingface.co/docs/accelerate/index)来运行分布式训练的话,这也是必要的。
from transformers import SamProcessor
from torch.utils.data import DataLoader
def get_dataloader(
hf_dataset,
model_size = "base", # One of "base", "large", or "huge"
batch_size = 8,
prompt_type = PromptType.CONTROL_POINTS,
num_positive = 3,
num_negative = 0,
erode = True,
multi_mask = "mean",
perturbation = 10,
image_size = (256, 256),
mask_size = (256, 256),
):
processor = SamProcessor.from_pretrained(f"facebook/sam-vit-{model_size}")
sam_dataset = SAMDataset(
dataset=hf_dataset,
processor=processor,
prompt_type=prompt_type,
num_positive=num_positive,
num_negative=num_negative,
erode=erode,
multi_mask=multi_mask,
perturbation=perturbation,
image_size=image_size,
mask_size=mask_size,
)
dataloader = DataLoader(sam_dataset, batch_size=batch_size, shuffle=True)
return dataloader在此之后,训练只需加载模型、冻结图像和提示编码器,并进行所需次数的迭代训练。
model = SamModel.from_pretrained(f"facebook/sam-vit-{model_size}")
optimizer = AdamW(model.mask_decoder.parameters(), lr=learning_rate, weight_decay=weight_decay)
# Train only the decoder.
for name, param in model.named_parameters():
if name.startswith("vision_encoder") or name.startswith("prompt_encoder"):
param.requires_grad_(False)以下列出的是训练过程循环部分的基本框架代码。请注意,为了简洁起见,forward_pass、calculate loss、evaluate_mode和save_model_checkpoint函数被省略了,但GitHub上提供了实现。正向传递码根据提示类型略有不同,损失计算也需要基于提示类型的特殊情况;当使用点提示时,SAM模型为每个单个输入点返回一个预测掩码,因此为了获得可以与真实数据进行比较的单个掩码,需要对预测掩码进行平均,或者需要选择最佳预测掩码(基于SAM的预测IoU分数来识别)。
train_losses = []
validation_losses = []
epoch_loop = tqdm(total=num_epochs, position=epoch, leave=False)
batch_loop = tqdm(total=len(train_dataloader), position=0, leave=True)
while epoch < num_epochs:
epoch_losses = []
batch_loop.n = 0 #循环重置
for idx, batch in enumerate(train_dataloader):
# 正向传递
batch = {k: v.to(accelerator.device) for k, v in batch.items()}
outputs = forward_pass(model, batch, prompt_type)
#计算损失值
ground_truth_masks = batch["ground_truth_mask"].float()
train_loss = calculate_loss(outputs, ground_truth_masks, prompt_type, loss_fn, multi_mask="best")
epoch_losses.append(train_loss)
# 反向传递与优化环节
optimizer.zero_grad()
accelerator.backward(train_loss)
optimizer.step()
lr_scheduler.step()
batch_loop.set_description(f"Train Loss: {train_loss.item():.4f}")
batch_loop.update(1)
validation_loss = evaluate_model(model, validation_dataloader, accelerator.device, loss_fn)
train_losses.append(torch.mean(torch.Tensor(epoch_losses)))
validation_losses.append(validation_loss)
if validation_loss < best_loss:
save_model_checkpoint(
accelerator,
best_checkpoint_path,
model,
optimizer,
lr_scheduler,
epoch,
train_history,
validation_loss,
train_losses,
validation_losses,
loss_config,
model_descriptor=model_descriptor,
)
best_loss = validation_loss
epoch_loop.set_description(f"Best Loss: {best_loss:.4f}")
epoch_loop.update(1)
epoch += 1微调结果分析
对于艾尔瓦河项目,最佳设置是在不到12小时的时间内使用GCP虚拟机实例,使用超过1k个分割掩码的数据集训练成功“sam-vit-base”模型。
与基准型SAM相比,微调显著提高了性能,中值掩码从不可用变为高度准确。
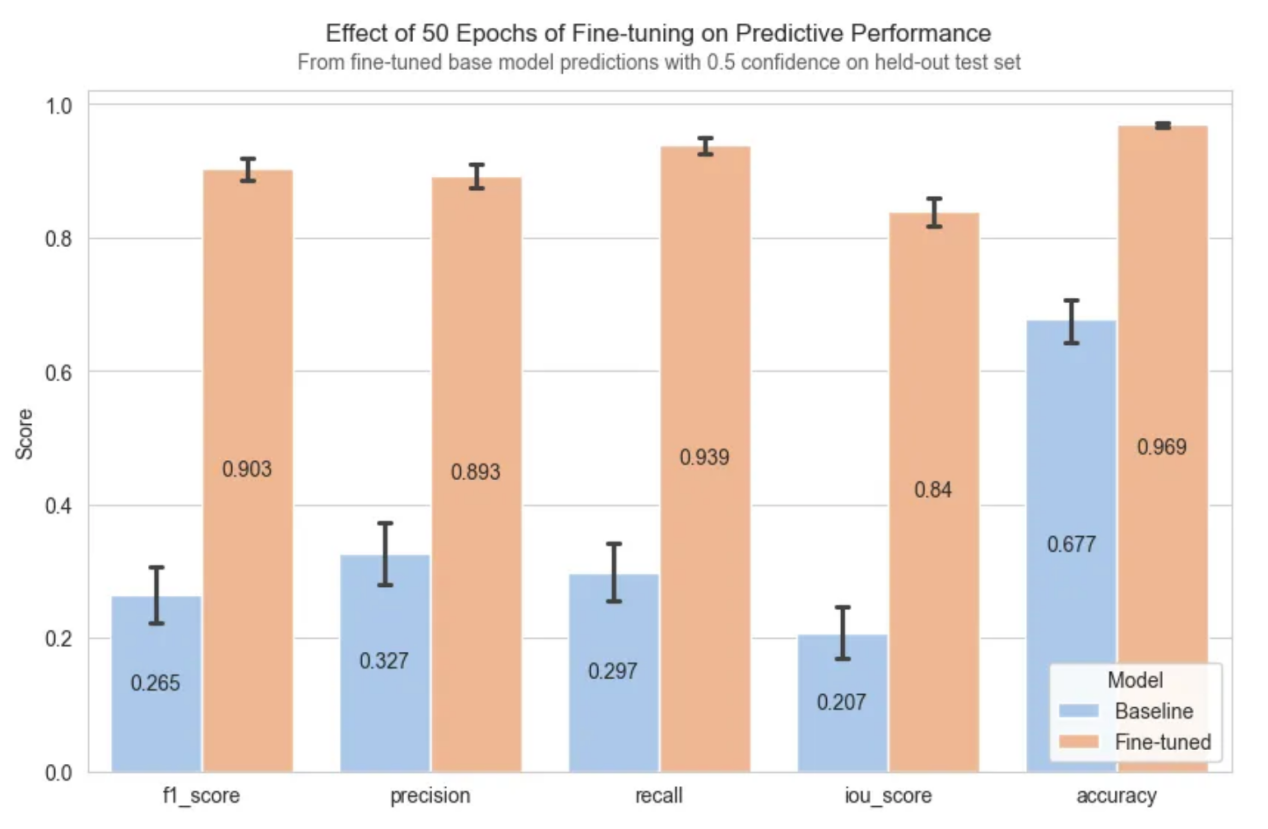
相对于基于默认提示词的基准型SAM模型,微调后的SAM模型极大地提高了分割性能
需要注意的一个重要事实是,1k河流图像的训练数据集是不完美的,分割标签在正确分类的像素数量上变化很大。因此,上述指标是在225幅河流图像的像素完美数据集上计算出来的。
实验过程中,我们观察到的一个有趣的行为是,模型学会了从不完美的训练数据中进行归纳。当在训练样本包含明显错误分类的数据点上进行评估时,我们可以观察到模型预测避免了误差。请注意,显示训练样本的顶行中的图像包含的掩码不会一直填充到河岸,而显示模型预测的底行则更紧密地分割河流边界。

即使训练数据不完美,经微调的SAM模型也能带来令人印象深刻的泛化效果。请注意,与训练数据(顶行)相比,预测(底行)的错误分类更少,并且河流的填充程度更高。
结论
如果您已经顺利完成本文中的实例内容,那么祝贺您!您已经学会了为任何下游愿景任务完全微调Meta的分割一切模型SAM所需的一切!
虽然您的微调工作流程无疑与本教程中介绍的实施方式不同,但从阅读本教程中获得的知识不仅会影响到您的细分项目,还会影响到未来的深度学习项目及其他项目。
最后,希望您继续探索机器学习的世界,保持好奇心,并一如既往地快乐编程!
附录
本文实例中使用的数据集是Elwha V1数据集(https://huggingface.co/datasets/stodoran/elwha-segmentation-v1),该数据集由华盛顿大学的GeoSMART研究实验室(https://geo-smart.github.io/)创建,用于将微调的大型视觉变换器应用于地理空间分割任务的研究项目。本文描述的内容代表了即将发表的论文的精简版和一个更易于实现的版本。在高水平上,Elwha V1数据集由SAM检查点的后处理模型预测组成,该检查点使用Buscombe等人(https://zenodo.org/records/10155783)发布并在多学科研究数据知识库和文献资源网站Zenodo上发布的标注正射影像的子集进行了微调。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Learn Transformer Fine-Tuning and Segment Anything,作者:Stefan Todoran
链接:https://towardsdatascience.com/learn-transformer-fine-tuning-and-segment-anything-481c6c4ac802





















