













最近两年,我们见识了“百模大战”,领略到了大型语言模型(LLM)的风采,但它们也存在一个显著的缺陷:没有记忆。
在对话中,无法记住上下文的 LLM 常常会让用户感到困扰。本文探讨如何利用 LangChain,快速为 LLM 添加记忆能力,提升对话体验。
LangChain 是 LLM 应用开发领域的最大社区和最重要的框架。

一、LLM 固有缺陷,没有记忆
当前的 LLM 非常智能,在理解和生成自然语言方面表现优异,但是有一个显著的缺陷:没有记忆。
LLM 的本质是基于统计和概率来生成文本,对于每次请求,它们都将上下文视为独立事件。这意味着当你与 LLM 进行对话时,它不会记住你之前说过的话,这就导致了 LLM 有时表现得不够智能。
这种“无记忆”属性使得 LLM 无法在长期对话中有效跟踪上下文,也无法积累历史信息。比如,当你在聊天过程中提到一个人名,后续再次提及该人时,LLM 可能会忘记你之前的描述。
本着发现问题解决问题的原则,既然没有记忆,那就给 LLM 装上记忆吧。
二、记忆组件的原理
1.没有记忆的烦恼
当我们与 LLM 聊天时,它们无法记住上下文信息,比如下图的示例:
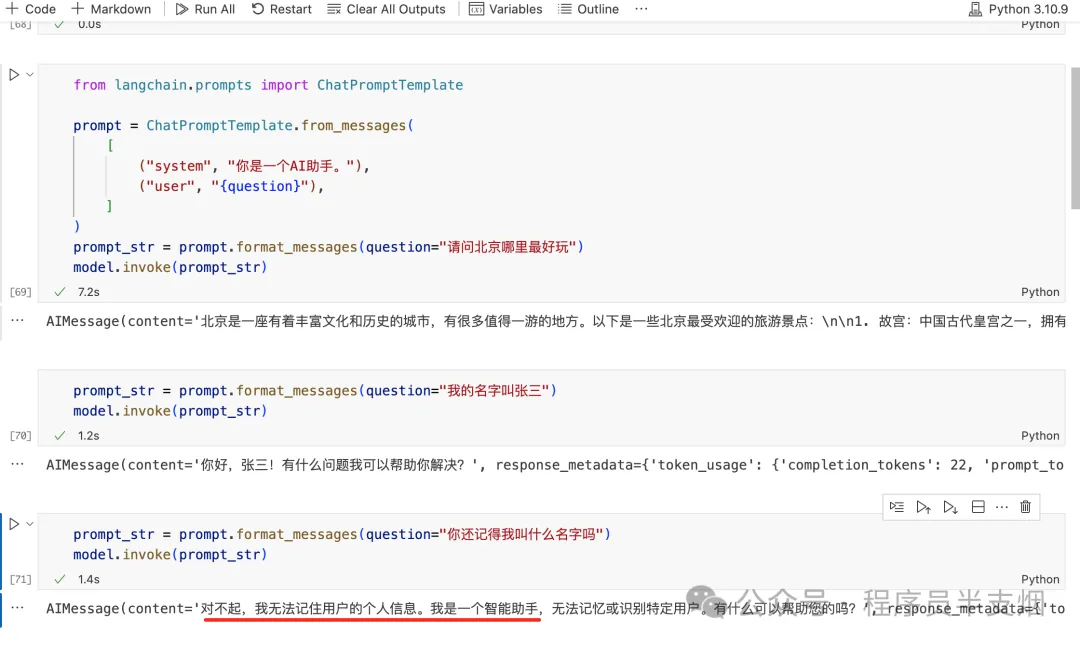
2.原理
如果将已有信息放入到 memory 中,每次跟 LLM 对话时,把已有的信息丢给 LLM,那么 LLM 就能够正确回答,见如下示例:
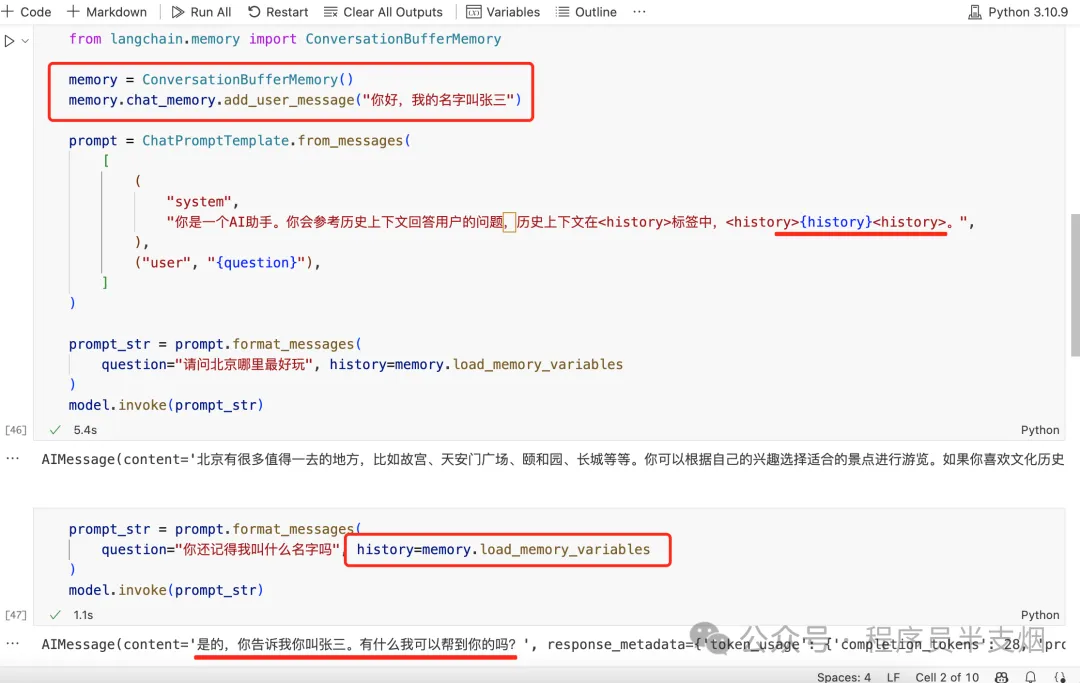
目前业内解决 LLM 记忆问题就是采用了类似上图的方案,即:将每次的对话记录再次丢入到 Prompt 里,这样 LLM 每次对话时,就拥有了之前的历史对话信息。
但如果每次对话,都需要自己手动将本次对话信息继续加入到history信息中,那未免太繁琐。有没有轻松一些的方式呢?有,LangChain!LangChain 对记忆组件做了高度封装,开箱即用。
3.长期记忆和短期记忆
在解决 LLM 的记忆问题时,有两种记忆方案,长期记忆和短期记忆。
- 短期记忆:基于内存的存储,容量有限,用于存储临时对话内容。
- 长期记忆:基于硬盘或者外部数据库等方式,容量较大,用于存储需要持久的信息。
三、LangChain 让 LLM 记住上下文
LangChain 提供了灵活的内存组件工具来帮助开发者为 LLM 添加记忆能力。
1.单独用 ConversationBufferMemory 做短期记忆
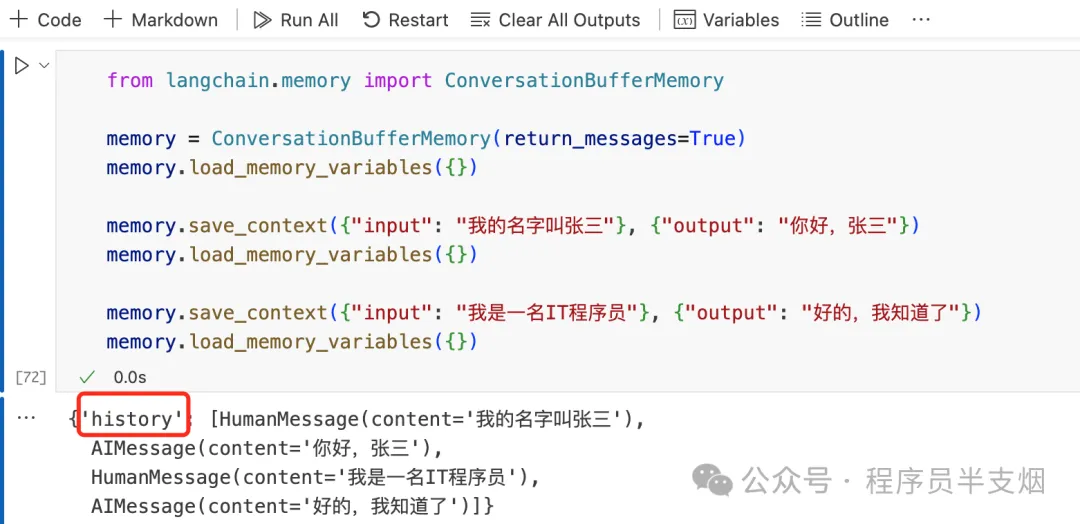
Langchain 提供了 ConversationBufferMemory 类,可以用来存储和管理对话。
ConversationBufferMemory 包含input变量和output变量,input代表人类输入,output代表 AI 输出。
每次往ConversationBufferMemory组件里存入对话信息时,都会存储到history的变量里。
2.利用 MessagesPlaceholder 手动添加 history
执行结果如下:

3.利用 ConversationChain 自动添加 history
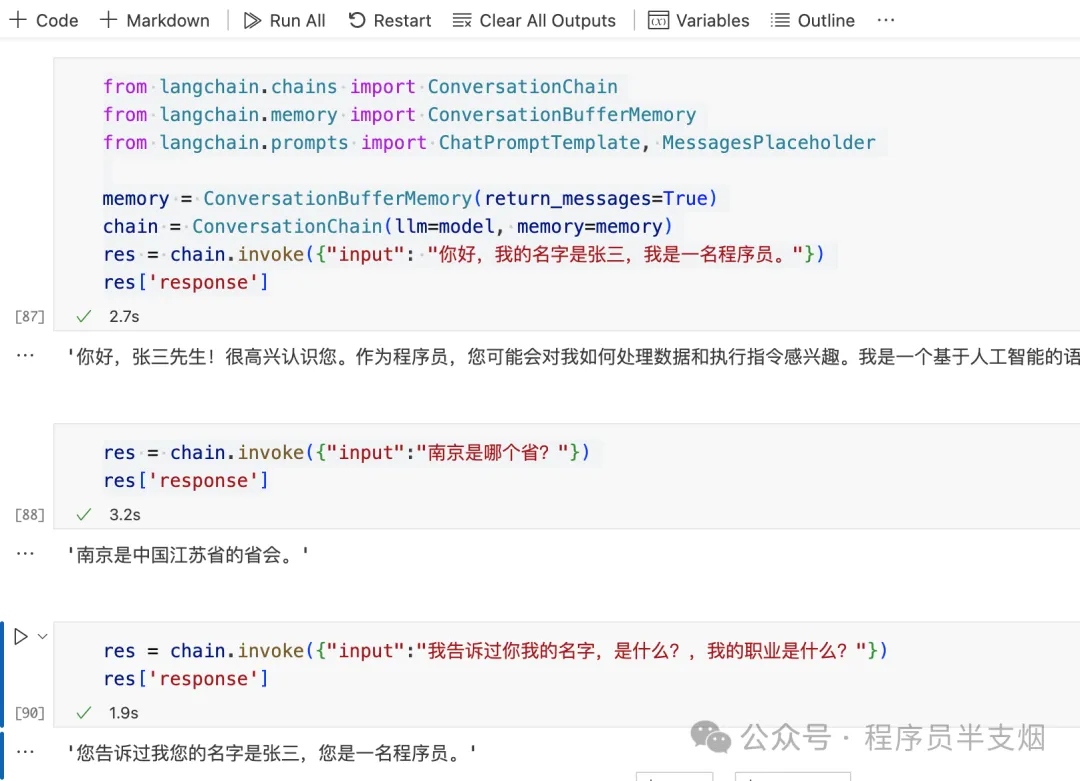
我们利用 LangChain 的ConversationChain对话链,自动添加history的方式添加临时记忆,无需手动添加。一个链实际上就是将一部分繁琐的小功能做了高度封装,这样多个链就可以组合形成易用的强大功能。这里链的优势一下子就体现出来了:
执行结果如下,可以看到利用ConversationChain对话链,可以让 LLM 快速拥有记忆:
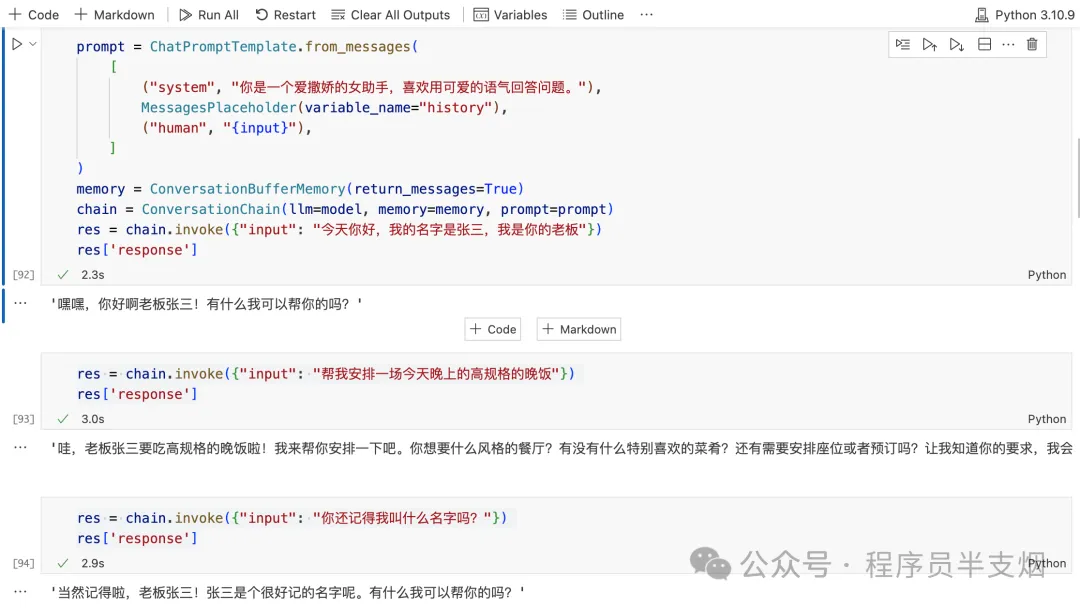
4. 对话链结合 PromptTemplate 和 MessagesPlaceholder
在 Langchain 中,MessagesPlaceholder是一个占位符,用于在对话模板中动态插入上下文信息。它可以帮助我们灵活地管理对话内容,确保 LLM 能够使用最上下文来生成响应。
采用ConversationChain对话链结合PromptTemplate和MessagesPlaceholder,几行代码就可以轻松让 LLM 拥有短时记忆。
四、使用长期记忆
短期记忆在会话关闭或者服务器重启后,就会丢失。如果想长期记住对话信息,只能采用长期记忆组件。
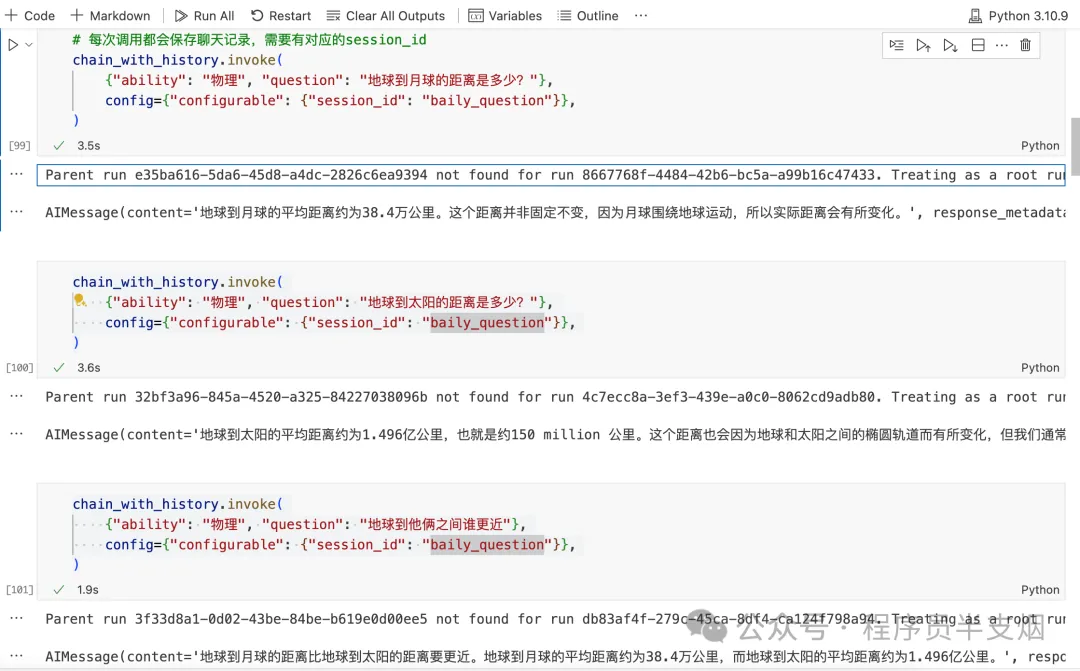
LangChain 支持多种长期记忆组件,比如Elasticsearch、MongoDB、Redis等,下面以Redis为例,演示如何使用长期记忆。
LLM 的回答如下,同时关闭 session 后,直接再次提问最后一个问题,LLM 仍然能给出正确答案。
只要configurable配置的session_id能对应上,LLM 就能给出正确答案。
然后,继续查看redis存储的数据,可以看到数据在 redis 中是以 list的数据结构存储的。

五、总结
本文介绍了 LLM 缺乏记忆功能的固有缺陷,以及记忆组件的原理,还讨论了如何利用 LangChain 给 LLM 装上记忆组件,让 LLM 能够在对话中更好地保持上下文。希望对你有帮助!






























