












译者 | 李睿
审校 | 重楼
深入研究不同的搜索技术

为了设定场景,假设有一系列关于各种技术主题的文本,并希望查找与“机器学习” (Machine Learning)相关的信息。接下来将研究关键字搜索、相似性搜索和语义搜索如何提供不同程度的深度和理解,从简单的关键字匹配到识别相关概念和场景。
首先看看程序使用的标准代码组件。
1.使用的标准代码组件
A.导入的库
Python
import os
import re
from whoosh.index import create_in
from whoosh.fields import Schema, TEXT
from whoosh.qparser import QueryParser
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from transformers import pipeline
import numpy as np
在这个块中导入了以下必要的库:
- os用于文件系统的操作。
- re表示正则表达式。
- whoosh用于创建和管理搜索索引。
- scikit-learn用于TF-IDF矢量化和相似度计算。
- transformers使用深度学习模型进行特征提取。
- numpy用于数值运算,特别是排序。
B.文档初始化样例
Python
# Sample documents used for demonstrating all three search techniques
documents = [
"Machine learning is a field of artificial intelligence that uses statistical techniques.",
"Natural language processing (NLP) is a part of artificial intelligence that deals with the interaction between computers and humans using natural language. ",
"Deep learning models are a subset of machine learning algorithms that use neural networks with many layers.",
"AI is transforming the world by automating tasks, providing insights through data analysis, and enabling new technologies like autonomous vehicles and advanced robotics. ",
"Natural language processing can be challenging due to the complexity and variability of human language. ",
"The application of machine learning in healthcare is revolutionizing the way diseases are diagnosed and treated.",
"Autonomous vehicles rely heavily on AI and machine learning to navigate and make decisions.",
"Speech recognition technology has advanced considerably thanks to deep learning models. "
]
定义一个示例文档列表,其中包含与人工智能、机器学习和自然语言处理中的各种主题相关的文本。
C.高亮功能
Python
def highlight_term(text, term):
return re.sub(f"({term})", r'\033[1;31m\1\033[0m', text, flags=re.IGNORECASE)
用于美化输出,以突出显示文本中的搜索词。
2.关键字搜索
将搜索查询与文档中找到的精确或部分关键字相匹配的传统方法。
严重依赖于精确的词匹配和简单的查询操作符(AND、OR、NOT)。
A.关键字搜索如何工作
由于搜索查询是“机器学习”(Machine Learning),因此关键字搜索会查找精确的文本匹配,并且只返回包含“机器学习”(Machine Learning)的文本。一些将被返回的文本示例是“机器学习正在改变许多行业。”“最近开设了一门机器学习的课程。”
B.检查关键字搜索背后的代码
Python
# Function for Keyword Search using Whoosh
def keyword_search(query_str):
schema = Schema(content=TEXT(stored=True))
if not os.path.exists("index"):
os.mkdir("index")
index = create_in("index", schema)
writer = index.writer()
for doc in documents:
writer.add_document(content=doc)
writer.commit()
with index.searcher() as searcher:
query = QueryParser("content", index.schema).parse(query_str)
results = searcher.search(query)
highlighted_results = [(highlight_term(result['content'], query_str), result.score) for result in results]
return highlighted_results使用了Whoosh库来执行关键字搜索。
Schema和TEXT采用单个字段内容定义模式。
- os.path.exists和os.path.existsmkdir:检查索引目录是否存在,如果不存在则创建它。
- create_in:在名为index的目录中建立索引。
- writer:打开一个写入器,将文档添加到索引中。
- add_document:向索引中添加文档。
- commit:将更改提交到索引。
- with index.searcher():打开一个搜索器来搜索索引。
- QueryParser:解析查询字符串。
- searcher.search:使用解析后的查询搜索索引。
- highlighted_results:高亮显示结果中的搜索词,并存储结果及其分数。
将在本文后面检查关键字搜索输出和其他搜索技术。
3.相似性搜索
该方法根据相关单词或主题的存在等特征,将提供的文本与其他文本进行比较,从而找到与搜索查询相似的文本。
A.相似性搜索的工作原理
回到之前相同的搜索查询“机器学习”,相似度搜索将返回概念上类似的文本,例如“医疗保健中的人工智能应用使用机器学习技术”和“预测建模通常依赖于机器学习”。
B.检查相似度搜索背后的代码
Python
# Function for Similarity Search using Scikit-learn
def similarity_search(query_str):
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
query_vec = vectorizer.transform([query_str])
similarity = cosine_similarity(query_vec, tfidf_matrix)
similar_docs = similarity[0].argsort()[-3:][::-1] # Top 3 similar documents
similarities = similarity[0][similar_docs]
highlighted_results = [(highlight_term(documents[i], query_str), similarities[idx]) for idx, i in enumerate(similar_docs)]
return highlighted_results使用Scikit-learn库编写了一个函数来执行相似性搜索。
- TfidfVectorizer:将文档转换为TF-IDF功能。
- fit_transform:它将矢量器适配到文档中,并将文档转换为TF-IDF矩阵。Fit从文档列表中学习词汇表,并识别唯一的单词,以计算它们的TF和IDF值。
- transform:使用在fit步骤中学习的相同词汇表和统计信息,将查询字符串转换为TF-IDF向量。
- cosine_similarity:计算查询向量和TF-IDF矩阵之间的余弦相似度。
- argsort()[-3:][::-1]:按相似度降序获取前3个相似文档的索引。这一步只与本文相关,如果不想将搜索结果限制在前3名,可以取消这一步骤。
- highlighted_results:高亮显示结果中的搜索词,并存储结果及其相似性得分。
4.语义搜索
现在进入了强大搜索技术的领域。此方法理解搜索词的含义/场景,并使用该概念返回文本,即使没有直接提到搜索词。
A.语义搜索如何工作
同样的搜索查询“机器学习”(Machine Learning),当与语义搜索一起应用时,会产生与机器学习概念相关的文本,例如“人工智能和数据驱动的决策正在改变行业”和“神经网络是许多人工智能系统的。”
B.检查语义搜索背后的代码
Python
# Function for Semantic Search using Transformers
def semantic_search(query_str):
semantic_searcher = pipeline("feature-extraction", model="distilbert-base-uncased")
query_embedding = semantic_searcher(query_str)[0][0]
def get_similarity(query_embedding, doc_embedding):
return cosine_similarity([query_embedding], [doc_embedding])[0][0]
doc_embeddings = [semantic_searcher(doc)[0][0] for doc in documents]
similarities = [get_similarity(query_embedding, embedding) for embedding in doc_embeddings]
sorted_indices = np.argsort(similarities)[-3:][::-1]
highlighted_results = [(highlight_term(documents[i], query_str), similarities[i]) for i in sorted_indices]
return highlighted_results使用Hugging Face transformers库执行语义搜索的函数。
在semantic_searcher = pipeline("feature-extraction", model="distilbert-base-uncased")代码片段中,有很多操作在进行。
- pipeline:这是从transformer库导入的函数,它帮助使用预训练的模型设置各种类型的NLP任务。
- Feature –extractio:Pipeline执行特征提取(Feature extraction)任务,将文本转换为可用于各种下游任务的数字表示(嵌入)。
- 用于这一任务的预训练模型是distilbert-base-uncased模型,它是BERT模型的一个更小、更快的版本,经过训练以理解不区分大小写的英文文本。
- query_embedding:获取查询字符串的嵌入。
- get_similarity:这是一个嵌套函数,用于计算查询嵌入和文档嵌入之间的余弦相似度。
- doc_embeddings:获取所有文档的嵌入。
- similarities:计算查询嵌入与所有文档嵌入之间的相似度。
- argsort()[-3:][::-1]:按相似度降序获取前3个相似文档的索引。
- highlighted_results:高亮显示结果中的搜索词,并存储结果及其相似度分数。
输出
既然已经了解了各种搜索技术的场景,并且已经设置了文档以进行搜索,现在查看一下基于每个搜索技术的搜索查询的输出。
Python
# Main execution
if __name__ == "__main__":
query = input("Enter your search term: ")
print("\nKeyword Search Results:")
keyword_results = keyword_search(query)
for result, score in keyword_results:
print(f"{result} (Score: {score:.2f})")
print("\nSimilarity Search Results:")
similarity_results = similarity_search(query)
for result, similarity in similarity_results:
print(f"{result} (Similarity: {similarity * 100:.2f}%)")
print("\nSemantic Search Results:")
semantic_results = semantic_search(query)
for result, similarity in semantic_results:
print(f"{result} (Similarity: {similarity * 100:.2f}%)")现在使用搜索词“机器学习”(Machine Learning)和下面的搜索结果图像来搜索文档。

搜索结果中的亮点:
(1)highlighted_results函数帮助高亮搜索词。
(2)相似性搜索和语义搜索只返回3个结果,这是因为其代码将这两种搜索技术的搜索结果限制为3个。
(3)关键词搜索使用TF-IDF根据文档中相对于查询的术语出现的频率和重要性来计算分数。
(4)相似性搜索使用向量化和余弦相似性来度量文档在向量空间中与查询的相似程度。
(5)语义搜索使用来自转换器模型的嵌入和余弦相似度来捕获文档与查询的语义和相关性。
(6)需要注意,由于语义搜索的强大功能,它检索了与自然语言处理相关的文本,因为自然语言处理在的场景中与机器学习更为接近。
现在使用其他搜索词“Artificially Intelligent”和“Artificial Intelligence”的搜索结果(需要注意,“Artificially”的拼写错误是故意的),并讨论结果。
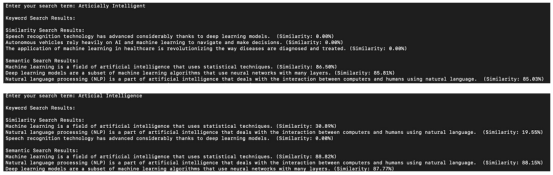
搜索结果中的亮点:
(1)搜索“人工智能”(Artificially Intelligent),由于缺乏精确或部分匹配的术语,关键词搜索没有结果。
(2)由于向量表示或相似度不匹配,相似度搜索的结果为零。
(3)语义搜索可以有效地找到场景相关的文档,显示出理解和匹配概念的能力,而不仅仅是精确的单词。
(4)在第二次搜索中,拼写错误的“人工智能”(Artificial Intelligence)没有正确地产生关键字搜索结果,但由于匹配的情况,其中一个文本产生了相似性得分。在智能、语义搜索方面,像往常一样,从文档中检索到场景匹配的文本。
结论
现在已经了解了各种搜索技术的性能,以下了解一些关键要点:
(1)搜索方法的正确选择应取决于任务的要求。对任务进行彻底的分析,并插入正确的搜索方法以获得最佳性能。
(2)使用关键字搜索进行简单、直接的术语匹配。
(3)当需要查找具有轻微术语变化但仍然基于关键字匹配的文档时,可以使用相似度搜索。
(4)对需要深入理解内容的任务使用语义搜索,例如在处理各种术语或需要捕获查询的底层含义时。
(5)还可以考虑将这些方法结合起来,以实现良好的平衡,利用每种方法的优势来提高总体性能。
(6)每种搜索技术都有进一步优化的余地,本文没有对此进行介绍。
参考文献
以下参考文献的文本已被这个文档用于本文的搜索:
- Is Deep Learning and Machine Learning the Same Thing?
- CloudBank
- What is artificial intelligence?
- AI augmenting human capabilities across the care delivery value chain
- The power of Artificial Intelligence
- ChatGPT and Artificial Intelligence
原文标题:Unlocking the Power of Search: Keywords, Similarity, and Semantics Explained,作者:Pavan Vemuri












