万梓煜是上海交通大学的三年级在读博士生,导师为温颖教授和张伟楠教授,主要研究兴趣为强化学习与大语言模型、决策大模型。冯熙栋是伦敦大学学院四年级博士生,导师为汪军老师。同时目前也是Google DeepMind的student researcher。主要研究方向是强化学习与大语言模型,多智能体以及元强化学习。
2016年 DeepMind 的 AlphaZero 展示了强大的学习和适应能力,登上《自然》杂志封面,并在之后通过自我对弈不断提升自身水平,最终战胜了人类冠军,而这也为之后学者在大语言模型与树搜索的结构化结合奠定了基础。
大语言模型树搜索
大语言模型与思维链(Chain-of-Thought, CoT)的结合增强了其复杂推理能力,使其在数学和逻辑推理等任务上表现更佳。然而,语言模型仍存在误差:一方面,受数据数量和质量的影响,大语言模型在复杂任务上仍与专家系统和求解器有差距;另一方面,仅依靠大语言模型难以解决长程规划(long-horizon planning)任务。
为解决这些问题,研究者提出了将结构化的树/图搜索与大语言模型结合的方式。思维树(Tree of Thought, ToT)模仿人类认知中的慢系统,利用深度/广度优先搜索显著提升大语言模型的规划能力。Reasoning via Planning (RAP) 则将大语言模型的思维链过程视作规划(planning),使用其内在知识进行状态评估,并结合传统蒙特卡洛树搜索(MCTS),从而增强语言模型的性能。这些方法利用大语言模型的多任务能力,通过提示工程(prompt engineering)对中间结果进行价值判断。
然而,这种方法并不普遍适用。评估多步推理问题的中间状态本身也是一个推理子问题,依赖CoT生成评估,无法保证评估的可靠性。此外,语言模型的自我评估能力和逆转诅咒问题,以及子问题难度降低不显著等因素,限制了这类方法的应用效果,尤其是对于较小规模、易部署的模型。
一个潜在的解决方案是参考AlphaZero。2016年,DeepMind通过AlphaZero在复杂多步推理问题如围棋上取得突破性进展。AlphaZero结合了传统MCTS和深度神经网络的优势,使用价值函数学习简化了MCTS中的Simulation/Rollout过程,并通过蒸馏树搜索增强策略的迭代优化,为大语言模型在树搜索评估和长程规划效率问题上提供了方向。
基于此,来自伦敦大学学院,上海交通大学,卡耐基梅隆大学的合作团队将 AlphaZero 方法精髓与大语言模型的文本生成结合,提出了大语言模型树搜索训练增强框架 TSLLM。通过将这一任务建模为多步决策问题,引入强化学习中价值函数学习的概念,以训练的方式微调一个价值函数以提供更为鲁棒可靠的搜索中间价值评估。与此同时在 TSLLM 中也实现了不同树搜索算法的对比,尤其是探究了价值函数结合的简化 MCTS 在不同类型任务上的优缺点。最后,团队探究了由树搜索引导的迭代优化方式对大语言模型进一步优化的可能性。目前,该论文已被ICML 2024接收。

- 论文名称:AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training
- 论文链接:https://arxiv.org/abs/2309.17179
- 代码链接:https://github.com/waterhorse1/LLM_Tree_Search
TSLLM的基本框架如下:

图一:TSLLM 基本框架一览
TSLLM 有如下特点:
- TSLLM 是一个普遍适用和可扩展的框架,通过学习价值函数可应用于几乎任何任务,以及任何大小的语言模型。
- TSLLM 在不同问题上验证了树搜索能增强大语言模型推理阶段表现的同时,也进一步验证了其迭代增强语言模型作为一个语言模型训练新范式的潜力。
- 在设计上,TSLLM 支持逐句/词元细粒度的搜索。
- 使用可靠鲁棒的价值函数作为状态评估,TSLLM 支持包括简单的 BFS/DFS,传统 MCTS,AlphaZero 式的 MCTS-α,MCTS-Rollout 等算法。
- TSLLM进行了全面且公平的对比。例如,为了实现与非搜索算法(如 CoT/CoT-SC)的公平对比,TSLLM 通过统计总体计算量的方式衡量不同算法的效果与效率。
AlphaZero 式的树搜索增强的大语言模型
研究团队将大语言模型的自回归生成过程建模为一个多步决策问题,定义词元/句级的语言生成过程的概率建模。对于给定的自然语言任务,他们通过学习的价值函数估计与最终奖励估计,建模自然语言任务生成过程中的期望回报与稀疏奖励。并通过树搜索的方式在推理与训练阶段增强大语言模型的能力。
大语言模型推理阶段增强:
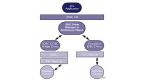
基于学习得到的价值函数,TSLLM 中实现了不同的树搜索算法,从简单的价值函数引导的广度/深度搜索(DFS/BFS-V)到传统 MCTS,该团队基于 AlphaZero 的中间价值回传思想实现了 MCTS-α,以及提出离线搜索变种MCTS-Rollout。下图比较了传统 MCTS 与 AlphaZero 式的 MCTS 的主要区别,如图所示,传统 MCTS 需要通过模拟(Simulation)达到停止节点,才会开始价值回传。另外,在 TSLLM 中,他们还讨论并实现了多条搜索路径的聚合形式,以及提出了考虑计算量的公平比较方式。

图二:传统蒙特卡洛树搜索(左)与AlphaZero 式的蒙特卡洛树搜索(右)对比。
大语言模型迭代训练增强:
最后,在 TSLLM 中,研究团队指出树搜索还能够进一步强化大语言模型本身。他们将结构化搜索作为一个策略增强算子( Policy Improvement Operator),利用这个算子本身,可以迭代式的优化语言模型策略与价值/奖励估计函数。在 TSLLM 中,研究团队类比 AlphaZero/Expert Iteration 中的迭代式优化方法:一方面通过 supervised finetuning 蒸馏这一更好表现的策略分布,而另一方面持续微调价值函数估计。通过这样的方式不断持续增强大语言模型策略本身的任务解决能力与价值函数指导的搜索增强策略的能力。
实验结果
在实验过程中,团队非常重视树搜索算法和基线算法的合理对比。针对于一些算法评估的不合理现象,团队强调了:
- 算法的合理对比。树搜索算法天生会带来更高的计算复杂度,合理的算法对比应在相似的计算量上进行。
- 选择合理基线和设定。例如,团队发现一个经常被忽略的基线算法:Majority-Vote + Outcome Reward Model。实验中团队发现其可以作为简单却非常强大的基线,在GSM8K上甚至可以超过树搜索算法。同时团队严格避免了不合理的实验设定:如利用测试集的真值进行树搜索回溯。
在实验中,团队在数学推理/规划,逻辑推理任务,价值对齐的文本生成以及文本化的决策推理任务上进行了丰富的实验与对比,在搜索深度上最大达到了 64,显著深于之前的算法。

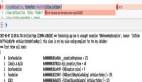
微调学习的价值函数有更可靠、更好的泛化能力:
团队首先就基于学习的价值函数与大语言模型自我评估的方式进行对比。下表实验结果表明基于学习的价值函数无论是在 GSM8k还是 Game24 问题上都优于 ChatGPT,即使在评估 ChatGPT 本身作为策略的中间状态时,表现依旧优于 ChatGPT 本身,充分说明了基于学习的价值函数的可靠性与鲁棒性。

不同的搜索算法具有其不同适应性:
团队比较TSLLM 中不同树搜索算法在类似计算量下的结果,发现 MCTS-α与 MCTS-Rollout的搜索算法主要在长程推理(搜索树深度较大,如 Alignment,Endgame)问题上,显著优于其他搜索算法。但对于轻量级或搜索深度较低的问题,BFS/DFS也具有较强的性能。

树搜索算法的Scaling(扩展)性质受限:
同时,团队也尝试了对树搜索的采样次数进行scaling。结果发现,绝大部分树搜算算法都可以随着路径搜索次数的增加而获得性能提升。但同时团队也发现,一些简单的baseline (如COT-SC+ORM)具有更好的scaling性质。例如在GSM8K中, COT-SC+ORM的baseline可以取得比树搜索更优越的性能与扩展属性。基于这个结果,团队认为如何获得更为优越的扩展性能将成为树搜索算法未来的重要研究方向。

团队的实验也验证了迭代优化可以进一步提升大语言模型的能力:
下文左图展示了 TSLLM 通过 MCTS-α在训练问题集上搜索迭代的结果,在 GSM8k 上相比于初始的策略模型 ,通过一轮树搜索算法的搜索迭代优化后的策略
,通过一轮树搜索算法的搜索迭代优化后的策略 的表现优于在 5、10 倍采样数据上进行 Rejection Sampling 优化的结果;然后也可以发现,在RLHF 数据集上,
的表现优于在 5、10 倍采样数据上进行 Rejection Sampling 优化的结果;然后也可以发现,在RLHF 数据集上, 的表现依旧不如 PPO,这主要是由于 PPO 对语言模型参数进行了多次在线迭代优化。当对比迭代后的价值函数
的表现依旧不如 PPO,这主要是由于 PPO 对语言模型参数进行了多次在线迭代优化。当对比迭代后的价值函数 我们也可以发现,其能够进一步增强
我们也可以发现,其能够进一步增强 的树搜索结果。
的树搜索结果。

总结
总结来说,在这一工作中,研究团队提出了大语言模型的树搜索推理与训练增强框架 TSLLM,在经验结果上强调了可靠中间价值评估的重要性与树搜索算法在不同问题上的效果与效率,验证了 AlphaZero 式的蒙特卡洛树搜索的高效性与进一步迭代优化大语言模型本身的可能。