参与大数据、人工智能相关的项目的技术人员,掌握一些数据工具对项目建设至关重要。本文推荐一些优秀的开源数据分析与可视化工具,可以在从数据清洗到可视化等过程提高工作效率。

1.Apache Superset
https://github.com/apache/superset

Apache Superset是一个开源数据挖掘以及数据可视化平台,用户不需要编程知识就可以创建交互式仪表盘。平台支持各种数据源,提供丰富的可视化组件,并允许自定义仪和共享表盘。
平台在功能性方面,它集成了各种数据库和数据仓库,并提供了一个强大的SQL编辑器。在安全性方面,平台可通过基于角色的访问控制和身份验证。在可扩展性方面,它允许添加自定义功能,并且也有一个大型的、活跃的开源社区。
2.Metabase
https://github.com/metabase/metabase
Metabase是一个开源的商业智能工具,具有友好的用户界面、强大的数据可视化功能和交互式仪表板。它支持与各种数据源集成,支持实时查询,并提供自动报告。
Metabase还提供数据探索和发现工具,通过基于角色的访问控制以确保安全。它可以私有化部署,为项目提供了较为灵活的方案。
3.OpenRefine
https://github.com/OpenRefine/OpenRefine

OpenRefine是一个基于Java的数据管理和分析工具。支持用户使用Web端实现数据加工、可视化和功能扩展。
OpenRefine的主要功能包括挖掘、集群、协调、无限撤销/重做、隐私和Wiki。
4.Insights
https://github.com/mariusandra/insights

Insights是一个用于可视化地挖掘PostgreSQL数据库的工具,在图形的生成具有较强优势。
它支持PostgreSQL连接,自动检测发现数据库,允许连接到多个数据库,并允许模式编辑和添加自定义SQL字段。
它还提供数据挖掘、过滤器、基于时间的图形、键盘导航、保存的视图和固定的字段等功能。
安装如下:
5.Retentioneering
https://github.com/retentioneering/retentioneering-tools

Retentioneering是一个Python库,它主要用于分析点击流、用户轨迹和事件日志变等,并产生比漏斗分析,以便更广泛和更深入理解用户行为。
使用Retentioneering来探索用户行为,细分用户,并形成关于是什么驱使用户采取期望的行动或远离产品的假设。
Retentioneering使用点击流数据来构建行为细分,突出显示影响您的转化率,保留和收入的用户行为中的事件和模式。Retentioneering库是专门为数据分析师、营销分析师、产品所有者、经理以及任何负责提高产品质量的人创建的。

Retentioneering作为Cyberter环境的组成部分,它扩展了pandas、NetworkX、scikit-learn库的功能,以更有效地处理顺序事件数据。Retentioneering优化工具是交互式的,专为分析研究而量身定制,因此,非Python专家也可使用它。只需几行代码,就可以处理数据,探索用户行为地图,并进行可视化。
6.FlyFish

飞鱼(FlyFish)是一个数据可视化编码平台。通过简易的方式快速创建数据模型,通过拖拉拽的形式,快速生成一套数据可视化解决方案。
功能包括:
- 项目管理:项目用于代表具体的业务需求场景,是多个应用、组件的集合。
- 应用开发:支持开发大屏应用,可开发单页面或是多页面路由的大屏应用。
- 组件开发:组件为最小粒度的项目基础,通过创建和开发组件拼凑出最终的可视化大屏展示。
- 模板库:可将开发完成的应用/组件分别上传到对应的模板库中,可在已有模板的基础上快速创建新的项目。
- 数据源管理:可接入 MySQL、Http 等多个数据库数据生成对应数据源,供创建项目时组件对数据进行调用。
- 数据查询:支持根据数据表进行 SQL 查询,精准定位数据源中具体数据并封装保存,也可将查询到的数据重新组合,供组件直接调用。
7.AKShare
https://github.com/akfamily/akshare

AKShare是一个开源财经数据Python接口库,旨在简化获取财务数据的过程。它需要Python(64 bit)3.8或更高版本。
8.Alluxio
https://github.com/Alluxio/alluxio

Alluxio,最初称为Tachyon,是一个虚拟分布式存储系统,将计算应用程序连接到各种存储系统。它起源于加州大学伯克利分校的一个研究项目,现在被许多领先的公司用来管理PB级的数据,最大支持超过3000个部署节点。
9.Flyte
https://github.com/flyteorg/flyte
Flyte是一个开源数据编排器,有助于构建生产级数据和ML管道。它是为可扩展性和可重复性而构建的,利用Kubernetes作为其底层平台。通过Flyte,用户团队可以使用Python SDK构建管道,并将其无缝部署在云和本地环境中,从而实现分布式处理和高效的资源利用。
该平台提供了一个强大的类型引擎,支持用Python或任何其他语言编写代码。此外,Flyte提供了在本地或远程集群上执行模型的能力,提供了高度的可扩展性和易于部署性。
10.Danfo
https://github.com/javascriptdata/danfojs
Danfo是一个受Pandas库启发的JavaScript包,旨在轻松直观地处理关系数据或标记数据。它支持TensorFlow.js ,处理丢失的数据,允许从DataFrame插入/删除列的大小可变性,并提供对象的自动和显式对齐。
特征:
- 支持快速处理Tensorflow.js张量
- 易于处理丢失数据(表示为NaN)
- 大小可变性:可以从DataFrame插入/删除列
- 自动和显式对齐
- 强大、灵活的分组功能
- 从数组、JSON、列表或对象、张量轻松转换为DataFrame对象
- 基于标签的智能切片、花式索引和查询
- 直观的合并和连接数据集
- 用于从平面文件(CSV、Json、Excel)加载数据的强大IO工具
- 用于交互式绘图的强大、灵活和直观的API
- 特定于时间序列的功能:日期范围生成以及日期和时间属性
- 强大的数据预处理功能,如OneHotEncoders、LabelEncoders、StandardScaler和MinMaxScaler
11.Elementary
https://github.com/elementary-data/elementary

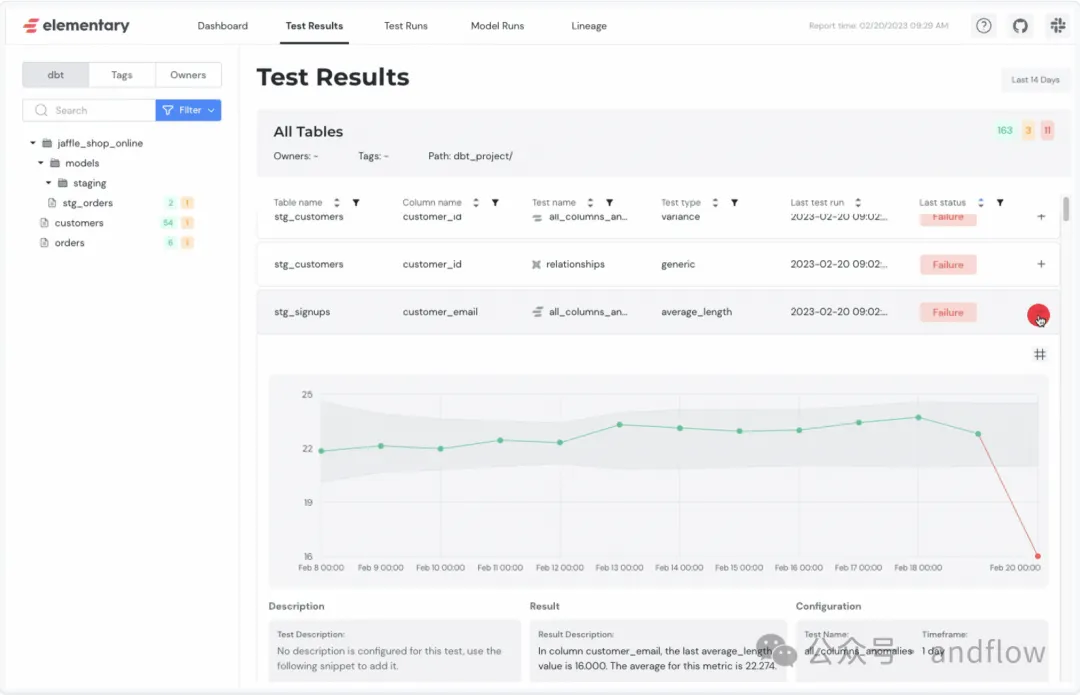

Elementary是一个专为数据和分析工程师设计的首选dbt原生数据可观察性解决方案。可获得分钟级的即时可视化,能够快速检测数据问题,发送可操作的警报,并全面了解可能产生的影响和根本原因。Elementary重点提供了两个产品:一个创新的开源软件包和一个上级管理平台。
主要特征:
- 异常检测测试,收集数据质量指标并检测异常作为本机dbt测试。
- 自动化监视器,开箱即用的云监视器,用于检测新鲜度、卷和模式问题。
- 端到端数据沿袭,获取包含最新测试结果的丰富数据,以分析数据问题的影响和根本原因。Elementary Cloud提供列级血统和BI集成。
- 数据质量仪表板,一个单一的界面,用于所有数据监控和测试结果。
- 模型性能-监视模型和作业随时间的运行结果和性能。
- 基本配置在dbt代码中进行管理。
- 警报,发送可操作的警报,包括自定义频道和所有者标签。
- 数据目录,浏览数据集信息-描述、列、数据集健康状况等。
- dbt工件上传,保存元数据和运行结果的一部分,您的dbt运行。