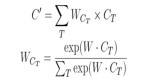引 言
在大多数人生活中,语音是最主要的交流方式。然而,不幸的是,语音质量常受多种因素影响,包括听力损失、背景噪音干扰、设备故障,甚至是某些生理状况导致的语音系统障碍。语音的清晰度则是衡量在特定条件下(如上述影响因素)语音可理解程度的重要标准。
本文探讨了由于生理因素导致的语音质量下降,尤其是在构音障碍的情况下,如何自动估计语音的清晰度水平。文章翻译自《An attention Long Short-Term Memory based system for automatic classification of speech intelligibility》[1]。
构音障碍(dysarthria)是指由于神经病变,与言语有关的肌肉麻痹、收缩力减弱或运动不协调所致的言语障碍,它是一种运动性言语障碍,其特征包括音素发音相关肌肉运动的失控,导致说话速度改变、言语不连贯、音素重复、音量和音调变化过大以及鼻音等症状。这种障碍可能由多种疾病引起,如肿瘤、脑损伤、中风、帕金森病或肌萎缩性侧索硬化症等退行性疾病。
构音障碍不仅阻碍了患者的正常交流,还可能对患者心理造成伤害,因为他们无法有效表达自己的想法和感情。在这种情况下,准确测量语音的清晰度对于治疗和监测手段至关重要,例如评估患者接受特定言语治疗或医疗干预后的效果。
目前,确定语音清晰度的“金标准”包括一系列标准测试,患者在测试中发出特定的单词或声音组合,然后由专家进行主观评估,评估语音的可理解程度。然而,这些测试可能存在主观性问题,因为医生的评估依赖于其听力技能和对病理性言语的熟悉程度,导致可能高估或低估语音清晰度。
为了解决这些问题,本研究旨在开发一种客观、自动且非侵入式的系统,通过分析构音障碍患者的语音来预测其语音清晰度水平(低、中、高)。该系统基于深度学习(DL)范式,特别是基于长短期记忆(LSTM)网络。LSTM 网络与注意力机制结合,能够有效建模每个时间帧对最终决策的贡献,从而提高系统的性能和预测精度。
通过这种方法,自动化测量语音清晰度不仅可以节省医生的时间,使其可以更好地关注其他患者或进行其他医疗活动,还能提供更一致和客观的评估结果。这对于改善言语治疗的效果评估以及促进构音障碍患者的生活质量具有重要意义。
相关工作
先前关于病理性语音清晰度自动预测的研究可分为两大类方法:侵入式或非盲方法,以及非侵入式或盲方法。侵入式方法通常依赖于健康参考语音模型,如高斯混合模型、iVectors或频谱基,通过比较病理性语音与健康模型的差异来评估清晰度。另一种方法假设病理性语音会降低基于健康语音训练的自动语音识别性能,如通过词错误率等特征进行评估。然而,这些方法需要大量平衡的健康数据,这在实际应用中可能限制了其可行性。
非侵入式或盲方法则通常涉及手工特征提取和机器学习算法,如支持向量机或随机森林,用于分析语音特征并预测清晰度水平。这些方法的优势在于不需要健康语音数据,但需要精心设计的特征提取和分类器选择来获得良好的性能。
文章致力于开发一种新型的自动且非侵入式系统,用于评估病理性语音的清晰度水平,特别是在没有健康语音参考数据的情况下。这一创新方法基于深度学习技术,具体使用了长短期记忆网络(LSTM),这些网络能够有效地建模语音信号的时间序列特征。同时,引入注意力模型进一步改善了系统的性能,通过对每个时间帧的重要性进行建模,使得系统能够更精确地预测语音清晰度。
深度学习技术在语音处理领域已经取得了显著进展,例如在自动语音识别、语音情感识别和认知负荷分类中的成功应用。这些技术的高效性和灵活性使它们成为处理复杂语音数据和识别语音障碍的理想工具。通过文中提出的方法,研究人员可以更准确地评估病理性语音的清晰度,从而为言语治疗和医疗干预提供更可靠的评估工具。
总结而言,该文章的创新在于提出了一种基于深度学习和注意力机制的自动语音清晰度评估系统,该系统克服了传统方法中对健康语音数据依赖的限制,并在实验结果中显示出显著的性能优势,这对于未来进一步研究和临床应用具有重要意义。
语音清晰度分类系统
文中开发的两种系统,旨在将说话者的清晰度分为三类:低、中和高。一方面,第一种系统用作参考,包括提取不同的手工声学特征集和 SVM 作为分类器。另一方面,第二种系统,即我们对该任务的提议,使用对数梅尔谱图作为输入,并使用 LSTM 网络进行分类。这两种方法都遵循类似的步骤序列,为了更清晰地了解这项工作,图 1 显示了一个包含这些阶段的框图。
 图 1 语音可理解程度分类系统的框图
图 1 语音可理解程度分类系统的框图
1.预处理
预处理步骤包括对原始音频信号应用语音活动检测器 (VAD),以去除静音/噪声帧。此阶段背后的基本原理是,理论上,非语音帧不会传达有关清晰度水平的信息。但是,正如前面所述,去除非语音区域会对系统的性能产生负面影响。因此,在两种情况下都进行了实验:有 VAD 和没有 VAD。
2.特征提取
对于参考系统,提取了三组不同的声学特征:(i) 梅尔频率倒谱系数 (MFCC) 及其一阶导数;(ii) 调制谱的平均能量;(iii) 在中提出的特征集。对于基于 LSTM 的系统,使用对数梅尔谱图作为声学特征。以下小节中,将简要介绍所有这些特征。
MFCC 及其一阶导数
MFCC是自动语音和说话人识别以及音频分类任务中最流行的特征提取程序。因此,这些参数已针对所考虑的任务进行了尝试。MFCC 是通过对语音信号的对数梅尔谱图应用离散余弦变换 (DCT) 来逐帧提取的。计算出 MFCC 后,将它们的一阶导数添加到最终的声学向量中。
调制谱的平均能量
这组特征源自语音信号的调制谱,该谱测量了语音信号在不同调制频率下的波动。调制谱包含有关病理性语音中可能出现的几种现象的信息,例如非习惯性的强度和速度变化、不精确的共发音或中断和不流畅。
调制谱是通过使用 Falk 等人提出的方法,从音频信号的频谱时间表示中计算出来。其中,对应于每个声学频带的时间包络用特定的调制滤波器组进行滤波,从而获得所谓的调制能量。最终的特征集由这些能量在所有语音帧上的平均值组成。图 2 显示了两个不同语音记录中调制能量平均值的两个示例,其中横轴和纵轴分别表示调制频率和声学频率。可以观察到,对于病理性说话者,调制能量通常高度集中在低调制频率,如图 2 (b) 中的示例所示,而对于高清晰度说话者,调制能量分布在更宽的频率区域,如图 2 (a) 中的示例所示。

图2 (a)高清晰度和(b)低清晰度语音记录的调制频谱的平均能量。这两句话都对应于“jowls”这个词
Falk 的特征
这组声学特征最初是Falk 等人提出的,用于清晰度水平预测。它包含以下六个特征:
零阶 MFCC 一阶导数的标准差。该参数与信号的对数能量相关,可用于检测语音强度中的异常。
线性预测残差的峰度。该特征可以提供有关声音嘶哑、音量损失或声音气喘的信息。
低调制与高调制比率 (LHMR)。该参数是对语音信号调制谱中包含的信息的总结。特别是,它是一个商,比较了低调制频率(小于 4 Hz)和高调制频率(大于 4 Hz)处的调制谱能量。
三个与韵律相关的特征:话语中浊音段的百分比,以及基频的标准差和范围。第一个特征可以提供有关由于发声器官障碍导致的浊音发音异常的信息。第二个和第三个参数有助于检测单调语音(构音障碍的一种症状)以及声音中的颤抖和震颤。
对数梅尔谱图
最后一组特征对应于音频信号的谱图,该谱图首先使用由梅尔尺度滤波器组成的听觉滤波器组映射到梅尔频率间距,然后转换为对数尺度。梅尔尺度是一种频率扭曲,试图模拟人类听觉在不同频率下的非均匀敏感性。
3.分类器
一般的分类器主要分为SVM和LSTM。SVM主要采用一对一策略和高斯核。LSTM 是一种专门设计用于处理序列数据的神经网络架构,具有记忆单元和门控机制,可以有效地处理长期依赖关系。在文章中,作者设计了几种不同的 LSTM 架构来进行分类任务,包括基本 LSTM、LSTM with Mean-Pooling 和 LSTM with Attention-Pooling。
这些 LSTM 架构会接受音频记录中的特征作为输入,并通过训练学习特征之间的关系,从而对音频记录进行分类。训练过程中,使用了随机梯度下降和 Adam 优化方法来调整网络参数,以使模型能够更好地拟合数据。此外,在某些架构中还实施了 dropout 技术,以减少过度拟合现象。
在实现 LSTM with Attention-Pooling 架构时,还引入了注意力机制,用于动态地计算每个 LSTM 帧的权重,以便更加关注对分类任务有重要影响的帧。这有助于提高模型的性能和准确率。
实 验
1.数据库
用于实验的数据集是 UA-Speech 数据库,包含 15 人患有不同程度构音障碍和 13 名健康对照组人员的录音。音频以 16 KHz 频率使用 7 个麦克风录制,包括数字、计算机命令、简单词语、复杂词语和无线电字母表。数据库中的语音根据专家听录音并写下理解的单词百分比进行医学测试,得到清晰度得分,范围为 0 到 100,经修改后分为低清晰度、中等清晰度和高清晰度三个类别。实验未使用健康对照组的音频,仅考虑第六个麦克风上的语音信号,总文件数量为 9,140 个。实验以说话者无关方式配置,训练集、验证集和测试集中包含不同的说话者,避免模型学习说话者身份或环境声学条件而非清晰度水平。
2.预处理和特征提取
在预处理阶段,对语音信号进行分帧和加窗,并使用 VAD(语音活动检测)来去除静音片段。特征提取方面,参考系统使用了三种特征:MFCC 和其一阶导数、调制谱的平均能量以及 Falk’s features。LSTM 系统则使用 log-mel spectrogram 特征,该特征包含 32 个 log-Mel 滤波器能量,每 10 毫秒计算一次。
3.分类器
参考系统使用 SVM 分类器,采用 one-vs-all 策略和高斯核函数。LSTM 系统则使用了三种不同的 LSTM 架构:Basic LSTM、LSTM Mean-Pooling 和 LSTM Attention-Pooling。
4.结果
实验结果表明,LSTM 系统在该任务中取得了更好的性能,特别是 LSTM Attention-Pooling 架构,其准确率达到了 76.97%±0.28%,显著优于参考系统。Mean-Pooling 策略进一步也提升了 LSTM 模型的性能,表明 LSTM 框架中的所有帧都包含有价值的信息,不应完全舍弃。而注意力机制通过学习语音片段的重要性,进一步提升了 LSTM 模型的性能,表明该机制在处理语音清晰度分类任务中具有显著的优势。最后,VAD 预处理步骤对于语音清晰度分类任务的性能提升并不显著,甚至可能导致性能下降。这表明沉默片段和语音中的其他人工制品(如口吃或犹豫)可能包含有关语音清晰度的重要信息。
 图片
图片
表:基于lstm的分类器实现的分类率[%]
结论
研究表明,基于 LSTM 网络和 log-mel 谱图的自动语音清晰度分类系统,结合注意力机制,能够有效地预测语音清晰度水平。该系统在性能上显著优于传统的 SVM 模型,并展现出良好的应用前景。
参考文献
1. Fernández-Díaz M, Gallardo-Antolín A. An attention Long Short-Term Memory based system for automatic classification of speech intelligibility[J]. Engineering Applications of Artificial Intelligence, 2024, 96: 103976.