今天来聊两个问题:
- 如果缓冲池(buffer pool)满了,哪些数据页(page)要刷盘,哪些数据页不刷盘?
- 数据库崩了,怎么利用检查点(checkpoint)与预写日志恢复数据?

问题一:缓冲池满时的刷盘策略
首先来回顾一下《预写日志WAL的核心思路...》中相关的一些知识点:
- 检查点记录了某一个时刻,缓冲池中所有数据页的状态信息;
- 预写日志(write-ahead logging,WAL)中记录了,事务在执行过程中,对数据库进行的所有写操作;
- 日志序列号(log sequence number,LSN),可以标识所有操作序列时序的依据;
再来介绍两个新的知识点:
其一,在数据库中,需要存储一个信息:flushed-LSN:预写日志已刷盘的最大LSN。
画外音:这是日志刷盘。
其二,每个数据页X,还要包含两个信息:
- page-LSN:最近修改数据页的LSN。画外音:每一页数据,都会存储这个LSN。
- rec-LSN:上次刷盘以来,最早修改数据页的LSN。画外音:每一页数据,也会存储这个LSN。
这是两个边界LSN。
也就是说,在[rec-LSN, page-LSN]之间的所有操作,都将这一页数据变成了脏数据。
画外音:这是数据页刷盘。
如果flushed-LSN >= page-LSN(X)
说明:我们可以将页面X刷到磁盘上,因为在那之前的所有日志,都已经刷到了磁盘上。
画外音:这是WAL原则,先刷日志,才能刷数据。
反之,如果flushed-LSN =< page-LSN(X)
说明:有些对数据页X的操作,还没有被刷到预写日志磁盘上,此时我们不能将数据页X刷到磁盘。
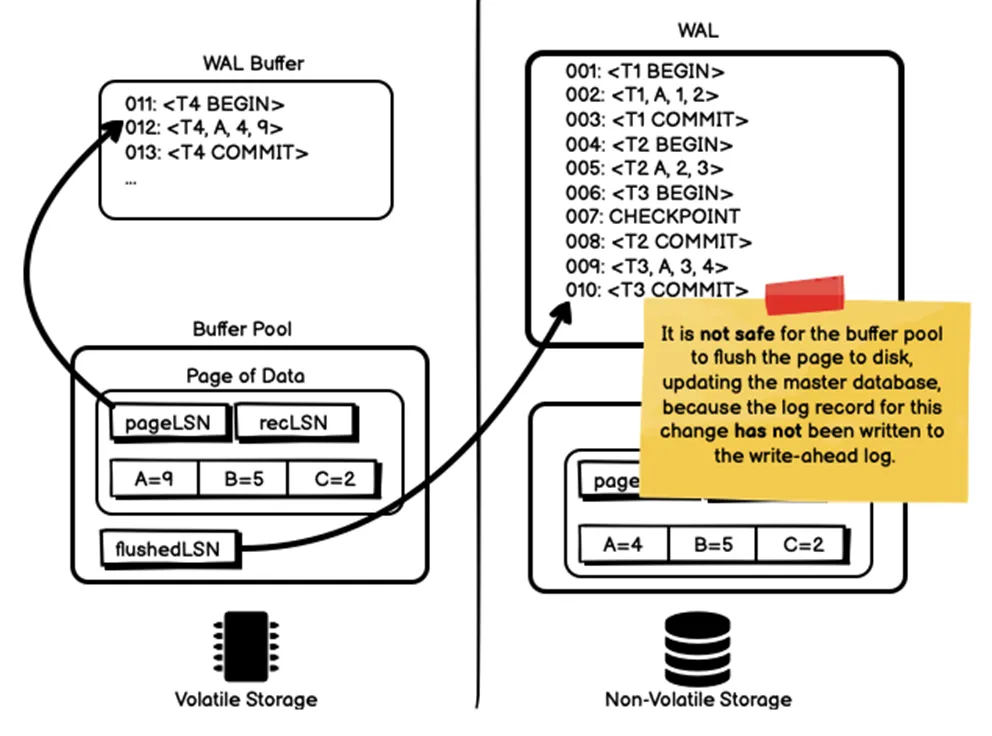
如上图例子所示,共有四个事务:
- T1,将A由1改为2;
- T2,将A由2改为3;
- T3,将A由3改为4;
- T4,将A由4改为9;
对于预写日志来说:
- LSN 001-010都已经刷到磁盘上
- LSN 011-013都还在WAL buffer里
对于数据库来说:
- flushed-LSN=10
- 这是预写日志已刷盘的最大LSN。
对于数据页X来说:
- page-LSN(X)=12
- 数据buffer里,T4已经将A由4改为了9。
此时,flushed-LSN =< page-LSN(X)
于是,我们不能将数据页X刷到磁盘,因为预写日志还没有完成。我们只能刷盘其他数据页,来腾出缓冲池的内存空间哈。
问题二:数据库崩溃时的数据恢复算法
数据库崩溃后,所有内存buffer(WAL buffer以及buffer pool)中的数据都会丢失,我们如何利用检查点与预写日志,对数据进行恢复呢?
最常见故障恢复(crash recovery)算法是ARIES,Algorithms for Recovery and Isolation Exploiting Semantics,语义恢复与隔离算法。
这个算法的核心包含三个阶段:
阶段一,分析阶段:分析预写日志,对事务进行分类。
分析哪些预写日志?
假设刷新检查点日志的时刻是LSN,需要分析所有检查点LSN之后的预写日志。
如何对事务进行分类?
从检查点LSN开始,从前往后扫描预写日志:
- 每条日志记录对应事务Tx,将Tx加入undo-Tx集合;
- 遇到<Ti, Commit>记录,将Ti移出undo-Tx集合;
阶段二,Redo阶段:重做检查点LSN之后,预写日志中的所有操作。
从检查点LSN开始,从前往后扫描预写日志:
遇到<Ti, update>记录,修改检查点中对应的数据页X,将对应的数据进行修改,如此一来,就恢复到了数据库崩溃前的缓冲池数据页镜像。
这些数据页能全部刷盘吗?
不能,没有提交的事务的操作,必须进行回滚。
阶段三,Undo阶段:对于没有提交的事务,恢复这些事务对数据页的修改。
从flushed-LSN开始,从后往前逆向扫描预写日志,直到检查点LSN:
遇到<Ti, update>记录,如果Ti在undo-Tx集合中,就将对应的数据页进行回滚修改,如此一来,所有未提交事务的修改,就进行了回滚。
ARIES算法是数据恢复的典型算法,很多消息系统,存储系统,事务系统对算法进行过效率改良,但其内核,万变不离其宗。思路,比结论更重要。