YOLO!如果你对机器学习感兴趣,这个术语一定不陌生。确实,You Only Look Once已经成为过去几年中目标检测的默认方法之一。受到卷积神经网络取得的进展推动,许多版本的目标检测方法已经被创建。然而,近年来,一个竞争对手出现在了视野中——那就是在计算机视觉中使用基于Transformer的模型。更具体地说,是使用Transformer进行目标检测。
在今天的教程中,你将了解到这种类型的Transformer模型。你还将学会使用Python、一个默认的Transformer模型和HuggingFace Transformers库创建自己的目标检测流程。本文将按照下列步骤讲解:
- 了解目标检测可以用来做什么
- 了解当Transformer用于目标检测时它们是如何工作的
- 已经使用Python和HuggingFace Transformers实现了基于Transformer模型的(图像)目标检测流程

什么是目标检测?
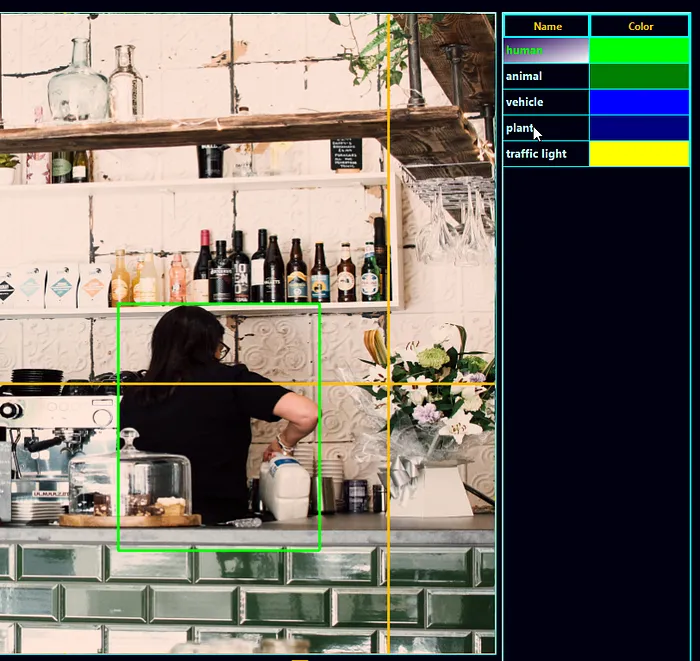
环顾四周,很可能你会看到很多东西——可能是一台电脑显示器、一个键盘和鼠标,或者当你在移动浏览器中浏览时,是一部智能手机。这些都是物体,是特定类别的实例。例如,在下面的图像中,我们看到一个人类类别的实例。我们还看到了许多瓶子类别的实例。虽然类别是蓝图,但物体是真实存在的,具有许多独特的特征,同时因为共享的特征而属于类别的成员。
在图片和视频中,我们看到了许多这样的物体。例如,当你拍摄交通视频时,很可能会看到许多行人、汽车、自行车等实例。知道它们在图像中存在是非常有益的。为什么呢?因为你可以计数它们,举一个例子。这可以让你对社区的拥挤程度有所了解。另一个例子是在繁忙地区检测到一个停车位,让你可以停车。
目标检测和Transformer
传统上,目标检测是通过卷积神经网络来实现的。通常,它们的架构是专门针对目标检测设计的,因为它们将图像作为输入并输出图像的边界框。如果你熟悉神经网络,你就知道卷积网络在学习图像中的重要特征方面非常有用,并且它们是空间不变的——换句话说,学习对象在图像中的位置或大小是无关紧要的。如果网络能够看到对象的特征,并将其与特定类别关联起来,那么它就能识别出来。例如,许多不同的猫都可以被识别为猫类的实例。
然而,最近,在深度学习领域,特别是自然语言处理领域,Transformer架构引起了人们的极大关注。Transformer通过将输入编码为高维状态,然后将其解码回所需的输出来工作。通过聪明地使用自注意力的概念,Transformer不仅可以学习检测特定模式,还可以学习将这些模式与其他模式关联起来。在上面的猫的例子中,举一个例子,Transformer可以学习将猫与其特征点(例如沙发)关联起来。
如果Transformer可以用于图像分类,那么将它们用于目标检测只是更进一步的一步。Carion等人(2020年)已经表明,事实上可以使用基于Transformer的架构来实现这一点。在他们的工作《使用Transformer进行端到端目标检测》中,他们介绍了检测Transformer或DeTr,我们将在今天创建我们的目标检测流程中使用它。
它的工作原理如下,并且甚至没有完全放弃CNN:
- 使用卷积神经网络从输入图像中提取重要特征。这些特征像语言Transformer中一样进行位置编码,以帮助神经网络学习这些特征在图像中的位置。
- 将输入展平,并使用transformer编码器和注意力将其编码为中间状态。
- 变换器解码器的输入是这个状态和在训练过程中获得的一组学习的对象查询。你可以想象它们是在问:“这里是否有一个对象,因为我以前在许多情况下看到过?”,这将通过使用中间状态来回答。
- 事实上,解码器的输出是通过多个预测头进行的一组预测:每个查询一个。由于DeTr中查询的数量默认设置为100,因此它一次只能预测100个对象,除非你对其进行不同的配置。

Transformer架构
HuggingFace Transformers及其目标检测流程
现在你已经了解了DeTr的工作原理,是时候使用它来创建一个真实的目标检测流程了!我们将使用HuggingFace Transformers来实现这个目标,这是为了使NLP和计算机视觉Transformer的工作变得简单而构建的。事实上,使用它非常简单,因为使用它只需要加载ObjectDetectionPipeline——它默认加载了一个使用ResNet-50骨干训练的DeTr Transformer以生成图像特征。
ObjectDetectionPipeline可以很容易地初始化为一个pipeline实例...换句话说,通过pipeline("object-detection")的方式,我们将在下面的示例中看到这一点。当你没有提供其他输入时,这就是根据GitHub(n.d.)初始化管道的方式:
"object-detection": {
"impl": ObjectDetectionPipeline,
"tf": (),
"pt": (AutoModelForObjectDetection,) if is_torch_available() else (),
"default": {"model": {"pt": "facebook/detr-resnet-50"}},
"type": "image",
},毫不奇怪,使用了一个ObjectDetectionPipeline实例,它专门用于目标检测。在HuggingFace Transformers的PyTorch版本中,用于此目的的是AutoModelForObjectDetection。正如你所了解的,Facebook/detr-resnet-50模型是默认用于获取图像特征的:
DEtection TRansformer(DETR)模型在COCO 2017目标检测(118张带标注图像)上进行了端到端训练。它是由Carrion等人在论文《使用Transformer进行端到端目标检测》中介绍的。
HuggingFace (n.d.)
COCO数据集(上下文中的常见对象)是用于目标检测模型的标准数据集之一,并且已用于训练此模型。不用担心,你显然也可以训练自己基于DeTr的模型!要使用ObjectDetectionPipeline,安装包含PyTorch图像模型的timm包是很重要的。确保在尚未安装时运行以下命令:
pip install timm使用Python实现简单的目标检测流程
现在让我们来看看如何使用Python实现简单的目标检测解决方案。回想一下,我们使用的是HuggingFace Transformers,如果你还没有安装它,请运行:
pip install transformers我们还假设PyTorch,这是当今领先的深度学习库之一,已经安装。回想一下上面介绍的ObjectDetectionPipeline将在调用pipeline("object-detection")时在底层加载,它没有TensorFlow的实例,因此PyTorch是必需的。这是我们将要运行创建的目标检测流程的图像,稍后在本文中将会用到。我们从导入开始:
from transformers import pipeline
from PIL import Image, ImageDraw, ImageFont显然,我们使用了transformers,以及它的pipeline表示。然后,我们还使用了PIL,一个用于加载、可视化和操作图像的Python库。具体来说,我们使用第一个导入——Image用于加载图像,ImageDraw用于绘制边界框和标签,后者还需要ImageFont。说到这两者,接下来是加载字体(我们选择Arial)并初始化上面介绍的目标检测管道。
# Load font
font = ImageFont.truetype("arial.ttf", 40)
# Initialize the object detection pipeline
object_detector = pipeline("object-detection")然后,我们创建一个名为draw_bounding_box的函数,该函数将用于绘制边界框。它接受图像(im)、类别概率、边界框的坐标、该定义将要用于的边界框列表中的边界框索引以及该列表的长度作为输入。
在函数中,我们将依次执行下面步骤:
- 首先,在图像上绘制实际的边界框,表示为具有红色的rounded_rectangle bbox,并且半径较小,以确保边缘平滑。
- 其次,在边界框的上方略微绘制文本标签。
- 最后,返回中间结果,这样我们就可以在其上继续绘制下一个边界框和标签。
# Draw bounding box definition
def draw_bounding_box(im, score, label, xmin, ymin, xmax, ymax, index, num_boxes):
""" Draw a bounding box. """
print(f"Drawing bounding box {index} of {num_boxes}...")
# Draw the actual bounding box
im_with_rectangle = ImageDraw.Draw(im)
im_with_rectangle.rounded_rectangle((xmin, ymin, xmax, ymax), outline = "red", width = 5, radius = 10)
# Draw the label
im_with_rectangle.text((xmin+35, ymin-25), label, fill="white", stroke_fill = "red", font = font)
# Return the intermediate result
return im剩下的是核心部分——使用管道,然后根据其结果绘制边界框。以下是我们步骤:
- 首先,图像——我们将其称为street.jpg,并且它位于与Python脚本相同的目录中——将被打开并存储在im PIL对象中。我们只需将其提供给初始化的object_detector——这就足够让模型返回边界框了!Transformers库会处理其余部分。
- 然后,我们将数据分配给一些变量,并遍历每个结果,绘制边界框。
- 最后,我们将图像保存到street_bboxes.jpg中。
# Open the image
with Image.open("street.jpg") as im:
# Perform object detection
bounding_boxes = object_detector(im)
# Iteration elements
num_boxes = len(bounding_boxes)
index = 0
# Draw bounding box for each result
for bounding_box in bounding_boxes:
# Get actual box
box = bounding_box["box"]
# Draw the bounding box
im = draw_bounding_box(im, bounding_box["score"], bounding_box["label"],\
box["xmin"], box["ymin"], box["xmax"], box["ymax"], index, num_boxes)
# Increase index by one
index += 1
# Save image
im.save("street_bboxes.jpg")
# Done
print("Done!")使用不同的模型/使用自己的模型进行目标检测
如果你创建了自己的模型,或者想要使用不同的模型,那么很容易使用它来代替基于ResNet-50的DeTr Transformer。这将需要你添加以下导入:
from transformers import DetrFeatureExtractor, DetrForObjectDetection然后,你可以初始化特征提取器和模型,并使用它们初始化object_detector,而不是默认的一个。例如,如果你想将ResNet-101用作你的骨干,那么你可以这样做:
# Initialize another model and feature extractor
feature_extractor = DetrFeatureExtractor.from_pretrained('facebook/detr-resnet-101')
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-101')
# Initialize the object detection pipeline
object_detector = pipeline("object-detection", model = model, feature_extractor = feature_extractor)结果
以下是我们在输入图像上运行目标检测流程后得到的结果:

当放大时: