大家好,我是小寒。
今天给大家分享几个经典的卷积神经网络架构。
这里主要是分享一些典型的架构,关于卷积神经网络的细节可以下面这篇文章。
1.LeNet
LeNet 是由 Yann LeCun 等人在 1998 年提出的卷积神经网络(CNN)架构,主要用于手写数字识别。
LeNet 是最早的深度学习模型之一,它为后来的深度学习和计算机视觉领域奠定了基础。
http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
LeNet 架构
整体架构如下图所示。
 图片
图片
LeNet 包含以下几个主要层。
- 输入层,输入尺寸为 32x32 的灰度图像。
- 卷积层 C1,6 个 5x5 的卷积核,输出尺寸为 28x28x6。
- 池化层 S2,平均池化,窗口大小为 2x2,输出尺寸为 14x14x6。
- 卷积层 C3,16 个 5x5 的卷积核,输出尺寸为 10x10x16。
- 池化层 S4,平均池化,窗口大小为 2x2,输出尺寸为 5x5x16。
- 卷积层 C5,120 个 5x5 的卷积核,输出尺寸为 1x1x120。
- 全连接层 F6,84 个神经元。
- 输出层,10 个神经元
示例代码
下面是使用 TensorFlow 和 Keras 实现 LeNet 的示例代码。
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
# LeNet-5 模型定义
def LeNet5():
model = models.Sequential()
# 输入层(32x32x1)
model.add(layers.Input(shape=(32, 32, 1)))
# C1: 卷积层(6个5x5卷积核,输出28x28x6)
model.add(layers.Conv2D(6, (5, 5), activatinotallow='tanh'))
# S2: 平均池化层(2x2池化窗口,输出14x14x6)
model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=2))
# C3: 卷积层(16个5x5卷积核,输出10x10x16)
model.add(layers.Conv2D(16, (5, 5), activatinotallow='tanh'))
# S4: 平均池化层(2x2池化窗口,输出5x5x16)
model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=2))
# C5: 卷积层(120个5x5卷积核,输出1x1x120)
model.add(layers.Conv2D(120, (5, 5), activatinotallow='tanh'))
# Flatten: 展平
model.add(layers.Flatten())
# F6: 全连接层(84个神经元)
model.add(layers.Dense(84, activatinotallow='tanh'))
# 输出层(10个神经元,对应分类0-9)
model.add(layers.Dense(10, activatinotallow='softmax'))
return model
# 创建 LeNet-5 模型
model = LeNet5()
# 打印模型结构
model.summary()
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 加载数据集(MNIST 手写数字识别数据集)
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 归一化
x_train, x_test = x_train / 255.0, x_test / 255.0
print(x_train[0])
# 扩展维度以匹配模型输入
x_train = np.pad(x_train, ((0, 0), (2, 2), (2, 2)), 'constant')
x_test = np.pad(x_test, ((0, 0), (2, 2), (2, 2)), 'constant')
print(x_train[0])
# 扩展维度以匹配模型输入
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
print(x_train.shape)
# 训练模型
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))2.AlexNet
AlexNet 是一个深度卷积神经网络,于 2012 年在 ImageNet 图像识别挑战赛中获胜,由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 开发。这个模型不仅大幅提高了图像分类任务的准确率,而且也推动了深度学习在多个领域的广泛应用。
https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
快速学会一个算法,CNN
架构
AlexNet 的整体架构如下所示。
 图片
图片
AlexNet 包含以下几个主要层。
- 输入层,输入图像大小为 227x227x3。
- 第1个卷积层,使用 96 个 11x11 的卷积核,步长为 4,后接最大池化。
- 第2个卷积层,使用 256 个 5x5 的卷积核,步长为1,采用填充,后接最大池化。
- 第3个卷积层,使用 384 个 3x3 的卷积核,步长为1,采用填充。
- 第4个卷积层,使用 384 个 3x3 的卷积核,步长为1,采用填充。
- 第5个卷积层,使用 256 个 3x3 的卷积核,步长为1,采用填充,后接最大池化。
- 全连接层,三个全连接层,前两个各有 4096 个神经元,最后一个有 1000 个输出神经元,每个对应一个类别,使用softmax激活函数进行多类分类。
示例代码
下面是使用 TensorFlow 和 Keras 实现 AlexNet 的示例代码。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation
model = Sequential([
# 第1层 - 卷积层
Conv2D(96, (11, 11), strides=(4, 4), padding='valid', input_shape=(227, 227, 3)),
Activation('relu'),
MaxPooling2D(pool_size=(3, 3), strides=(2, 2)),
# 第2层 - 卷积层
Conv2D(256, (5, 5), padding='same'),
Activation('relu'),
MaxPooling2D(pool_size=(3, 3), strides=(2, 2)),
# 第3层 - 卷积层
Conv2D(384, (3, 3), padding='same'),
Activation('relu'),
# 第4层 - 卷积层
Conv2D(384, (3, 3), padding='same'),
Activation('relu'),
# 第5层 - 卷积层
Conv2D(256, (3, 3), padding='same'),
Activation('relu'),
MaxPooling2D(pool_size=(3, 3), strides=(2, 2)),
# 展平层
Flatten(),
# 第6层 - 全连接层
Dense(4096),
Activation('relu'),
Dropout(0.5),
# 第7层 - 全连接层
Dense(4096),
Activation('relu'),
Dropout(0.5),
# 输出层
Dense(1000),
Activation('softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()3.VGGNet
VGGNet 是由牛津大学的视觉几何组 (Visual Geometry Group, VGG) 开发的一种卷积神经网络架构。它首次在 2014 年的 ImageNet 竞赛中提出,并因其简单而有效的结构而受到广泛关注。
https://arxiv.org/pdf/1409.1556
VGGNet 的主要创新是使用多个较小的卷积核(3x3)而不是较大的卷积核,这增加了网络的深度来改善特征的学习能力,同时减少了参数数量。
VGGNet 有几种不同的配置,常见的如 VGG16 和 VGG19,分别含有 16 和 19 层深度。
VGG16的架构如下图所示,它由 13 个卷积层和 3个全连接层组成。
 图片
图片
VGG16 和 VGG19
VGG16 架构
VGG16 包括 16 个权重层,其结构包括:
- 13 个卷积层,使用 3x3 的卷积核,步长为1,边缘填充也为1,确保卷积操作后特征图的尺寸不变。
- 5 个最大池化层,用于降低特征图的尺寸。
- 3 个全连接层,前两个全连接层各有 4096 个节点,最后一个全连接层用于分类,节点数取决于类别数(通常为 1000,对应 ImageNet 数据集)。
VGG19 架构
VGG19 是 VGG16 的一个更深版本,包括 19 个权重层。它的结构包括:
- 16 个卷积层,配置与 VGG16 类似,但在第三、四、五个卷积块中增加了更多的卷积层。
- 5 个最大池化层,与 VGG16 相同,用于特征下采样。
- 3 个全连接层,配置同 VGG16。
 图片
图片
示例代码
下面是使用 TensorFlow 和 Keras 实现 VGG16 的示例代码。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
def VGG16(input_shape=(224, 224, 3), num_classes=1000):
model = Sequential([
# Block 1
Conv2D(64, (3, 3), padding='same', activatinotallow='relu', input_shape=input_shape),
Conv2D(64, (3, 3), padding='same', activatinotallow='relu'),
MaxPooling2D((2, 2), strides=(2, 2)),
# Block 2
Conv2D(128, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(128, (3, 3), padding='same', activatinotallow='relu'),
MaxPooling2D((2, 2), strides=(2, 2)),
# Block 3
Conv2D(256, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(256, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(256, (3, 3), padding='same', activatinotallow='relu'),
MaxPooling2D((2, 2), strides=(2, 2)),
# Block 4
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
MaxPooling2D((2, 2), strides=(2, 2)),
# Block 5
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
Conv2D(512, (3, 3), padding='same', activatinotallow='relu'),
MaxPooling2D((2, 2), strides=(2, 2)),
# Fully connected layers
Flatten(),
Dense(4096, activatinotallow='relu'),
Dense(4096, activatinotallow='relu'),
Dense(num_classes, activatinotallow='softmax')
])
return model
# 创建模型
model = VGG16()
model.summary()4.GoogLeNet
GoogLeNet,也被称为 Inception v1,是一种深度卷积神经网络(CNN),最初由Google的研究者在2014年提出。
https://arxiv.org/pdf/1409.4842
它在当年的ImageNet挑战赛中取得了冠军,以其创新的 “Inception模块” 而著称,该模块能够显著增加网络的宽度和深度,同时保持计算资源的合理使用。
整体架构如下图所示。
 图片
图片
Inception模块
 图片
图片
如上所示,它与我们之前看到的顺序架构相比发生了巨大变化。
在单层中,存在多种类型的 “特征提取器”。这间接帮助网络表现更好,因为训练中的网络本身在解决任务时有很多选择。它可以选择卷积输入,也可以直接池化输入。
下面是 Inception 模块的代码实现。
def inception_module(x, filters):
# 1x1卷积
path1 = Conv2D(filters=filters[0], kernel_size=(1, 1), padding='same', activatinotallow='relu')(x)
# 1x1卷积后接3x3卷积
path2 = Conv2D(filters=filters[1], kernel_size=(1, 1), padding='same', activatinotallow='relu')(x)
path2 = Conv2D(filters=filters[2], kernel_size=(3, 3), padding='same', activatinotallow='relu')(path2)
# 1x1卷积后接5x5卷积
path3 = Conv2D(filters=filters[3], kernel_size=(1, 1), padding='same', activatinotallow='relu')(x)
path3 = Conv2D(filters=filters[4], kernel_size=(5, 5), padding='same', activatinotallow='relu')(path3)
# 3x3最大池化后接1x1卷积
path4 = MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(x)
path4 = Conv2D(filters=filters[5], kernel_size=(1, 1), padding='same', activatinotallow='relu')(path4)
# 合并所有路径
return concatenate([path1, path2, path3, path4], axis=-1)5.ResNet
ResNet(残差网络)是由微软研究院的何凯明等人在 2015 年提出的一种深度学习模型,主要用于图像识别和相关视觉任务。
https://arxiv.org/pdf/1512.03385
它解决了深层网络训练难题中的梯度消失或爆炸问题,使得网络能够通过增加层数来提高准确率,而不会降低训练效果。
 图片
图片
原理
ResNet 的核心概念是引入了 “残差学习” 的思想。
在传统的神经网络中,每一层的输出是直接传递给下一层的。
而在 ResNet 中,引入了跳跃连接,它允许输入直接 “跳过” 一些层传到更深的层。
 图片
图片
其公式可以表示为:
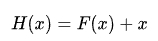
其中,X 是输入,F(x) 是残差函数,H(x) 是从输入到输出的映射函数。
残差块
残差一样采用模组化的方式,针对不同深度的 ResNet,作者提出了两种残差块。
 图片
图片
1.基本残差块对于较浅的 ResNet 模型(例如 ResNet-18 和 ResNet-34),使用的是基本残差块,这种块的结构相对简单。下面是基本残差块的 python 代码实现。
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
# 第一个卷积层
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 第二个卷积层
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
# 快捷连接,如果维度不匹配,需要通过1x1卷积调整维度
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != self.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, self.expansion * out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * out_channels)
)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(identity)
out = self.relu(out)
return out两个 3×3 的卷积层每个卷积层后面通常跟有批量归一化(Batch Normalization)和 ReLU 激活函数。第一个卷积层处理输入数据,而第二个卷积层进一步提炼特征。
跳跃连接输入直接通过跳跃连接跳过两个卷积层,最终与第二个卷积层的输出相加。这种直接的连接帮助网络学习恒等映射,即当增加更多层时,新层可以被训练为不改变已学习特征的恒等映射,这样不会损害网络的性能。
2.瓶颈残差块对于更深的 ResNet 模型(如 ResNet-50 和 ResNet-152),使用的是瓶颈残差块,其设计更复杂,以提高计算效率。下面是瓶颈残差块的python代码实现。
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super(Bottleneck, self).__init__()
# 降维
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 特征提取
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 恢复维度
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion)
)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += self.shortcut(identity)
out = self.relu(out)
return out第一层,使用 1×1 卷积核,主要目的是减少输入的维度(通道数),这有助于减少后续层的计算负担。
第二层,标准的 3×3 卷积层,在降维后的特征上进行空间特征提取。
第三层,再次使用 1×1 卷积核,目的是恢复通道数,为将输出与跳跃连接相加做准备。
跳跃连接,如果输入与输出的维度不匹配(通常在跨越残差块时会改变维度),跳跃连接上也会应用 1×1 卷积来调整维度,确保能够与主路径上的输出相加。
6.ResNeXt
ResNeXt 是由 Facebook AI Research 提出的,它是一种改进的卷积神经网络架构,基于 ResNet,但通过引入组卷积(group convolution)进一步提高了模型的性能和效率。
ResNeXt 的核心思想是使用多个并行的路径,每个路径都有其独立的卷积层,最终通过累加这些路径的输出来提升模型的表达能力。
https://arxiv.org/pdf/1611.05431v2
网络架构
ResNeXt 的特点在于将 ResNet 的 bottleneck 块改进为类似于 Inception 的结构,通过多路径的方式,将较大的通道数分解为多个较小的通道数,从而达到同样的效果。此外,ResNeXt 引入了一个新的超参数 C(cardinality),用于表示路径的数量。
ResNeXt 的架构如下所示。
 图片
图片