引言
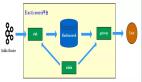
在现代的数据架构中,MySQL 通常作为关系型数据库管理系统来存储结构化数据,而 Elasticsearch 作为一个强大的分布式搜索和分析引擎,擅长处理全文搜索、日志分析等场景。将 MySQL 中的数据实时同步到 Elasticsearch,可以充分利用两者的优势,实现数据的实时搜索、分析和可视化。本文将探讨实现这一目标的几种常见技术和方法。
实现方法
1.使用 Logstash
Logstash 是 Elastic Stack(ELK Stack)的一部分,它支持实时管道,可以捕获、输入、转换和输出日志或事件数据。Logstash 有一个 JDBC 插件,可以用来定时查询 MySQL 数据库,并将数据同步到 Elasticsearch。
配置步骤:
安装 Logstash。
配置 JDBC 输入插件,指定 MySQL 数据库连接和查询。
配置 Elasticsearch 输出插件。
启动 Logstash。
2.使用 Debezium
Debezium 是一个基于 Apache Kafka 的数据变更捕获(CDC)平台,它可以将 MySQL 的 binlog 变更数据实时发送到 Kafka 主题,然后再由 Kafka Connect Elasticsearch 连接器将数据同步到 Elasticsearch。
配置步骤:
安装并配置 Kafka 和 Debezium。
在 MySQL 中启用 binlog。
配置 Debezium MySQL 连接器,将数据变更发送到 Kafka。
配置 Kafka Connect Elasticsearch 连接器,从 Kafka 读取数据并写入 Elasticsearch。
3.使用 Elasticsearch JDBC Import 插件
Elasticsearch JDBC Import 插件允许 Elasticsearch 直接通过 JDBC 接口从外部数据库(如 MySQL)导入数据。这种方法不需要额外的中间件,但可能不支持实时同步。
配置步骤:
安装 Elasticsearch JDBC Import 插件。
配置 JDBC 导入器,指定数据库连接、查询和 Elasticsearch 索引设置。
4.使用自定义程序
可以编写自定义程序(如使用 Java、Python 等),通过监听 MySQL 的 binlog 或定时查询数据库来获取数据变更,然后将这些数据推送到 Elasticsearch。
实现步骤:
使用 MySQL binlog 客户端库或 JDBC。
使用 Elasticsearch 客户端库(如 Java High Level REST Client)。
实现数据变更监听或定时查询逻辑。
将数据推送到 Elasticsearch。
性能和可靠性考虑
性能优化:考虑批量处理数据、优化 Elasticsearch 索引设置、调整同步频率等。
错误处理:实现错误重试机制、日志记录和监控。
数据一致性:确保同步过程中数据的完整性和一致性。
结论
将 MySQL 数据实时同步到 Elasticsearch 可以显著增强数据的实时搜索和分析能力。根据具体需求和环境,可以选择适合的同步方法和技术实现。无论是使用现成的工具如 Logstash 和 Debezium,还是编写自定义程序,都需要仔细考虑性能、可靠性和数据一致性的问题。