如何找到自己感兴趣的开源项目
首先第一步先想清楚自己搞开源的目的是什么:
- 参考社区大佬的代码,提升技术
- 丰富个人履历,提高面试通过率
更功利一点就是想成为某个项目的 Committer/PMC
- 单纯喜欢分享,热爱开源,认可开源改变世界💪。
我人为前面三种都是一个目的,提升自己获得后续的好处;最后一种则是妥妥的纯热爱。
以我个人来说,我两者都沾一点;我相信大部分人都是前面三类的目的,到这里我可能要先浇点冷水。
往往一个开源项目从你熟悉它开始到提第一个 PR 然后到合并中间经历的时间可能是大大超出你的预期的。
特别是越大型越专业的项目(我相信你也是想加入这类有一定知名度的项目)。
因为开源社区大部分都是执行异步沟通,与即时通讯的快速反馈不同,甚至还有不少 reviewer 处于不同的时区。
所以一开始就想做好心理预期,不要指望着我给某个项目提交一个很牛逼的功能,然后他们快速 review 合并,然后给你 commit 权限。
而且有不少开源项目是由某一个公司主导的,比如(Pulsar、Golang、Kafka),他们可能对于外部社区来的新手并不那么上心,一个 PR 晾在那里几个月没人理都是很正常的。
所以我建议一开始选择的项目有以下几个筛选标准:
- 尽量是自己日常在用,熟悉的项目。
- 最近有在及时更新维护的项目。
- 对社区新人的接纳程度是否足够包容。
- 这点可以在 Github 里查找标签为 help want/contribution welcome 的 issue 或者是 PR。
- 查看这些 issue/ PR 最近的活跃时间,贡献者是否为新人。
- 往往一个包容度较高的项目以上信息都是很活跃的。
- 项目主要维护者是否来着不同的公司,是否足够活跃。
 图片
图片
 图片
图片
推荐几个我认为比较符合我刚才提到的条件的项目:
- https://github.com/open-telemetry/opentelemetry-java-instrumentation/issues/7195
- https://github.com/apache/pulsar-client-go/issues?q=is%3Aopen+label%3Atype%2Ffeature+sort%3Aupdated-desc
- https://github.com/apache/hertzbeat/
如何快速上手一个开源项目
如果找到了自己想贡献的项目,如果自己还不太熟悉的话,那就可以尝试以下步骤来快速上手它。
单元测试
首先第一个就是单元测试,单元测试是一个非常不错的方式来上手一个新的开源项目,但重点不是去看现有的单测,而是自己去写✍️。
写过单元测试的小伙伴就知道,如果要达到 90% 以上的覆盖率时需要对自己写的每一行代码都得了解,甚至在写的过程中会发现部分代码是不是没有必要,从而再帮助自己梳理一遍业务。
所以写单测确实是快速熟悉某个项目的方法,但这针对于一些逻辑简单的项目;对于一些业务复杂的项目建议还是快速跑通官方推荐一个功能。
以 Pulsar 为例
以 Apache Pulsar为例,那就先跑一个消息的生产者和消费者 demo;跑通了之后再尝试看看它客户端已有的单测代码,然后尝试改一些断言,此时就会发现预期值为什么会这么定义。https://github.com/apache/pulsar/blob/631b13ad23d7e48c6e82d38f97c23d129062cb7c/pulsar-broker/src/test/java/org/apache/pulsar/client/impl/BrokerClientIntegrationTest.java#L1077
 图片
图片
 图片
图片
比如这里的一个 consumer 取消订阅两次时候就会抛出异常,此时我们就可以根据异常的地方找到源码里对连接状态的判断条件。
就可以得知:当客户端取消订阅时会修改连接状态。
HertzBeat
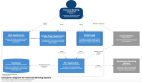
下面以 Apache HertzBeat为例来看看当时我是如何贡献单元测试的。
 图片
图片
通过官方的架构图可以得知 HertzBeat 是通过一个 collector 去直连目标采集数据的。
比如通过 Redis 的客户端去获取监控数据,然后再存放到自己的时序数据库中进行展示。
所以这个采集的过程就是比较核心的逻辑,我们可以看看他的接口定义。
 图片
图片
一共就三个接口,分别是:
- collect采集接口:在 Metrics 中定义了采集的目标信息(地址、端口等)
- 采集完后的数据写入到 Builder 供后续的写入存储
- preCheck:提前做一些参数校验
- supportProtocol:返回定义的协议类型,通过这个类型找到对应采集器
 图片
图片
然后就交由不同的实现类去采集不同的指标。
这里我以 RedisCommonCollectImpl为例,主要的单测逻辑就是模拟 Redis 客户端的返回数据,然后在 Collect 的代码里查看不同的处理逻辑,其实就是要覆盖各种分支以及异常的情况。
最后再断言采集到的数据与预期是否匹配即可,贴一段核心逻辑:
 图片
图片
至于应该返回什么预期结果,有些 collector 可能会在代码注释里写清楚,但这个 Redis 没有写。
不过也有办法,我们可以把代码在本地跑起来之后进入管理台查看内置的监控模版。
 图片
图片
这里是用于定义会监控哪些字段的地方,这样我们就可以在代码预先生成好预期返回值了。
 图片
图片
具体的单测代码请看这里:https://github.com/apache/hertzbeat/blob/master/collector/src/test/java/org/apache/hertzbeat/collector/collect/redis/RedisClusterCollectImplTest.java#L46
总结
参与一个成熟社区的开源有一点一定要记住,就是要仔细阅读贡献者文档。
里面往往会写清楚如何构建代码、代码规范、提交规范等信息,这些都捋清楚后提交的 PR 才更容易被社区接受。
后面会继续更新集成测试与 e2e 测试等内容。