从数据科学的技术角度来看,预测单步和预测多步有很大区别,后者更难。预测多个时期需要全面了解长期模式和依赖关系。它具有前瞻性,需要模型来捕捉一段时间内错综复杂的动态变化。
多步预测的策略通常有两种,即单不预测策略和递归预测策略。时序基础模型 ARIMA 是单步预测模型。那么如何实现多步骤预测?也许一种方法是递归使用同一模型。从模型中得到一个周期的预测结果,作为预测下一个周期的输入。然后,将第二期的预测作为预测第三期的输入。可以通过使用前一期的预测结果来遍历所有时期。这正是递归预测或迭代预测策略的作用。图(A)显示模型首先产 ,然后 成为同一模型的输入,产
:递归预测策略") 图(A):递归预测策略
图(A):递归预测策略
在"基于树的时间序列预测实战"中,我们学会了将单变量时间序列表述为基于树的建模问题。我们可以将一个时期的值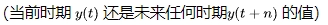 作为树状模型的目标,得出一个无偏值。若我们建立n个模型,每个模型都能预测第 n 个时期,我们可以将它们的预测结果结合起来,这就是直接预测策略。这个方法成功的原因在于,针对单一目标的树状模型通常是有效的,而且不同的模型可以捕捉到随时间变化的复杂动态。其他替代策略也存在,但主要是这两种方法的衍生。
作为树状模型的目标,得出一个无偏值。若我们建立n个模型,每个模型都能预测第 n 个时期,我们可以将它们的预测结果结合起来,这就是直接预测策略。这个方法成功的原因在于,针对单一目标的树状模型通常是有效的,而且不同的模型可以捕捉到随时间变化的复杂动态。其他替代策略也存在,但主要是这两种方法的衍生。
:直接预测策略") 图(B):直接预测策略
图(B):直接预测策略
两种主要策略是:
- 递归预测
- n步直接预测
这两种方法需要耗费大量时间进行数据重组和模型迭代。递归策略已经纳入经典 Python 库 "statsmodels"中,而我将采用开源 Python 库 "Sktime",该库使递归和直接预测方法变得更加简单。Sktime 封装了多种工具,包括 "statsmodels",并提供了统一的 API,可用于时间序列预测、分类、聚类和异常检测(Markus等人,2019,2020)
接下来云朵君和大家一起学习如何思考产生多步预测的策略、多步预测的代码以及评估。
- 多步预测的递归策略
- n 个周期、n 个模型的直接预测策略
- 使用 ARIMA 的递归策略
安装 sktime 库和 lightGBM 库。
!pip install sktime
!pip install lightgbm递归预测
递归策略中,先对前一步进行预测,然后用这些预测作为输入,对未来的时间步骤进行迭代预测。整个过程中只使用一个模型,生成一个预测,并将其输入到模型中生成下一个预测,如此循环。步骤如下:
- 建模:训练一个时间序列预测模型,预测一步前瞻。可以使用传统的时间序列模型(如ARIMA)、指数平滑模型或机器学习模型(如lightGBM)。
- 生成第一次预测:利用历史数据,使用已训练的模型预测下一个时间步骤。
- 将预测值作为下一次预测模型的输入:将预测值添加到历史数据中,创建更新的时间序列。
- 迭代预测:使用更新后的时间序列作为模型的输入数据,重复上述过程。在每次迭代中,模型考虑之前的预测值,进行多步骤预测。继续迭代预测过程,直到达到期望的未来步数。
一个可以发现的问题是,随着时间推移,预测的准确性会下降,初期预测的误差会在后期积累。只要模型足够复杂,能够捕捉到错综复杂的模式,这种情况似乎是可以接受的。
加载电力消耗数据,数据说明可以在"基于树模型的时间序列预测实战"中找到。
%matplotlib inline
from matplotlib import pyplot as plt
import pandas as pd
import numpy as np
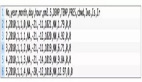
data = pd.read_csv('/electric_consumption.csv', index_col='Date')
data.index = pd.to_datetime(data.index)
data = data.sort_index() # Make sure the data are sorted
data.index = pd.PeriodIndex(data.index, freq='H') # Make sure the Index is sktime format
data.index我唯一想指出的是使用 pd.PeriodIndex() 使索引符合 sktime 格式。
 图片
图片
从 Pandas DataFrame 中提取一个序列。Pandas 系列保留了 sktime 所需的索引。
y = data['Consumption']
# Train and test split
cuttime = int(len(y)*0.9) # Take 90% for training
train = y[0:cuttime]
test = y[cuttime::]
y 图片
图片
我们计划使用递归预测方法并建立一个 lightGBM 模型,使用与"基于树的时间序列预测教程"相同的超参数。此外,Python Notebook 中还有一个未显示的 GBM 模型示例供你尝试其他模型。
import lightgbm as lgb
from sktime.forecasting.compose import make_reduction
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="recursive")
lgb_forecaster.fit(train)我们只指定了 "递归" 作为策略超参数值,稍后会采用 "直接" 预测方法。
下一步,我们需要生成一个未来周期的数字列表。我设置未来期限 (fh) 为 100 期,即 [1,2,...,100]。然后生成这 100 期的预测。
vlen = 100
fh = list(range(1, vlen,1))
y_test_pred = lgb_forecaster.predict(fh= fh)
y_test_pred与测试数据中的实际值相比,预测结果如何?让我们将 100 期的实际值和预测值进行匹配并绘制成图。
from sktime.utils.plotting import plot_series
actual = test[test.index<=y_test_pred.index.max()]
plot_series(actual, y_test_pred, labels=['Actual', 'Predicted'])
plt.show()我使用的函数 plot_series() 只是 matplotlib 函数的封装。
:使用 LightGBM 的递归策略") 图 (A):使用 LightGBM 的递归策略
图 (A):使用 LightGBM 的递归策略
常见的评估指标包括平均绝对百分比误差(MAPE)和对称MAPE。在sktime中,可以通过控制超参数来简化这一操作。
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=False))
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=True))结果如下。稍后我们将把这两个数字与直接预测法中的数字进行比较。
- MAPE: 0.0546382493115653
- sMAPE: 0.0547477326419614
太好了,我们成功地使用递归法建立了多重预测。接下来,让我们学习直接预测策略。
n步直接预测
了解了递归预测策略后,我们来考虑一下直接预测策略。我们将建立多个单独的模型,每个模型负责预测特定的未来时段。尽管建立许多模型会耗费一些时间,但这是机器的事情,而不是我的大脑时间。在利用 CPU 能力的同时。
接下来是整个过程的步骤:
- 模型训练:为每个未来时间步训练一个独立的模型。例如,如果要预测未来 100 个时间段,就需要训练 100 个单独的模型,每个模型负责预测各自时间步的值。
- 预测:使用每个训练好的模型独立生成特定时间的预测值。这些模型可以并行运行,因为它们的预测并不相互依赖。
- 合并预测:只需将这些预测连接起来即可。
这种直接预测策略的优势之一是能够捕捉每个预测范围内的特定模式。每个模型都可以针对其负责的时间步长进行优化,从而提高准确性。
我们将使用与回归器相同的 LightGBM,并使用 make_reduction(),唯一的区别是超参数是 direct 而不是 recursive。
from sktime.forecasting.compose import make_reduction
import lightgbm as lgb
lgb_regressor = lgb.LGBMRegressor(num_leaves = 10,
learning_rate = 0.02,
feature_fraction = 0.8,
max_depth = 5,
verbose = 0,
num_boost_round = 15000,
nthread = -1
)
lgb_forecaster = make_reduction(lgb_regressor, window_length=30, strategy="direct")我们将使用 100 个周期[1,2,...,100]的列表来预测范围 (fh)。每个周期会建立一个 LightGBM 模型,总共会有 100 个模型。尽管构建这么多 LightGBM 模型可能会花费很多时间,但我只演示 100 个周期的原因。
vlen = 100
fh=list(range(1, vlen,1))
lgb_forecaster.fit(train, fh = fh)
y_test_pred = lgb_forecaster.predict(fh=fh)
y_test_pred将绘制测试数据中的实际值与预测值的对比图。
from sktime.utils.plotting import plot_series
plot_series(actual, y_test_pred, labels=["Actual", "Prediction"], x_label='Date', y_label='Consumption');这是因为每个预测都来自一个独立的模型,有自己的特点。
:使用 LightGBM 的直接预测策略") 图 (B):使用 LightGBM 的直接预测策略
图 (B):使用 LightGBM 的直接预测策略
回顾一下评估指标:
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=False))
print('%.16f' % mean_absolute_percentage_error(actual, y_test_pred, symmetric=True))MAPE 和 sMAPE 与递归法的结果非常接近。
- MAPE: 0.0556899099509884
- sMAPE: 0.0564747643400997
Make_reduction()
LightGBM模型是一个监督学习模型,需要包含x和y的数据帧来进行模型训练。make_reduction()函数可以将单变量时间序列转化为数据帧。该函数有两个主要参数,即strategy("递归"或"直接")和window_length(滑动窗口长度)。滑动窗口与单变量时间序列一起移动,创建样本,窗口中的值就是x值。递归策略和直接策略将在接下来进行解释。
递归策略
递归策略中,滑动窗口前的值即为目标值,图(D)滑动 14 窗口,生成了 6 个样本的数据帧,其中蓝色的 y 值为目标值,该数据帧用于训练模型。
:递归策略的 Make_reduction()") 图 (D):递归策略的 Make_reduction()
图 (D):递归策略的 Make_reduction()
直接预测策略
直接预测策略为每个未来目标期建立一个模型。假设目标值是 t+3 的值。图(D)滑动 14 窗口,生成一个包含 4 个样本的数据帧。目标值是 t+3 中的 y 值。该数据帧用于训练预测 t+3 的 y 值的模型。
:针对 y_t+3 的直接策略 Make_reduction()") 图 (E):针对 y_t+3 的直接策略 Make_reduction()
图 (E):针对 y_t+3 的直接策略 Make_reduction()
目标是预测 t+4 中的值。图 (D) 滑动了 14 个窗口并生成了一个包含 3 个样本的数据帧,用于训练预测 t+4 中 y 值的模型。
:针对 y_t+4 的直接策略 Mak") 图(F):针对 y_t+4 的直接策略 Mak
图(F):针对 y_t+4 的直接策略 Mak
使用 ARIMA 进行多步预测
Sktime可以使用Python库pmdarima进行ARIMA并提供多步预测。Sktime本身不提供多步预测,但是pmdarima库可以进行多步预测。一旦建立了ARIMA模型,它会对预测范围内的每个时间点进行提前一步预测,并且采用递归策略生成预测值。
!pip install pmdarima函数 temporal_train_test_split()。
首先将数据分成训练数据和测试数据。
from sktime.forecasting.model_selection import temporal_train_test_split
train, test = temporal_train_test_split(y, train_size = 0.9)以下代码将建立模型并提供预测。注意该代码没有使用 Sktime 的 make_reduction() 函数。这是因为多步预测是由 AutoARIMA 模型提供的。
from sktime.forecasting.arima import AutoARIMA
arima_model = AutoARIMA(sp=12, suppress_warnings=True)
arima_model.fit(train)
# Future horizon
vlen = 100
fh=list(range(1, vlen,1))
# Predictions
pred = arima_model.predict(fh)
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
print('%.16f' % mean_absolute_percentage_error(test, pred, symmetric=False))Sktime 简介
Sktime是一个开源的Python库,集成了许多预测工具,包括时间序列预测、分类、聚类和异常检测的工具和算法。它提供了一系列主要功能,包括时间序列数据预处理、时间序列预测、时间序列分类和聚类,以及时间序列注释。
- 时间序列数据预处理:包括缺失值处理、归因和转换。
- 时间序列预测:它包括常见的时间序列建模算法,我将在下一段列出。
- 时间序列分类和聚类:它包括时间序列 k-nearest neighbors (k-NN) 等分类模型和时间序列 k-means 等聚类模型。
- 时间序列注释:它允许对时间序列数据进行标注和注释,这对异常检测和事件检测等任务非常有用。
Sktime包括一些常见的时间序列建模算法,如指数平滑 (ES)、经典自回归综合移动平均 (ARIMA) 和季节性 ARIMA (SARIMA) 模型,以及向量自回归(VAR)、向量误差修正模型(VECM)、结构时间序列(STS)模型等结构模型。此外,它还可以处理神经网络模型,包括时间卷积神经网络(CNN)、全连接神经网络(FCN)、长短期记忆全卷积网络(LSTM-FCN)、多尺度注意力卷积神经网络(MACNN)、时间递归神经网络(RNN)和时间卷积神经网络(CNN)。
结论
本章介绍了单步预测到多步预测的建模策略,包括递归预测和 n 期直接预测两种方法。我们还学习了 Python 软件包 "sktime",它支持轻松执行这两种策略。除了演示的 LightGBM 模型外,我们也可以使用其他模型,如 ARIMA、线性回归、GBM 或 XGB 作为回归因子。