背景
在日常生活中,我们通常会先把数据存储在一张表中,然后再进行加工、分析,这里就涉及到一个时效性的问题。
场景一:如果我们处理以年、月为单位的级别的数据,针对这些大量数据的实时性要求并不高。
场景二:如果我们处理的是以天、小时,甚至分钟为单位的数据,那么对数据的时效性要求就比较高。
在第二种场景下,如果我们仍旧采用传统的数据处理方式,统一收集数据,存储到数据库中,之后在进行分析,就可能无法满足时效性的要求。
数据的计算模式主要分为:
- 批量计算(batch computing)、
- 流式计算(stream computing)、
- 交互计算(interactive computing)、
- 图计算(graph computing)等。
其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。
流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。流式计算,就是对数据流进行处理,是实时计算。
批量计算则统一收集数据,存储到数据库中,然后对数据进行批量处理的数据计算方式。两者的区别主要体现在以下几个方面:
(1)数据时效性不同
- 流式计算实时、低延迟;
- 批量计算非实时、高延迟。
(2)数据特征不同
- 流式计算的数据一般是动态的、没有边界的;
- 批处理的数据一般则是静态数据。
(3)应用场景不同
- 流式计算应用在实时场景,时效性要求比较高的场景,如实时推荐、业务监控…。
- 批量计算一般说批处理,应用在实时性要求不高、离线计算的场景下,数据分析、离线报表等。
(4)运行方式不同
- 流式计算的任务持续进行的;
- 批量计算的任务则一次性完成。
流式计算框架平台与相关产品
第一类,商业级流式计算平台(IBM InfoSphere Streams、IBM StreamBase等);
第二类,开源流式计算框架(Twitter Storm、S4等);
第三类,公司为支持自身业务开发的流式计算框架。
(1)Strom:Twitter 开发的第一代流处理系统。
(2)Heron:Twitter 开发的第二代流处理系统。
(3)Spark streaming:是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
(4)Flink:是一个针对流数据和批数据的分布式处理引擎。
(5)Apache Kafka:由Scala写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
流式计算主要应用场景
流式处理可以用于两种不同场景:事件流和持续计算。
(1)事件流
事件流具能够持续产生大量的数据,这类数据最早出现与传统的银行和股票交易领域,也在互联网监控、无线通信网等领域出现、需要以近实时的方式对更新数据流进行复杂分析如趋势分析、预测、监控等。简单来说,事件流采用的是查询保持静态,语句是固定的,数据不断变化的方式。
(2)持续计算
比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况;比如金融行业,毫秒级延迟的需求至关重要。一些需要实时处理数据的场景也可以应用Storm,比如根据用户行为产生的日志文件进行实时分析,对用户进行商品的实时推荐等。
大数据流式计算可以广泛应用于金融银行、互联网、物联网等诸多领域,如股市实时分析、插入式广告投放、交通流量实时预警等场景,主要是为了满足该场景下的实时应用需求。数据往往以数据流的形式持续到达数据计算系统,计算功能的实现是通过有向任务图的形式进行描述,数据流在有向任务图中流过后,会实时产生相应的计算结果。整个数据流的处理过程往往是在毫秒级的时间内完成的。
通常情况下,大数据流式计算场景具有以下鲜明特征。
1)在流式计算环境中,数据是以元组为单位,以连续数据流的形态,持续地到达大数据流式计算平台。数据并不是一次全部可用,不能够一次得到全量数据,只能在不同的时间点,以增量的方式,逐步得到相应数据。
2)数据源往往是多个,在进行数据流重放的过程中,数据流中各个元组间的相对顺序是不能控制的。也就是说,在数据流重放过程中,得到完全相同的数据流(相同的数据元组和相同的元组顺序)是很困难的,甚至是不可能的。
3)数据流的流速是高速的,且随着时间在不断动态变化。这种变化主要体现在两个方面,一个方面是数据流流速大小在不同时间点的变化,这就需要系统可以弹性、动态地适应数据流的变化,实现系统中资源、能耗的高效利用;另一方面是数据流中各个元组内容(语义)在不同时间点的变化,即概念漂移,这就需要处理数据流的有向任务图可以及时识别、动态更新和有效适应这种语义层面上的变化。
4)实时分析和处理数据流是至关重要的,在数据流中,其生命周期的时效性往往很短,数据的时间价值也更加重要。所有数据流到来后,均需要实时处理,并实时产生相应结果,进行反馈,所有的数据元组也仅会被处理一次。虽然部分数据可能以批量的形式被存储下来,但也只是为了满足后续其他场景下的应用需求。
5)数据流是无穷无尽的,只要有数据源在不断产生数据,数据流就会持续不断地到来。这也就需要流式计算系统永远在线运行,时刻准备接收和处理到来的数据流。在线运行是流式计算系统的一个常态,一旦系统上线后,所有对该系统的调整和优化也将在在线环境中开展和完成。
6)多个不同应用会通过各自的有向任务图进行表示,并将被部署在一个大数据计算平台中,这就需要整个计算平台可以有效地为各个有向任务图分配合理资源,并保证满足用户服务级目标。同时各个资源间需要公平地竞争资源、合理地共享资源,特别是要满足不同时间点各应用间系统资源的公平使用。
什么是流批一体架构?
流处理和批处理都是常用的数据处理方式,它们各有优劣。流处理通常用于需要实时响应的场景,如在线监控和警报系统等。而批处理则通常用于离线数据分析和挖掘等大规模数据处理场景。选择合适的处理方式取决于具体的业务需求和数据处理场景。
以前很多系统的架构都是采用的Lambda架构,它将所有的数据分成了三个层次:批处理层、服务层和速率层,每个层次都有自己的功能和目的。
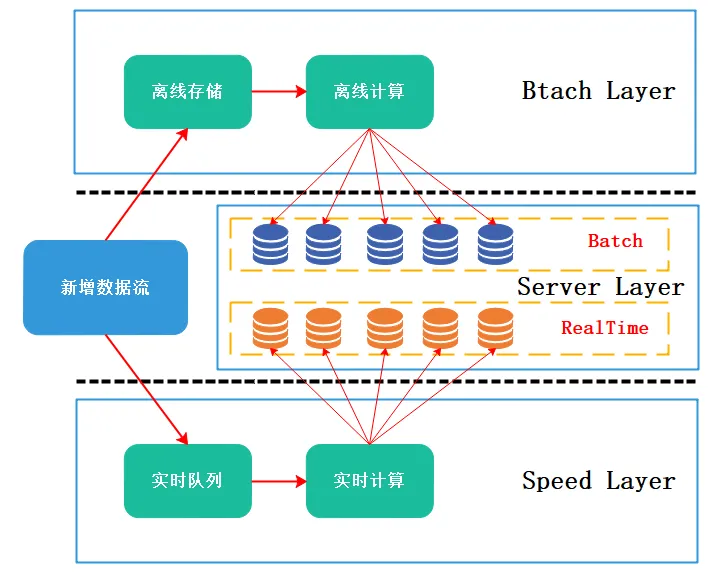
- 批处理层:负责离线计算和历史数据的存储。
- 服务层:负责在线查询和实时数据的处理。
- 速率层:负责对实时数据进行快速的处理和查询。
这种架构,需要一套流处理平台和一套批处理平台,这就可能导致了一些问题:
- 资源浪费:一般来说,白天是流计算的高峰期,此时需要更多的计算资源,相对来说,批计算就没有严格的限制,可以选择凌晨或者白天任意时刻,但是,流计算和批计算的资源无法进行混合调度,无法对资源进行错峰使用,这就会导致资源的浪费。
- 成本高:流计算和批计算使用的是不同的技术,意味着需要维护两套代码,不论是学习成本还是维护成本都会更高。
- 数据一致性:两套平台都是不一样的,可能会导致数据不一致的问题。
因此,流批一体诞生了!
流批一体的技术理念最早是2015年提出的,初衷就是让开发能用同一套代码和API实现流计算和批计算,但是那时候实际落地的就少之又少,阿里巴巴在2020年双十一首次实际落地。
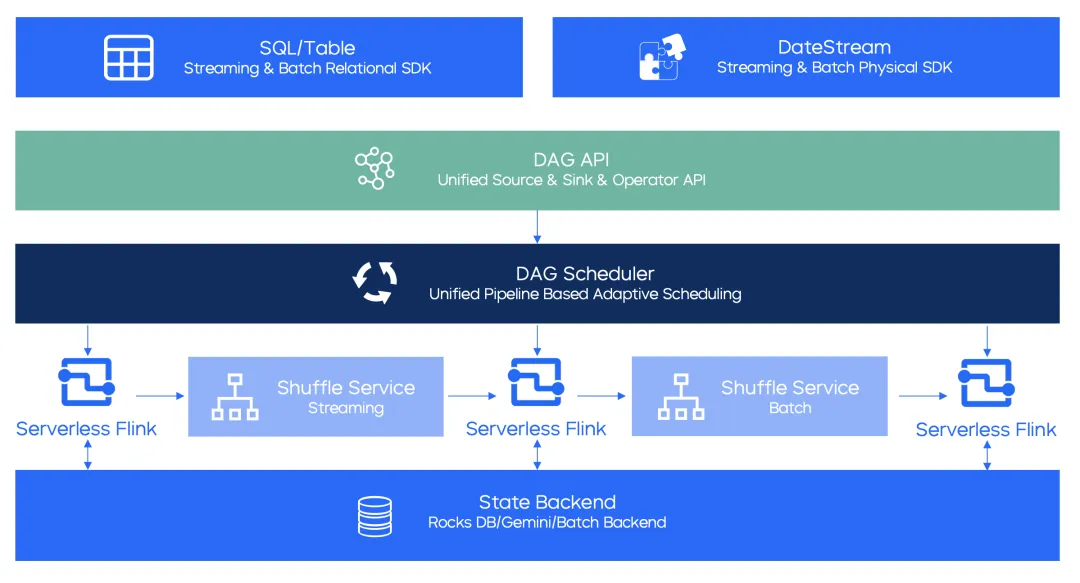
Flink流批一体架构:
目前有哪些流处理的框架?
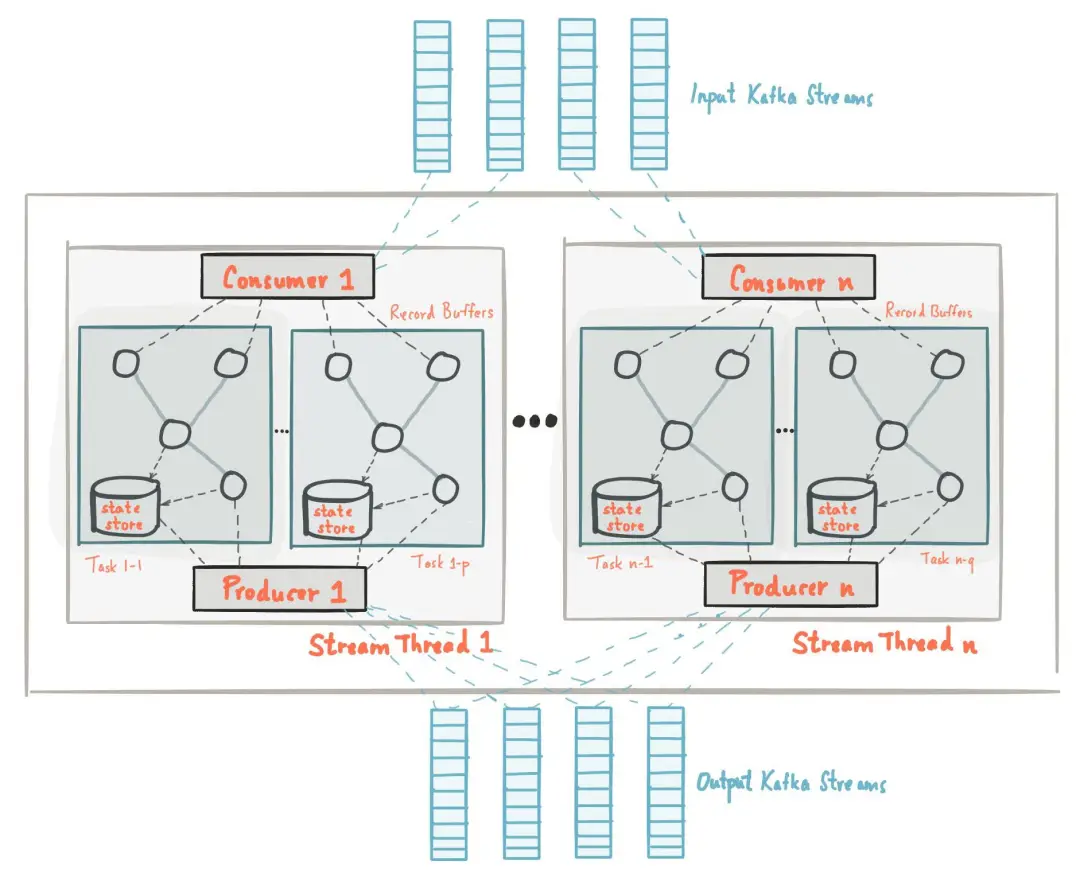
Kafka Stream
基于 Kafka 的一个轻量级流式计算框架,我们可以使用它从一个或多个输入流中读取数据,对数据进行转换和处理,然后将结果写入一个或多个输出流中。
工作原理:读取数据流 -> 数据转换/时间窗口处理/状态管理 -> 任务调度 -> 输出结果
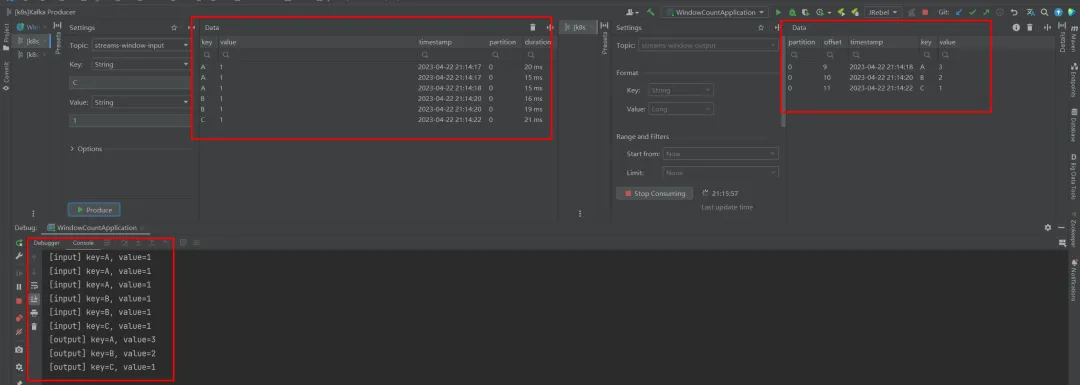
简单示例:统计20秒内每个input的key输入的次数,典型的例子:统计网站20秒内用户的点击次数。
public class WindowCountApplication {
private static final String STREAM_INPUT_TOPIC = "streams-window-input";
private static final String STREAM_OUTPUT_TOPIC = "streams-window-output";
public static void main(String[] args) {
Properties props = new Properties();
props.put(APPLICATION_ID_CONFIG, WindowCountApplication.class.getSimpleName());
props.put(BOOTSTRAP_SERVERS_CONFIG, KafkaConstant.BOOTSTRAP_SERVERS);
props.put(DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
builder.stream(STREAM_INPUT_TOPIC, Consumed.with(Serdes.String(), Serdes.String()))
.peek((key, value) -> Console.log("[input] key={}, value={}", key, value))
.groupByKey()
.windowedBy(SessionWindows.ofInactivityGapWithNoGrace(Duration.ofSeconds(20)))
.count()
.toStream()
.map((key, value) -> new KeyValue<>(key.key(), value))
.peek((key, value) -> Console.log("[output] key={}, value={}", key, value))
.to(STREAM_OUTPUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams kStreams = new KafkaStreams(builder.build(), props);
Runtime.getRuntime().addShutdownHook(new Thread(kStreams::close));
kStreams.start();
}
}运行结果:{key}={value},发送了3次A=1,2次B=1,以及1次C=1,统计结果在预期之内,即A出现3次,B出现2次,C出现1次。
Pulsar Function
和 Kafka Stream 类似,也是轻量级的流处理框架,不过它是基于 Pulsar 实现的一个流处理框架,同样的,也是从一个或多个输入流中读取数据,对数据进行转换和处理,然后将结果写入一个或多个输出流中。感兴趣的可以参考我之前写的文章:Pulsar Function简介以及使用
工作原理:订阅消息流 -> 处理消息 -> 发布处理结果
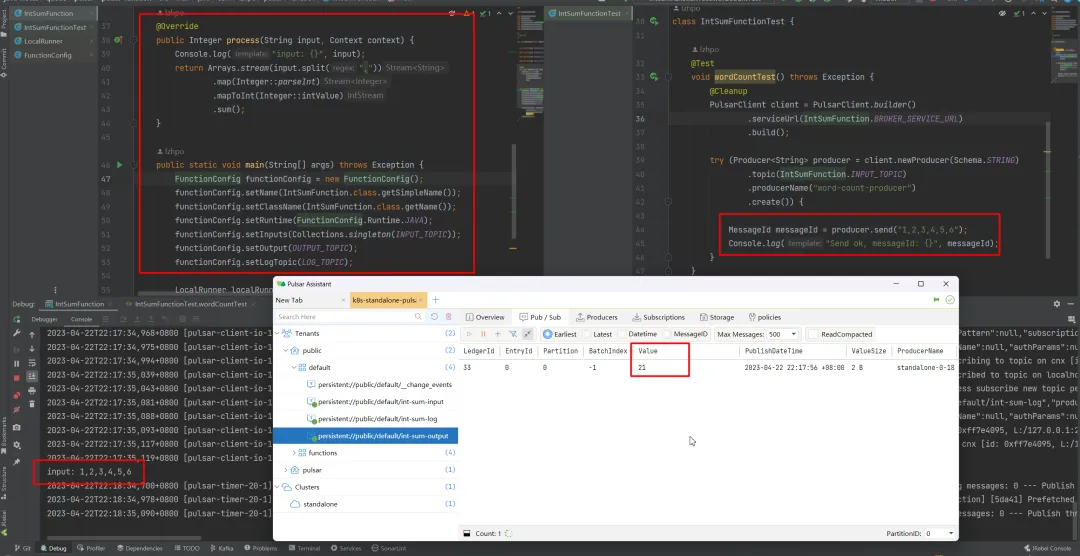
简单示例:LocalRunner模式,按照逗号“,”去切分 input topic 的消息,然后转换成数字进行求和,结果发送至 output topic。
public class IntSumFunction implements Function<String, Integer> {
public static final String BROKER_SERVICE_URL = "pulsar://localhost:6650";
public static final String INPUT_TOPIC = "persistent://public/default/int-sum-input";
public static final String OUTPUT_TOPIC = "persistent://public/default/int-sum-output";
public static final String LOG_TOPIC = "persistent://public/default/int-sum-log";
@Override
public Integer process(String input, Context context) {
Console.log("input: {}", input);
return Arrays.stream(input.split(","))
.map(Integer::parseInt)
.mapToInt(Integer::intValue)
.sum();
}
public static void main(String[] args) throws Exception {
FunctionConfig functionConfig = new FunctionConfig();
functionConfig.setName(IntSumFunction.class.getSimpleName());
functionConfig.setClassName(IntSumFunction.class.getName());
functionConfig.setRuntime(FunctionConfig.Runtime.JAVA);
functionConfig.setInputs(Collections.singleton(INPUT_TOPIC));
functionConfig.setOutput(OUTPUT_TOPIC);
functionConfig.setLogTopic(LOG_TOPIC);
LocalRunner localRunner = LocalRunner.builder()
.brokerServiceUrl(BROKER_SERVICE_URL)
.functionConfig(functionConfig)
.build();
localRunner.start(true);
}
}运行结果:1+2+3+4+5+6=21
Flink
- 一种流处理框架,具有低延迟、高吞吐量和高可靠性的特性。
- 支持流处理和批处理,并支持基于事件时间和处理时间的窗口操作、状态管理、容错机制等。
- 提供了丰富的算子库和 API,支持复杂的数据流处理操作。
工作原理:接收数据流 -> 数据转换 -> 数据处理 -> 状态管理 -> 容错处理 -> 输出结果
简单来说就是将数据流分成多个分区,在多个任务中并行处理,同时维护状态信息,实现高吞吐量、低延迟的流处理。
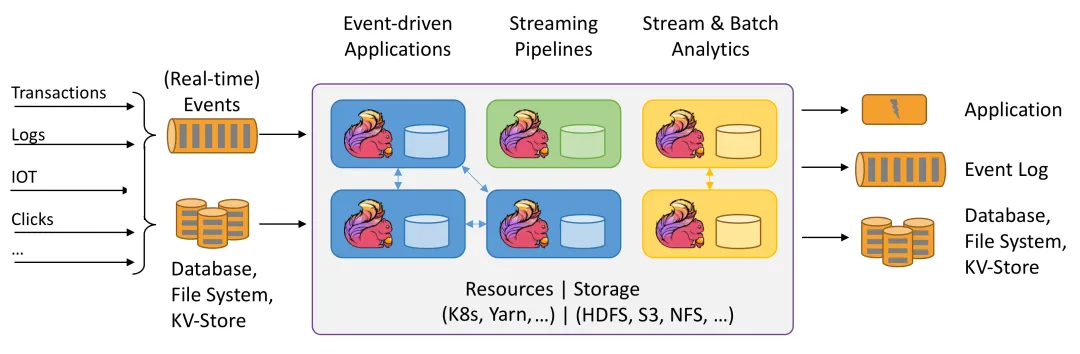
简单示例:从9966端口读取数据,将输入的句子用空格分割成多个单词,每隔5秒做一次单词统计。
public class WindowSocketWordCount {
private static final String REGEX = " ";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketTextStreamSource = env.socketTextStream("localhost", 9966);
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = socketTextStreamSource
.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (sentence, collector) -> {
for (String word : sentence.split(REGEX)) {
collector.collect(new Tuple2<>(word, 1));
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
streamOperator.print();
env.execute();
}
}运行结果:
Storm
- 一个开源的流处理引擎,旨在实现快速、可靠的数据流处理。
- 是业界最早出现的一个流处理框架(2011年),但是现在已经有许多其它优秀的流处理框架了,所以它在现在并不是唯一选择。
工作原理:将数据流分成多个小的流(也称为tuple),并将这些小流通过一系列的操作(也称为bolt)进行处理。
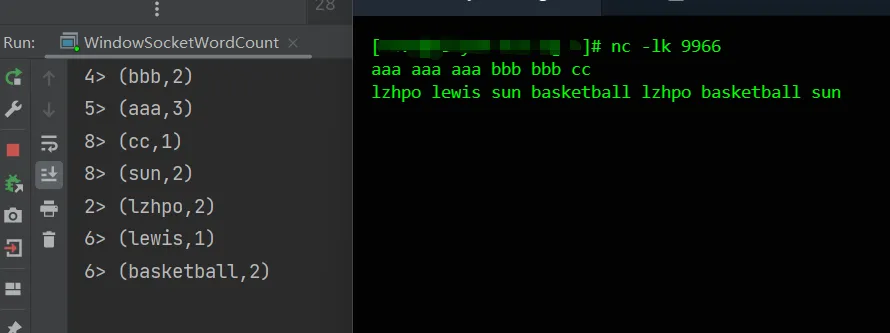
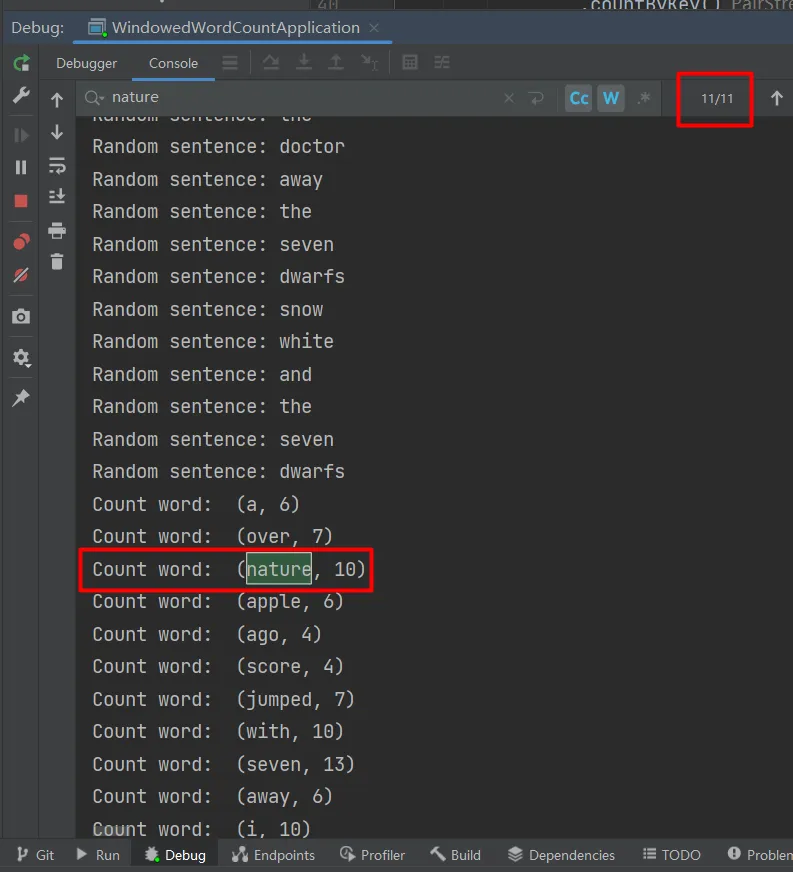
简单示例:在本地模式,使用Storm内置的RandomSentenceSpout充当数据源进行测试,用空格拆分生成的句子为多个单词,统计每个单词出现次数。
public class WindowedWordCountApplication {
public static void main(String[] args) throws Exception {
StreamBuilder builder = new StreamBuilder();
builder.newStream(new RandomSentenceSpout(), new ValueMapper<String>(0), 2)
.window(TumblingWindows.of(Duration.seconds(2)))
.flatMap(sentence -> Arrays.asList(sentence.split(" ")))
.peek(sentence -> Console.log("Random sentence: {}", sentence))
.mapToPair(word -> Pair.of(word, 1))
.countByKey()
.peek(pair -> Console.log("Count word: ", pair.toString()));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("windowedWordCount", new Config(), builder.build());
Utils.sleep(20000);
cluster.shutdown();
}
}内置的RandomSentenceSpout随机生成数据关键源代码:
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{
sentence("the cow jumped over the moon"), sentence("an apple a day keeps the doctor away"),
sentence("four score and seven years ago"), sentence("snow white and the seven dwarfs"), sentence("i am at two with nature")
};
final String sentence = sentences[rand.nextInt(sentences.length)];
LOG.debug("Emitting tuple: {}", sentence);
collector.emit(new Values(sentence));
}运行结果:随机找一个单词“nature”,统计的次数为10次。
Spark Streaming
基于 Spark API 的扩展,支持对实时数据流进行可扩展、高吞吐量、容错的流处理。
工作原理:接收实时输入数据流并将数据分成批次,然后由 Spark 引擎处理以批次生成最终结果流。
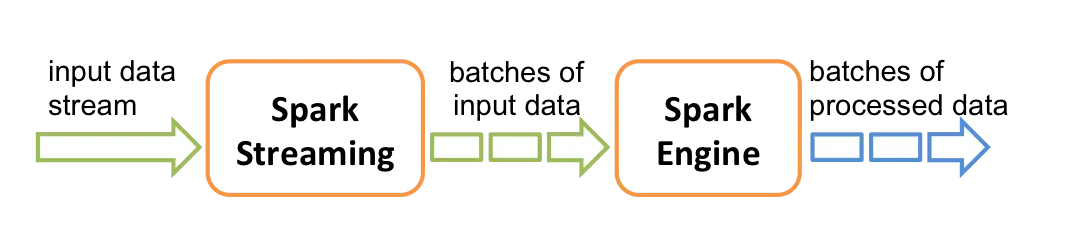
简单示例:从 kafka 的 spark-streaming topic 读取数据,按照空格“ ”拆分,统计每一个单词出现的次数并打印。
public class JavaDirectKafkaWordCount {
private static final String KAFKA_BROKERS = "localhost:9092";
private static final String KAFKA_GROUP_ID = "spark-consumer-group";
private static final String KAFKA_TOPICS = "spark-streaming";
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
Configurator.setRootLevel(Level.WARN);
SparkConf sparkConf = new SparkConf().setMaster("local[1]").setAppName("spark-streaming-word-count");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(2));
Set<String> topicsSet = new HashSet<>(Arrays.asList(KAFKA_TOPICS.split(",")));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BROKERS);
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, KAFKA_GROUP_ID);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topicsSet, kafkaParams));
JavaDStream<String> linesStream = messages.map(ConsumerRecord::value);
JavaPairDStream<String, Integer> wordCountStream = linesStream
.flatMap(line -> Arrays.asList(SPACE.split(line)).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey(Integer::sum);
wordCountStream.print();
streamingContext.start();
streamingContext.awaitTermination();
}
}运行结果:
如何选择流处理框架?
- 简单数据流处理
如果只是轻量级使用的话,可以结合技术栈使用消息中间件自带的流处理框架就更节省成本。
- 使用的 Kafka 就用 Kafka Stream。
- 使用的 Pulsar 就用 Pulsar Function。
- 复杂数据流场景
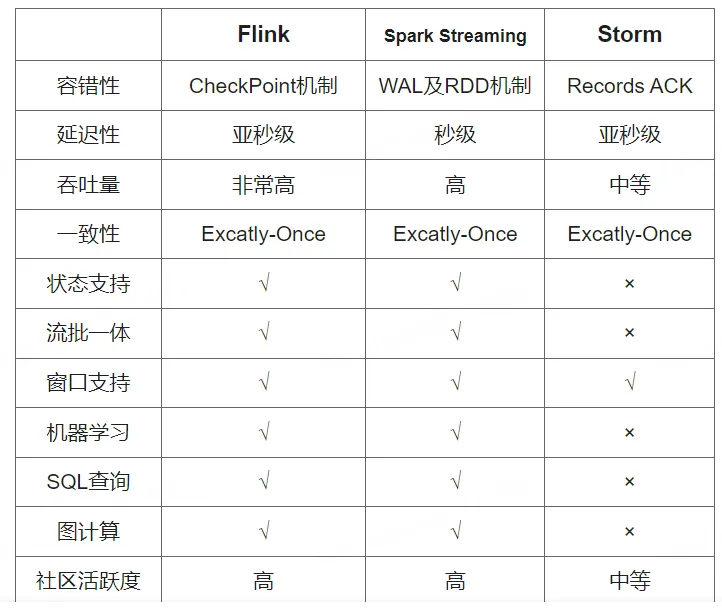
综上,可以结合数据规模、技术栈、处理延迟功能特性、未来的考虑、社区活跃度、成本和可用性等等进行选择。