译者 | 布加迪
审校 | 重楼
是否曾经将您的Python代码与经验丰富的开发人员的代码进行比较,感到明显的差异?尽管可以从在线资源学习Python,但初学者代码和专家代码之间通常存在差距。这是由于经验丰富的开发人员坚持奉行社区确保的最佳实践。这些实践在在线教程中经常被忽视,但对于大规模应用程序而言至关重要。我在本文中将介绍生产级代码中使用的7个技巧,确保代码更清晰、更有条理。
1. 类型提示和注释
Python是一种动态类型的编程语言,在运行时推断变量类型。虽然它提高了灵活性,但在协作环境中大大降低了代码的可读性和可理解性。
Python支持函数声明中的类型提示,充当函数参数类型和返回类型的注释。尽管Python在运行时不强制执行这些类型,但它仍然很有帮助,因为它使您的代码更容易被其他人和您自己理解。
从一个基本的例子开始,这是一个带类型提示的简单函数声明:
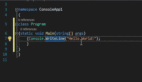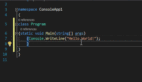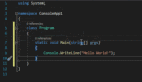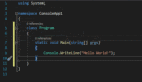
Def sum(a: int, b: int) -> int:
Return a + b在这里,尽管函数不言自明,但我们看到函数参数和返回值都表示为int类型。函数体可以是一行,也可以是几百行。然而,我们只需查看函数声明就能理解前置条件和返回类型。
其中,这些注释只是为了清晰和指引,它们并不在执行期间强制执行类型。所以,即使您传入不同类型的值,比如字符串而不是整数,函数仍然会运行。但是要小心:如果您不提供预期的类型,它可能会在运行时导致意外的行为或错误。比如在提供的示例中,函数sum()需要两个整数作为参数。但是如果您尝试添加一个字符串和一个整数,Python会抛出运行时错误。为什么?因为它不知道如何将字符串和整数相加!这就好比试图把苹果和橘子加在一起,那毫无意义。然而,如果两个参数都是字符串,它将毫无问题地将它们连接起来。
下面是带有测试用例的澄清版本:
print(sum(2,5)) # 7
# print(sum('hello', 2)) # TypeError: can only concatenate str (not "int") to str
# print(sum(3,'world')) # TypeError: unsupported operand type(s) for +: 'int' and 'str'
print(sum('hello', 'world')) # helloworld用于高级类型提示的typing库
针对高级注释,Python包含typing标准库。不妨以一种更有趣的方式来看其用法。
from typing import Union, Tuple, List
import numpy as np
def sum(variable: Union[np.ndarray, List]) -> float:
total = 0
# function body to calculate the sum of values in iterable
return total这里,我们修改了同一个求和函数,它现在接受numpy数组或列表iterable。它计算并以浮点值的形式返回它们的和。我们利用typing库中的Union注释来指定变量参数可以接受的可能类型。
不妨进一步更改函数声明,以显示列表成员还应该是类型float。
def sum(variable: Union[np.ndarray, List[float]]) -> float:
total = 0
# function body to calculate the sum of values in iterable
return total这些只是帮助理解Python中的类型提示的一些入门示例。随着项目规模扩大,代码库变得更模块化,类型注释显著地增强了可读性和可维护性。typing库提供了一组丰富的特性,包括可选的各种iterable、泛型以有力支持自定义类型的功能,使开发人员能够精确而清晰地表达复杂的数据结构和关系。
2. 编写防御函数和输入验证
尽管类型提示似乎很有帮助,但它仍然容易出错,因为未强制执行注释。这些只是开发人员的额外文档,但如果使用不同的参数类型,函数仍然会执行。因此,需要以一种防御性的方式为函数和代码强制执行前置条件。因此,我们手动检查这些类型,违反条件时抛出适当的错误。
下面的函数显示了如何使用输入参数计算利息。
def calculate_interest(principal, rate, years):
return principal * rate * years这是简单的操作,但这个函数是否适用于所有可能的解决方案?不,不适用于无效值作为输入传递的个别情况。我们需要确保输入值在一个有效的范围内,那样函数才能正确执行。实际上,必须满足一些预设值条件,函数实现才能正确。
我们做这一步,如下所示:
from typing import Union
def calculate_interest(
principal: Union[int, float],
rate: float,
years: int
) -> Union[int, float]:
if not isinstance(principal, (int, float)):
raise TypeError("Principal must be an integer or float")
if not isinstance(rate, float):
raise TypeError("Rate must be a float")
if not isinstance(years, int):
raise TypeError("Years must be an integer")
if principal <= 0:
raise ValueError("Principal must be positive")
if rate <= 0:
raise ValueError("Rate must be positive")
if years <= 0:
raise ValueError("Years must be positive")
interest = principal * rate * years
return interest注意,我们使用条件语句进行输入验证。Python有时也用于此目的的断言语句。然而,用于输入验证的断言并不是最佳实践,因为它们很容易被禁用,会导致生产环境中的意外行为。对于输入验证和强制执行前置条件、后置条件以及代码不变量,最好使用显式Python条件表达式。
3. 使用生成器和Yield语句进行延迟加载
考虑这样一个场景:您拥有一个大型文档数据集。您需要处理文档,并对每个文档执行某些操作。然而由于文件太大,您无法同时将所有文档加载到内存中并对它们进行预处理。
一种可行的解决方案是只在需要时将文档加载到内存中,并且一次只处理一个文档,这也称为延迟加载。即使我们知道需要什么文档,也不会加载资源,除非有需要。当我们的代码中没有使用大量文档时,不需要在内存中保留它们。这正是生成器和yield语句解决这个问题的方法。
生成器允许延迟加载,从而提高Python代码执行的内存效率。值可以根据需要动态生成,减少了内存占用资源,并提高了执行速度。
import os
def load_documents(directory):
for document_path in os.listdir(directory):
with open(document_path) as _file:
yield _file
def preprocess_document(document):
filtered_document = None
# preprocessing code for the document stored in filtered_document
return filtered_document
directory = "docs/"
for doc in load_documents(directory):
preprocess_document(doc)在上面的函数中,load_documents函数使用yield关键字。该方法返回类型<class generator>的对象。当我们迭代处理这个对象时,它从最后一个yield语句所在的位置继续执行。因此,加载和处理单个文档,提高了Python代码的效率。
4. 使用上下文管理器防止内存泄漏
对任何语言来说,有效地利用资源最重要。我们只在需要时才通过使用生成器在内存中加载一些内容,如上所述。然而,当我们的程序不再需要某个资源时,关闭该资源同样重要。我们需要防止内存泄漏,并执行适当的资源拆卸以节省内存。
上下文管理器简化了资源设置和拆卸的常见用例。资源不再需要时,释放它们很重要,即使在出现异常和失败的情况下也是如此。上下文管理器使用自动清理,同时保持代码简洁易读,降低内存泄漏的风险。
资源可以有多种变体,比如数据库连接、锁、线程、网络连接、内存访问和文件句柄。不妨关注最简单的情况:文件句柄。这里的挑战是确保每个打开的文件只关闭一次。关闭文件失败可能导致内存泄漏,而试图关闭文件句柄两次会导致运行时错误。为了解决这个问题,应该将文件句柄封装在try-except-finally块中。这确保了文件被正确关闭,不管执行过程中是否发生了错误。下面是具体实现的样子:
file_path = "example.txt"
file = None
try:
file = open(file_path, 'r')
contents = file.read()
print("File contents:", contents)
finally:
if file is not None:
file.close()然而,Python提供了一个使用上下文管理器的更优雅的解决方案,它自动处理资源管理。下面介绍我们如何使用文件上下文管理器简化上述代码:
file_path = "example.txt"
with open(file_path, 'r') as file:
contents = file.read()
print("File contents:", contents)在这个版本中,我们不需要显式关闭文件。上下文管理器负责处理它,防止潜在的内存泄漏。
虽然Python为文件处理提供了内置的上下文管理器,但我们也可以为自定义类和函数创建自己的上下文管理器。针对基于类的实现,我们定义了__enter__和__exit__dunder方法。这里有一个基本的例子:
class CustomContextManger:
def __enter__(self):
# Code to create instance of resource
return self
def __exit__(self, exc_type, exc_value, traceback):
# Teardown code to close resource
return None现在,我们可以在“with ”块中使用这个自定义的上下文管理器:
with CustomContextManger() as _cm:
print("Custom Context Manager Resource can be accessed here")这种方法保持了上下文管理器简洁明了的语法,同时允许我们根据需要处理资源。
5. 用装饰器分离关注点
我们经常看到显式地实现具有相同逻辑的多个函数。这是普遍存在的代码风格,过多的代码重复会使代码难以维护和不可扩展。装饰器用于将类似的功能封装在一个地方。当一个相似的功能被多个其他函数使用时,我们可以通过在装饰器中实现通用功能来减少代码重复。它遵循面向方面的编程(AOP)和单一职责原则。
装饰器在Django、Flask和FastAPI等Python Web框架中被大量使用。不妨通过在Python中将解释器用作日志记录的中间件来解释装饰器的效果。在生产环境中,我们需要知道服务一个请求需要多长时间。这是一个常见的用例,将在所有端点之间共享。因此,不妨实现一个简单的基于装饰器的中间件,它将记录服务请求所花费的时间。
下面的虚拟函数用于服务用户请求。
def service_request():
# Function body representing complex computation
return True现在,我们需要记录这个函数执行所花费的时间。一种方法是在这个函数中添加日志记录,如下所示:
import time
def service_request():
start_time = time.time()
# Function body representing complex computation
print(f"Time Taken: {time.time() - start_time}s")
return True虽然这种方法有效,但它会导致代码重复。如果我们添加更多的路由,将不得不在每个函数中重复日志代码。这增加了代码重复,因为这种共享日志功能需要添加到每个实现中。我们使用装饰器进行移除。
日志中间件将按以下方式来实现:
def request_logger(func):
def wrapper(*args, **kwargs):
start_time = time.time()
res = func()
print(f"Time Taken: {time.time() - start_time}s")
return res
return wrapper在这个实现中,外部函数是装饰器,它接受函数作为输入。内部函数实现日志功能,而输入函数在包装器中被调用。
现在,我们只需用request_logger装饰器装饰原来的service_request函数:
@request_logger
def service_request():
# Function body representing complex computation
return True使用@符号将service_request函数传递给request_logger装饰器。它记录所花费的时间,并在不修改代码的情况下调用原始函数。这种关注点分离让我们得以以类似的方式轻松地将日志记录添加到其他服务方法中,如下所示:
@request_logger
def service_request():
# Function body representing complex computation
return True
@request_logger
def service_another_request():
# Function body
return True6. 匹配Case语句
匹配语句是在Python3.10中引入的,所以它是Python语法的一个相当新的添加。它允许更简单、更易读的模式匹配,避免了典型if- if-else语句中过多的样板文件和分支。
针对模式匹配,匹配case语句是更自然的编写方式,因为它们不一定需要像条件语句中那样返回布尔值。来自Python文档中的以下示例展示了匹配case语句声明如何比条件语句更具灵活性。
def make_point_3d(pt):
match pt:
case (x, y):
return Point3d(x, y, 0)
case (x, y, z):
return Point3d(x, y, z)
case Point2d(x, y):
return Point3d(x, y, 0)
case Point3d(_, _, _):
return pt
case _:
raise TypeError("not a point we support")根据文档,如果没有模式匹配,这个函数的实现将需要几次isinstance()检查、一两个len()调用以及一个更复杂的控制流。揭开底层,匹配示例和传统Python版本转换成相似的代码。然而,熟悉模式匹配后,可能会首选匹配case方法,因为它提供了更清晰、更自然的语法。
总的来说,匹配case语句为模式匹配提供了一种经过改进的替代方案,这可能会在较新的代码库中变得更加普遍。
7. 外部配置文件
在生产环境中,我们的大部分代码依赖外部配置参数,比如API密钥、密码和各种设置。出于可扩展性和安全性的考虑,将这些值直接硬编码到代码中被认为是糟糕的做法。相反,将配置与代码本身分开来至关重要。我们通常使用JSON或YAML等配置文件来存储这些参数,确保它们易于访问代码,无需直接嵌入到其中。
一种日常的用例是实现多个连接参数的数据库连接。
我们可以将这些参数保留在一个单独的YAML文件中。
# config.yaml
database:
host: localhost
port: 5432
username: myuser
password: mypassword
dbname: mydatabase为了处理这个配置,我们定义了一个名为DatabaseConfig的类:
class DatabaseConfig:
def __init__(self, host, port, username, password, dbname):
self.host = host
self.port = port
self.username = username
self.password = password
self.dbname = dbname
@classmethod
def from_dict(cls, config_dict):
return cls(**config_dict)在这里,from_dict类方法充当DatabaseConfig类的构建器方法,允许我们从字典创建数据库配置实例。
在我们的主代码中,我们可以使用参数hydration和构建器方法来创建数据库配置。通过读取外部YAML文件,我们提取数据库字典,并使用它为配置类创建实例:
import yaml
def load_config(filename):
with open(filename, "r") as file:
return yaml.safe_load(file)
config = load_config("config.yaml")
db_config = DatabaseConfig.from_dict(config["database"])这种方法不需要将数据库配置参数直接硬编码到代码中。它还比使用参数解析器有所改进,因为我们不再需要在每次运行代码时传递多个参数。此外,通过参数解析器访问配置文件路径,我们可以确保代码保持灵活性,而不依赖硬编码路径。这种方法便于更容易管理配置参数,可以随时修改配置参数,不需要更改代码库。
结束语
我们在本文中讨论了业界用于生产就绪代码的一些最佳实践。这些都是常见的行业实践,可以缓解人们在实际情形中可能面临的多个问题。
值得一提的是,尽管有所有这些最佳实践,文档、文档字符串和测试驱动开发是迄今为止最重要的实践。重要的是要考虑一个函数应该做什么,然后将所有的设计决策和实现记入文档,因为随着时间的推移,人们不断更改代码库。
原文标题: Mastering Python: 7 Strategies for Writing Clear, Organized, and Efficient Code,作者:Kanwal Mehreen
链接:https://www.kdnuggets.com/mastering-python-7-strategies-for-writing-clear-organized-and-efficient-code