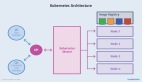
本kubernetes教程解释了如何创建kubernetes作业和cronjobs,以及它的基础知识、用例和一些提示和技巧。

什么是Kubernetes Job?
Kubernetes job和cronjob是Kubernetes对象,主要用于短期和批处理工作负载。
kubernetes作业对象基本上部署了一个pod,但它是为了完成而运行的,而不是像deployment、replicasets、复制控制器和DaemonSets这样的对象,它们是持续运行的。
这意味着,作业将一直运行,直到作业中指定的任务完成,如果pods给出退出代码0,则作业将退出。该任务可以是shell脚本执行、API调用或执行数据转换并将其上传到云存储的java python执行。
然而,在正常的Kubernetes部署中,无论退出代码如何,部署对象都会在终止或抛出错误时创建新的pod,以保持部署所需的状态。
在作业运行期间,如果承载pod的节点失败,作业pod将自动重新调度到另一个节点。
Kubernetes Jobs和CronJobs用例
Kubernetes作业的最佳用例是:
- 批处理:假设您希望每天运行一次批处理任务,或者在特定的计划中运行一次。它可以是从存储或数据库中读取文件,并将其提供给服务以处理文件。
- 操作/特别任务:假设您想要运行运行数据库清理活动的脚本/代码,或者甚至备份kubernetes集群本身。
在我参与的一个项目中,我们将Kubernetes作业广泛用于ETL工作负载。
如何创建Kubernetes作业
在这个例子中,我将使用一个Ubuntu容器,它运行一个shell脚本,该脚本有一个for循环,根据您传递给容器的参数回显消息。参数应该是一个数字,决定循环运行的次数以回显消息。
例如,如果传递100作为参数,shell脚本将回显消息100次,容器将退出。
你可以在这里查看Dockerfile和shell脚本-> kube-job-example Docker configs[1]
让我们从一个简单设置的作业开始。
步骤1:创建一个任务。使用我们自定义的Docker映像,以100作为命令参数。值100将作为参数传递给docker ENTRYPOINT脚本。
apiVersion: batch/v1
kind: Job
metadata:
name: kubernetes-job-example
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: kubejob
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: devopscube/kubernetes-job-demo:latest
args: ["100"]
restartPolicy: OnFailure步骤2:让我们使用kubectl创建一个Job.yaml文件。Job部署在默认名称空间中。
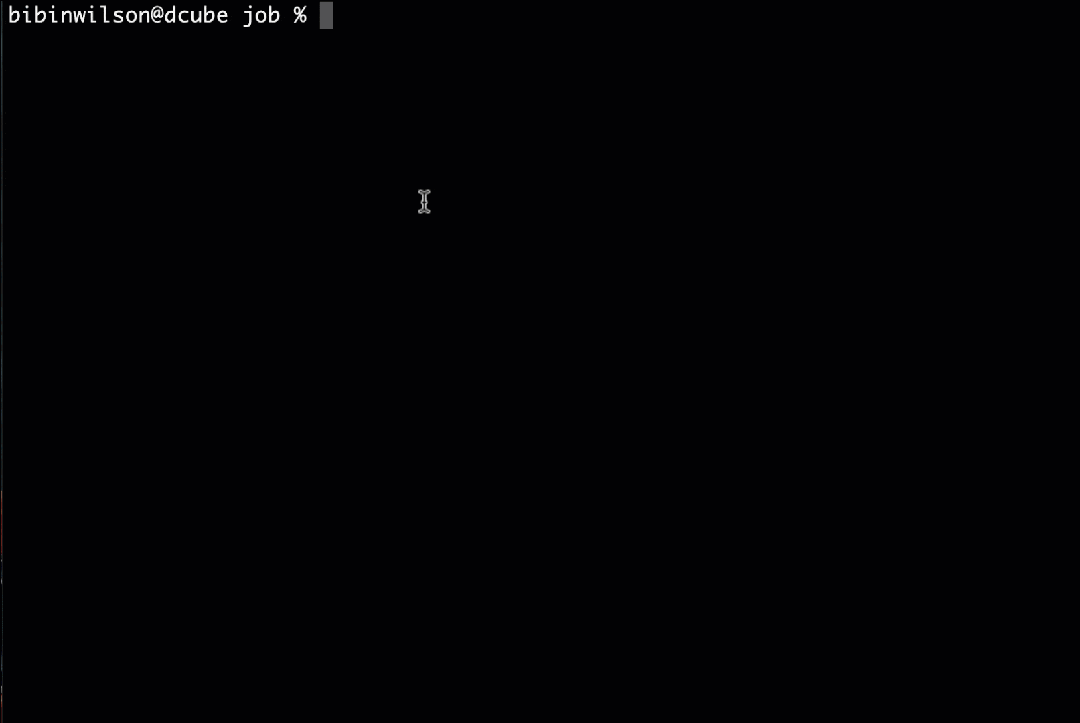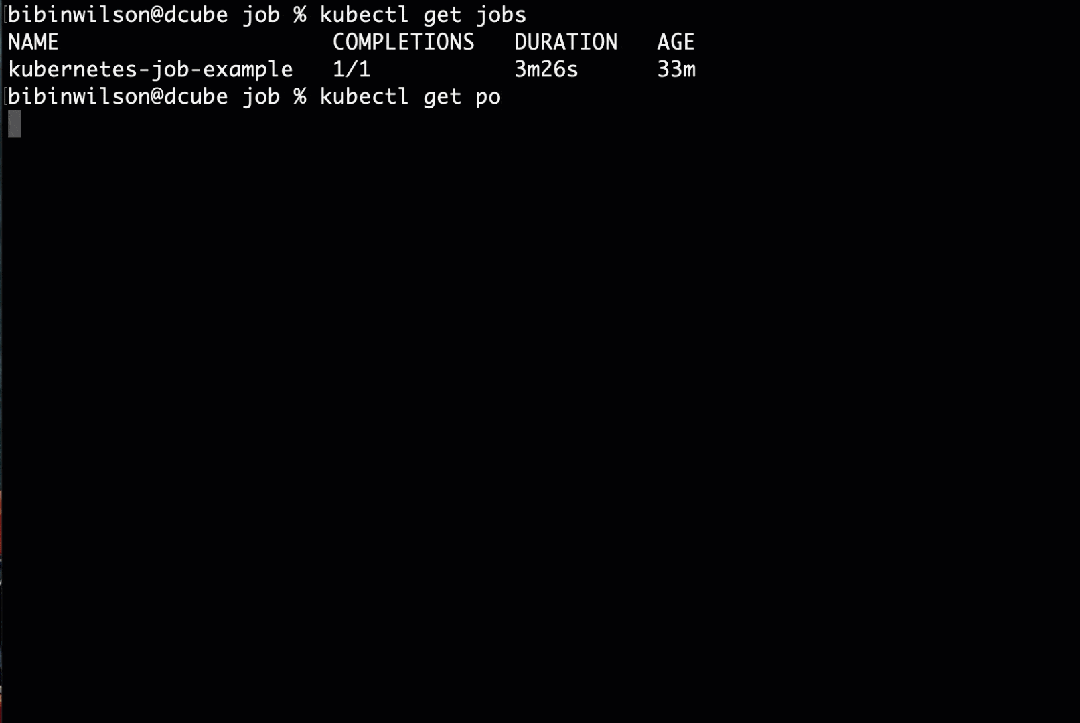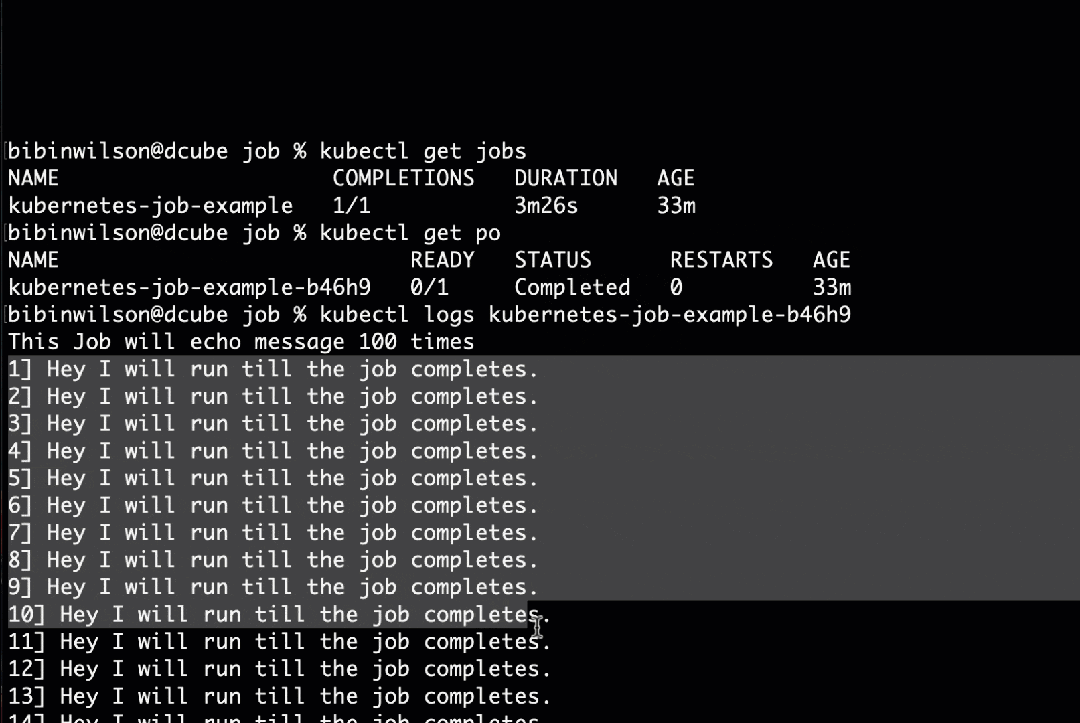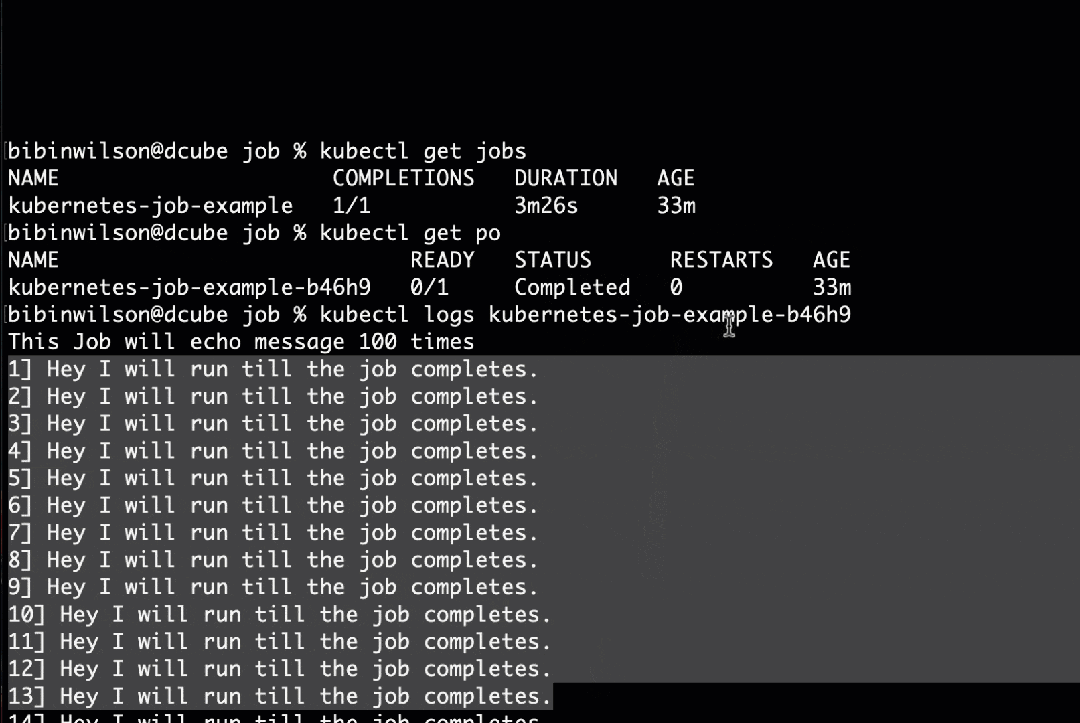
kubectl apply -f job.yaml步骤3:使用kubectl获取Job的状态。
kubectl get jobs步骤4:现在,使用kubectl获取pod列表。
kubectl get po步骤5:您可以使用kubectl获取Job pod日志。将pod名称替换为您在输出中看到的pod名称。
kubectl logs kubernetes-job-example-bc7s9 -f您应该看到如下所示的输出。
多个Job Pod和并行性
在部署作业时,您可以让它在多个具有并行性的pod上运行。
例如,在一个Job中,如果您希望并行运行6个pod和2个pod,则需要将以下两个参数添加到Job清单中。
completions: 6
parallelism: 2- completions: 6 指定 job 需要成功运行 Pods 的次数为 6
- parallelism: 3 指定 job 并发运行 Pods 的数量为 3
下面是带有这些参数的清单文件。
apiVersion: batch/v1
kind: Job
metadata:
name: kubernetes-parallel-job
labels:
jobgroup: jobexample
spec:
completions: 6
parallelism: 2
template:
metadata:
name: kubernetes-parallel-job
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: devopscube/kubernetes-job-demo:latest
args: ["100"]
restartPolicy: OnFailure并行pod处理的一个用例是消息队列上的批处理操作。假设您有一个消息队列,其中在每天的特定时间要处理数千条消息。
您可以将消息处理代码作为具有并行性的Job运行,以加快处理速度。尽管所有pod使用相同的消息处理代码,但每个pod将处理来自队列的不同消息。
生成Kubernetes Job的随机名称
你不能使用单一的Job清单文件创建多个Job。Kubernetes 会抛出一个错误,指出已经存在同名的 Job。
为了解决这个问题,你可以在元数据中添加 generateName参数。例如:
apiVersion: batch/v1
kind: Job
metadata:
generateName: kube-job-
labels:
jobgroup: jobexample在上述示例中,每次运行该清单时,都会创建一个名称以 kube-job- 为前缀,后跟随机字符串的 Job。
如何创建 Kubernetes CronJob
如果你想在特定时间表上运行批处理任务,例如每两小时一次,你可以使用cron表达式创建一个Kubernetes CronJob。该任务将按照你在Job中指定的时间表自动启动。
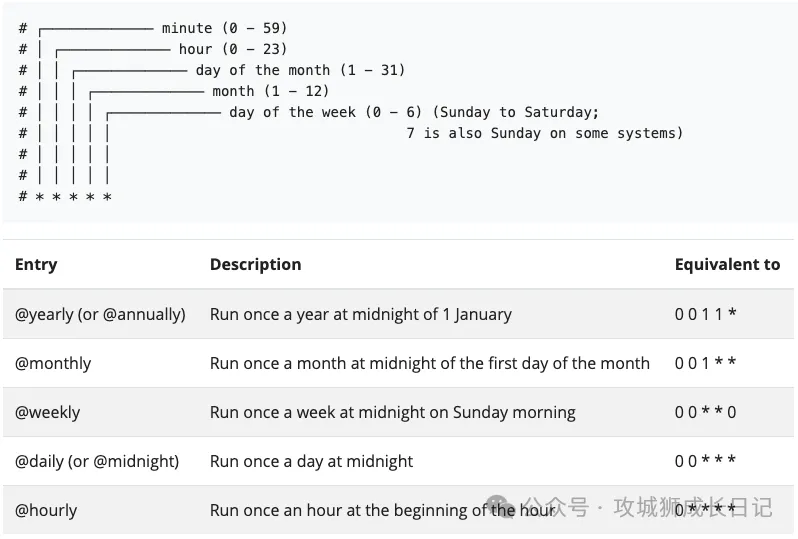
以下是如何指定cron时间表。你可以使用crontab生成器来生成你自己的时间表。
schedule: "0,15,30,45 * * * *"下图显示了 Kubernetes CronJob 的调度语法。
如果我们要将之前的Job作为CronJob每15分钟运行一次,可以使用以下清单。创建一个名为cron-job.yaml的文件,并复制以下清单内容。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: kubernetes-cron-job
spec:
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: cron-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: kube-cron-job
image: devopscube/kubernetes-job-demo:latest
args: ["100"]让我们使用kubectl部署cronjob。
kubectl create -f cron-job.yaml列出cronjob:
kubectl get cronjobs要检查Cronjob日志,您可以列出Cronjob pod,并从处于运行状态的pod或已完成的pod中获取日志。
手动运行Kubernetes CronJob
在某些情况下,您可能希望以临时方式执行cronjob。您可以通过从现有的cronjob创建一个作业来实现这一点。
例如,如果您希望手动触发cronjob,那么我们应该这样做。
kubectl create job --from=cronjob/kubernetes-cron-job manual-cron-job--from=cronjob/kubernetes-cron-job将复制cronjob模板并创建一个名为manual-cron-job的作业。
几个关键的Kubernetes Job参数
还有一些关键参数可以根据需要用于kubernetes Job/cronjobs。让我们各看一看:
- failedJobHistoryLimit和successfulJobsHistoryLimit:根据您提供的保留数删除失败和成功的作业历史记录。当您尝试列出作业时,这对于减少所有失败的条目非常有用。例如:failedJobHistoryLimit: 5 successfulJobsHistoryLimit: 10
- backoffLimit:如果您的pod失败,重试的总次数。
- activedeadlinesseconds:如果您想要指定cronjob运行时间的硬限制,可以使用此参数。例如,如果您只想运行cronjob一分钟,则可以将其设置为60。
总结
Kubernetes Job和CronJob是处理批处理任务和周期性任务的强大工具。通过定义相应的YAML文件,并使用kubectl命令创建和管理这些任务,可以轻松实现复杂的任务调度和执行。希望这篇指南能帮助你快速上手Kubernetes Job和CronJob,提升你的容器编排能力。
Reference:
[1]kube-job-example Docker configs: https://github.com/devopscube/Kubernetes-jobs-example/tree/master/Docker