













多模态大模型展现出了多种多样的能力,这些能力都通过SFT和预训练从庞大的训练数据集中学习。
但是模态之间的简单对齐可能会使得模型存在幻觉,细粒度图像感知能力差等各种问题。
已有的多模态大模型对齐方案一般采用DPO,POVID等偏好优化方法,或是蒸馏 GPT-4等昂贵闭源模型的方式来提升模型能力。
这些方法大多需要外源模型数据,这些数据构造存在很多问题,一是需要昂贵的价格,二是缺乏质量和多样性的保证。
再者说,这真的适合需要提升模型本身的分布偏好吗?
在Calibrated Self-Rewarding Vision Language Models文中,通过模型自身输出概率证明了,外来模型构造的偏好数据可能不适合用于模型的偏好学习,相较于模型自身的response,外源模型所构造的数据模型自己说出的概率很小,简单来说对于偏好数据中的负样本模型并不会犯一样的错误,对于偏好数据中的正样本模型也不会讲出那么好的response。
这种偏好数据用于偏好学习可能会引入模型自身分布的偏差导致其他错误,同时因为模型自身说同样话的概率低,用这样的数据来偏好学习增强模型收益很小。

同时传统纯文本大模型领域的Self-rewarding范式存在一定缺陷。

在此前self rewarding提供reward的模型是模型自身,当模型自身无法准确分辨偏好、所具有的知识不够强大的时候,它所提供的反馈可能不够精准或者没用导致所更新的模型的分布无法向着目标分布更新。
为了解决上述问题,来自UNC ,芝加哥大学,UMD和罗格斯大学的研究团队提出了Calibrated Self-Rewarding(CSR),多模态大模型的自我增强因为会存在一个真实图像的参照,这会使得self-rewarding的过程更加可靠。

论文地址: https://arxiv.org/pdf/2405.14622
项目地址:https://github.com/YiyangZhou/CSR
项目页面:https://dongjie-cheng.github.io/CSR.html
整个Calibrated Self-Rewarding(CSR)框架如下:
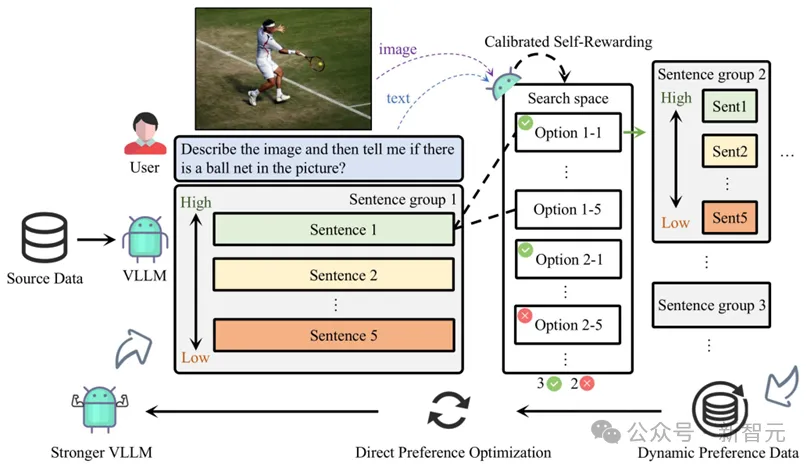
1. 通过模型本身在beam search过程中的输出构造偏好数据对,过程中的奖励来自于校准的自我奖励:LVLM对于每句话的自我生成概率 + 结合视觉约束奖励,用于奖励校准。
2. 基于每一轮构造的偏好数据在线通过DPO迭代学习。
实验
CSR相较于数据驱动的偏好学习对齐方法和模型自我反馈的方法均有较大提升。
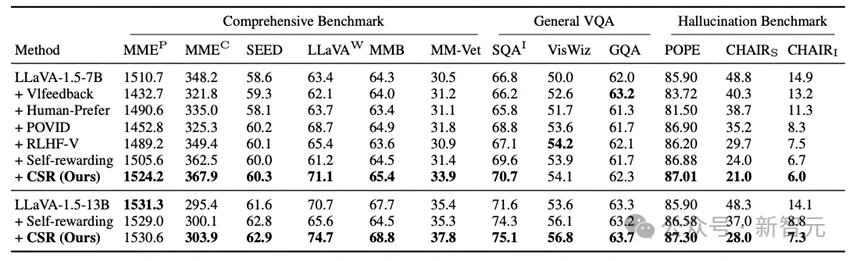
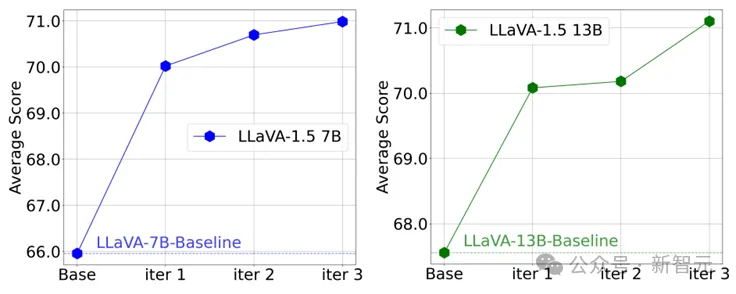
更值得注意的是,在CSR多轮在线迭代过程中,模型能逐步提升自我能力!可以看到在多个轮次中以LLaVA-1.5为例,模型在多个benchmark上的均分逐步提升。
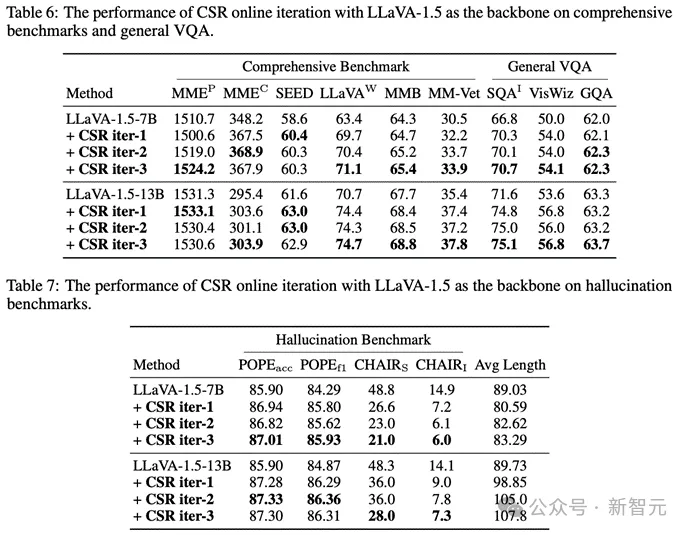
同时也可以看到特别是幻觉,在多轮迭代中是逐步减少的:
同时CSR也适用于其他模型,例如Vila:

那么在Calibrated Self-Rewarding(CSR)的过程中究竟发生了什么呢?通过可视化经过CSR迭代前后模型自身的正样本和负样本输出可以发现,经过多轮CSR学习后,模型自身说出的回复会有更高的分数:这代表模型的response更加符合图像信息;同时负样本和正样本的gap更小:这说明模型所输出的负样本倾向于正样本,模型的误差和性能下界提升。

通过可视化attention可以看到,CSR能使得LVLM更加偏重于视觉模型,同时能缓解文本attention中存在的上下文依赖问题。




























