论文:https://arxiv.org/pdf/2105.04206.pdf
开源代码:https:// github.com/WongKinYiu/yolor
1 前言
人们通过视觉、听觉、触觉以及过去的经验“理解”世界。人类经验可以通过正常学习(我们称之为显性知识)或潜意识(我们称之为隐性知识)来学习。这些通过正常学习或潜意识习得的经验将被编码并储存在大脑中。使用这些丰富的经验作为一个庞大的数据库,人类可以有效地处理数据,即使它们是事先不可见的。
在今天分享中,研究者提出了一个统一的网络,将隐性知识和显性知识编码在一起,就像人脑可以从正常学习和潜意识学习中学习知识一样。统一网络可以生成统一的表示以同时服务于各种任务。可以在卷积神经网络中执行内核空间对齐、预测优化和多任务学习。结果表明,当隐性知识被引入神经网络时,它有利于所有任务的性能。研究者进一步分析了从所提出的统一网络中学习到的隐式表示,它在捕捉不同任务的物理意义方面表现出很强的能力。

2 背景
如下图所示,人类可以从不同角度分析同一条数据。然而,经过训练的卷积神经网络模型通常只能实现一个目标。一般来说,可以从经过训练的CNN中提取的特征通常对其他类型的问题适应性较差。造成上述问题的主要原因是我们只从神经元中提取特征,没有使用CNN中丰富的隐式知识。当真正的人脑在运行时,上述隐性知识可以有效地辅助大脑执行各种任务。

隐性知识是指在潜意识状态下学到的知识。然而,对于隐性学习如何运作以及如何获得隐性知识,并没有系统的定义。在神经网络的一般定义中,从浅层获得的特征通常称为显性知识,从深层获得的特征称为隐性知识。在今天分享中,研究者将与观察直接对应的知识称为显性知识。对于模型中隐含的与观察无关的知识,称之为隐性知识。
3 新框架

研究者提出了一个统一的网络来整合隐性知识和显性知识,并使学习模型包含一个通用表示,而这个通用表示使子表示适用于各种任务。上图(c)说明了提出的统一网络架构。
接下来我们好好详细分析下隐性知识如何运作的?
本研究的主要目的是进行一个统一的网络,可以有效地训练隐性知识,所以在后续我们将首先关注如何训练隐性知识并对其进行快速推理。由于隐式表示zi与观察无关,我们可以将其视为一组常数张量Z={z1, z2, ..., zk}。接下来我们将介绍作为常数张量的隐性知识如何应用于各种任务。

· Manifold space reduction ·
研究者认为一个好的表示应该能够在它所属的流形空间中找到合适的投影,并促进后续客观任务的成功。例如,如下图所示,如果目标类别可以通过投影空间中的超平面成功分类,那将是最好的结果。在上面的例子中,我们可以通过投影向量和隐性表示的内积来达到降低流形空间维数,有效完成各种任务的目的。

· Kernel space alignment ·

在多任务和多head神经网络中,内核空间未对齐是一个常见问题,图上图(a)说明了多任务和多Head神经网络中内核空间未对齐的示例。
为了解决这个问题,研究者可以对输出特征和隐性表示进行加法和乘法,从而可以平移、旋转和缩放核空间以对齐神经网络的每个输出核空间,如下图(b)所示。

上述操作模式可以广泛应用于不同领域,例如特征金字塔网络(FPN)中大目标和小目标的特征对齐,使用知识蒸馏来整合大模型和小模型,以及处理零样本域转移和其他问题。
· More functions ·
除了可以应用于不同任务的功能外,隐性知识还可以扩展到更多的功能中。如下图所示,通过引入加法,可以使神经网络预测中心坐标的偏移。还可以引入乘法来自动搜索Anchor的超参数集,这是基于锚的目标检测器经常需要的。此外,可以分别使用点乘和串联来执行多任务特征选择并为后续计算设置前提条件。

在常规神经网络的训练过程中,通常会最小化以使fθ(x)尽可能接近目标。这意味着我们期望对同一目标的不同观察是fθ获得的子空间中的单个点,如下图(a)所示。换句话说,我们期望得到的解空间是仅对当前任务ti有区别,对各种潜在任务中的ti以外的任务不变,T \ ti,其中 T = {t1, t2, ..., tn}。

对于通用神经网络,我们希望得到的表征可以服务于属于T的所有任务。因此,我们需要放松,使得可以在流形空间上同时找到每个任务的解,如上图(b)所示。但是,上述要求使我们无法使用简单的数学方法,例如one-hot向量的最大值或欧几里得距离的阈值来获得ti的解。为了解决这个问题,我们必须对误差项进行建模,以找到不同任务的解决方案,如上图6所示。
4 实验及检测可视化



这个作者实验做的也特别充分,有兴趣的同学可以自己看下论文,从中发现一些创作灵感。我也是根据公布的源代码随便在公共数据集上测试下,效果与YoloV4比,精度可能差不多,速度确实快不少。今天就以鬼吹灯——云南虫谷这一小段检测片段,效果不是很好,因为我用的是公共数据集简单训练的效果,等有机会基于优化的网络好好训练一个模型。
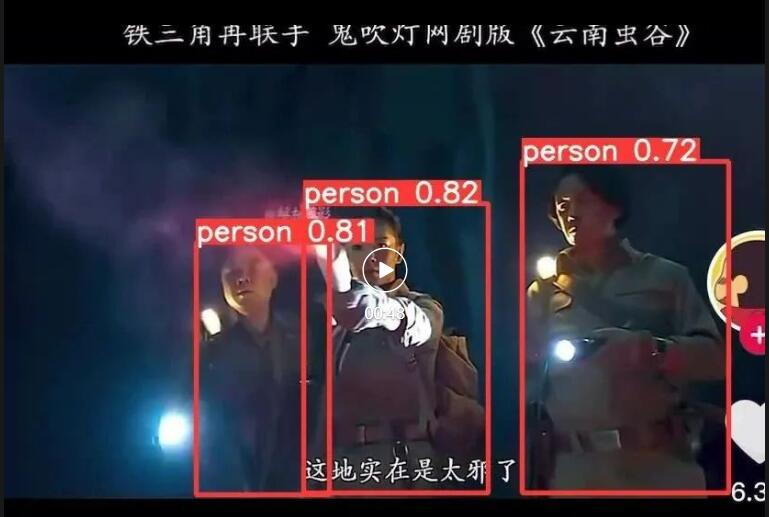
从抖音的检测过程中,可以看出效果一般般,还是要针对性的数据及高质量的训练,我为了显示基本的效果,就简单训练了一个轻量级网络,视频中可以看出“粽子”确实是“人“变的!