本文经计算机视觉研究院公众号授权转载,转载请联系出处。
01 简介
与最近关注large dense kernels的CNN不同,InternImage以可变形卷积为核心算子,使我们的模型不仅具有检测和分割等下游任务所需的大有效感受野,而且具有受输入和任务信息约束的自适应空间聚合。因此,所提出的InternImage减少了传统CNNs严格归纳偏差,并使其能够从像ViT这样的海量数据中学习具有大规模参数的更强、更稳健的模式。我们的模型的有效性在ImageNet、COCO和ADE20K等具有挑战性的基准测试中得到了验证。值得一提的是,InternImage-H在COCO测试开发上获得了创纪录的65.4mAP,在ADE20K上获得了62.9mIoU,优于目前领先的CNNs和ViTs。
02 背景
为了弥合CNNs和ViTs之间的差距,首先从两个方面总结了它们的差异:(1)从操作员层面来看,ViTs的多头自注意(MHSA)具有长程依赖性和自适应空间聚合(见图(a)段)。得益于灵活的MHSA,ViT可以从海量数据中学习到比CNN更强大、更健壮的表示。(2) 从架构的角度来看,除了MHSA之外,ViTs还包含一系列未包含在标准CNN中的高级组件,如层归一化(LN)、前馈网络(FFN)、GELU等。

尽管最近的工作已经做出了有意义的尝试,通过使用具有非常大内核(例如,31×31)的密集卷积将长程依赖引入到CNN中,如图(c)所示,在性能和模型规模方面与最先进的大型ViT仍有相当大的差距。
03 新框架介绍
通过大规模参数(即10亿)和训练数据(即4.27亿),InternImage-H的top-1准确率进一步提高到89.6%,接近well-engineering ViTs和混合ViTs。此外,在具有挑战性的下游基准COCO上,最佳模型InternImage-H以21.8亿个参数实现了最先进的65.4%的boxmAP,比SwinV2-G高2.3个点(65.4对63.1),参数减少了27%,如下图所示。

为了设计一个基于CNN的大型基础模型,我们从一个灵活的卷积变体开始,即DCNv2,并在此基础上进行一些调整,以更好地适应大型基础模型的要求。然后,通过将卷积算子与现代主干中使用的高级块设计相结合来构建基本块。最后,探索了基于DCN的块的堆叠和缩放原理,以构建一个可以从海量数据中学习强表示的大规模卷积模型。

使用DCNv3作为核心带来了一个新的问题:如何构建一个能够有效利用核算子的模型?首先介绍了基本块和模型的其他集成层的细节,然后我们通过探索这些基本块的定制堆叠策略,构建了一个新的基于CNN的基础模型,称为InternImage。最后,研究了所提出的模型的放大规则,以从增加参数中获得增益。
Basic block
与传CNNs中广泛使用的瓶颈不同,我们的基块的设计更接近ViTs,它配备了更先进的组件,包括LN、前馈网络(FFN)和GELU。这种设计被证明在各种视觉任务中是有效的。我们的基本块的细节如上图所示。其中核心算子是DCNv3,并且通过将输入特征x通过可分离卷积(3×3深度卷积,然后是线性投影)来预测采样偏移和调制尺度。对于其他组件,默认使用后规范化设置,并遵循与普通变压器相同的设计。

Hyper-parameters for models of different scales
Scaling rules
在上述约束条件下的最优原点模型的基础上,进一步探索了受[Efficientnet: Rethinking model scaling for convolutional neural networks]启发的参数缩放规则。具体而言,考虑两个缩放维度:深度D(即3L1+L3)和宽度C1,并使用α、β和复合因子φ缩放这两个维度。
通过实验发现,最佳缩放设置为α=1.09和β=1.36,然后在此基础上构建具有不同参数尺度的InternImage变体,即InternImage-T/S/B/L/XL,其复杂性与ConvNeXt的相似。为了进一步测试该能力,构建了一个具有10亿个参数的更大的InternImage-H,并且为了适应非常大的模型宽度,还将组维度C‘更改为32。上表总结了配置。
04 实验&可视化
Object detection and instance segmentation performance on COCO val2017.
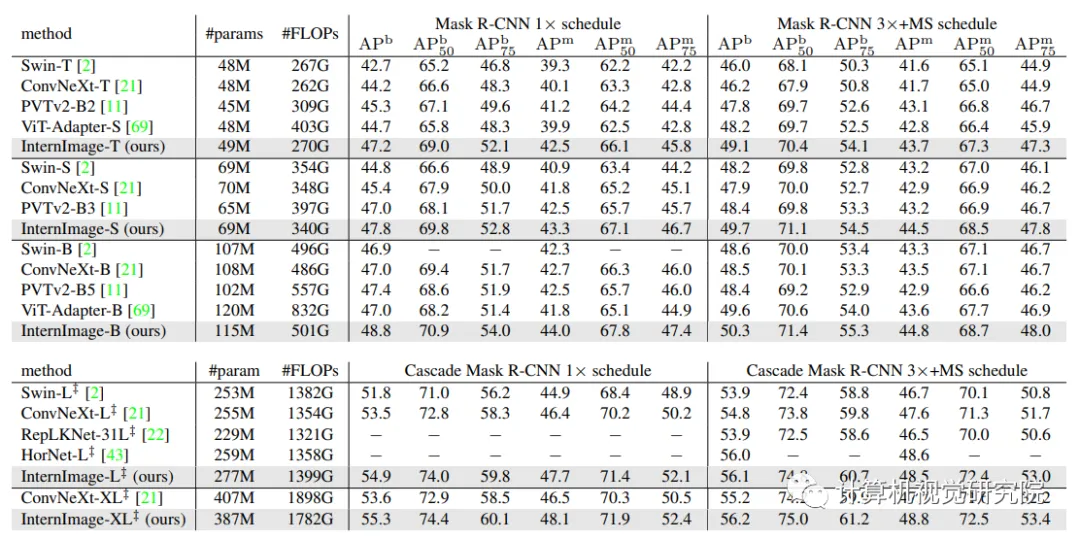
为了进一步提高目标检测的性能,在ImageNet-22K或大规模联合数据集上预先训练的权重初始化主干,并通过复合技术将其参数翻倍。然后,在Objects365和COCO数据集上一个接一个地对其进行微调,分别针对26个epochs和12个epochs。如下表所示,新方法在COCO val2017和test-dev上获得了65.0 APb和65.4 APb的最佳结果。与以前最先进的模型相比,比FD-SwinV2-G[26]高出1.2分(65.4比64.2),参数减少了27%,并且没有复杂的蒸馏过程,这表明了新模型在检测任务上的有效性。

共享权重的模型参数和GPU内存使用v.s卷积神经元之间的非共享权重。左纵轴表示模型参数,右纵轴表示批量大小为32且输入图像分辨率为224×224时每个图像的GPU内存使用情况。

不同阶段不同组的采样位置可视化。蓝色的星表示查询点(在左边的羊),不同颜色的点表示不同组的采样位置。