译者 | 朱先忠
审校 | 重楼
Zephyra传说
“在卢马里亚的神秘之地,古老的魔法弥漫在空气中。这里居住着以太狮鹫Zephyra。Zephyra拥有一个狮子的身体和一双鹰的翅膀,是掌握宇宙秘密的古老手稿《真理圣典》的受人尊敬的保护者。
《真理圣典》隐藏在一个神圣的洞穴中,由Zephyra所保护。Zephyra有一双淡绿色的眼睛,她可以看穿欺骗,揭示纯粹的真相。一天,一个黑暗的巫师降临在卢马里亚的土地上,试图通过隐藏圣典来掩盖世界的无知。村民们把在天空中翱翔的Zephyra视为希望的灯塔。Zephyra雄壮地挥动翅膀,在小树林周围建造了一道保护性的光屏障,击退了巫师,揭露了真相。
经过长时间的决斗,人们得出结论,黑暗巫师无法与Zephyra的光芒匹敌。通过她的勇气和警惕,真正的光芒一直照耀着卢马里亚。随着时间的推移,卢马里亚在Zephyra的保护下走向繁荣,Zephyra所捍卫的真理照亮了她的道路。这就是Zephyra的传奇故事的由来!”
Anthropic公司“提取可解释特征”之旅
在Zephyra的故事之后,美国加州旧金山的人工智能初创公司Anthropic AI深入研究了在模型中提取有意义特征的过程。这项研究背后的想法在于了解神经网络中的不同组件如何相互作用,以及每个组件扮演什么角色。
根据论文《Towards Monosemanticity: Decomposing Language Models With Dictionary Learning(走向单语义:用字典学习分解语言模型)》:https://transformer-circuits.pub/2023/monosemantic-features/index.html”,稀疏自动编码器能够成功地从模型中提取有意义的特征。换言之,稀疏自动编码器有助于解决“多义性”问题——通过专注于保持单一解释的稀疏激活特征,同时对应于多种解释的神经激活——换句话说,更多的是单向的。
为了充分理解稀疏自动编码器的运行机制,我们将借助于Tom Yeh教授提供的关于自动编码器(https://lnkd.in/g2rM9iV2)和稀疏自动编码器(https://www.linkedin.com/posts/tom-yeh_claude-autoencoder-aibyhand-activity-7199774212759183362-msKU/?)的漂亮图片,详细解释这些非凡机制的幕后工作原理。
首先,让我们先来探究一下什么是自动编码器以及它是如何工作的。
什么是自动编码器?
想象一下,一个作家的桌子上堆满了不同的纸张——有些是他正在写的故事的笔记,有些是定稿的副本,有些又是他充满动作的故事的插图。现在,在这种混乱中,很难找到重要的部分——尤其是当作家很匆忙,出版商在电话中要求两天内出版一本书时。值得庆幸的是,作者有一个非常高效的助手——这个助手确保杂乱的桌子定期清洁,将类似的物品分组,整理并放在正确的位置。在需要的时候,助手会为作者检索正确的文章,帮助他在出版商设定的截止日期前完成任务。
这个助手的名字叫自动编码器,它主要有两个功能——编码和解码。编码是指压缩输入数据并提取基本特征(组织);解码是从编码表示中重建原始数据的过程,同时旨在最大限度地减少信息丢失(检索)。
现在,让我们看看这个助手是如何工作的。
自动编码器是如何工作的?
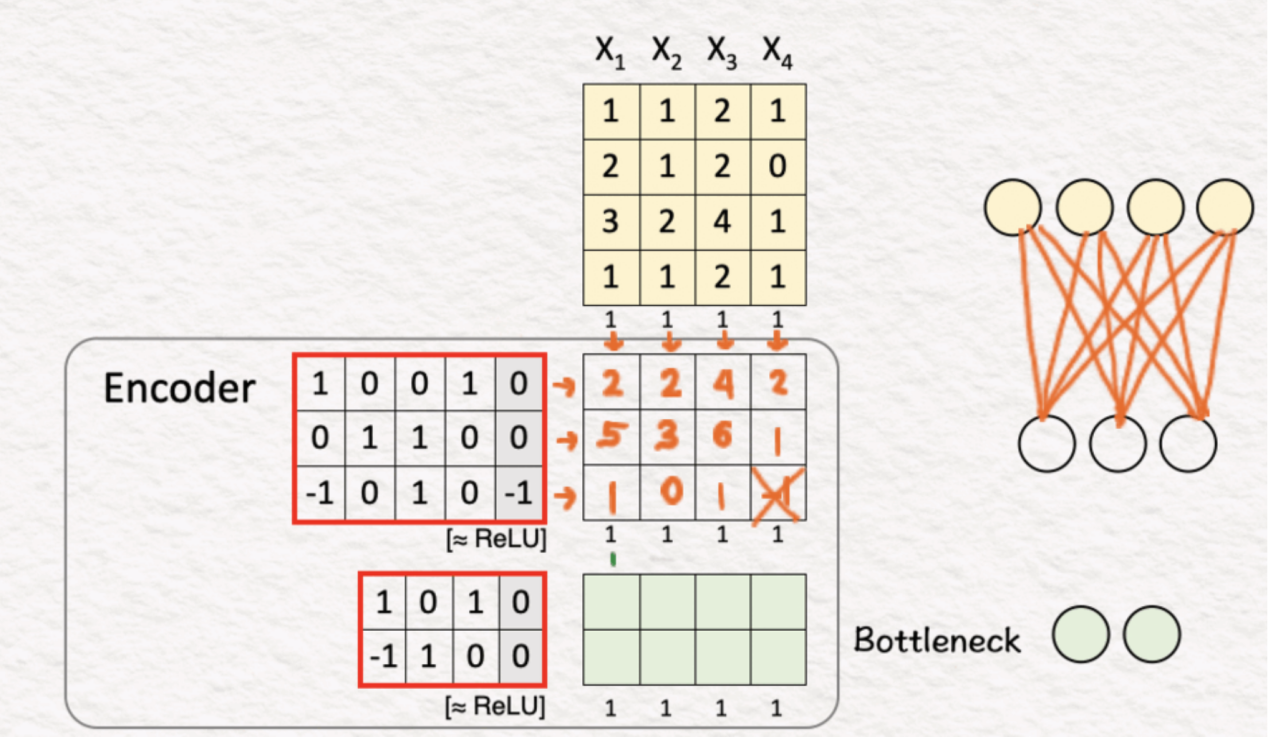
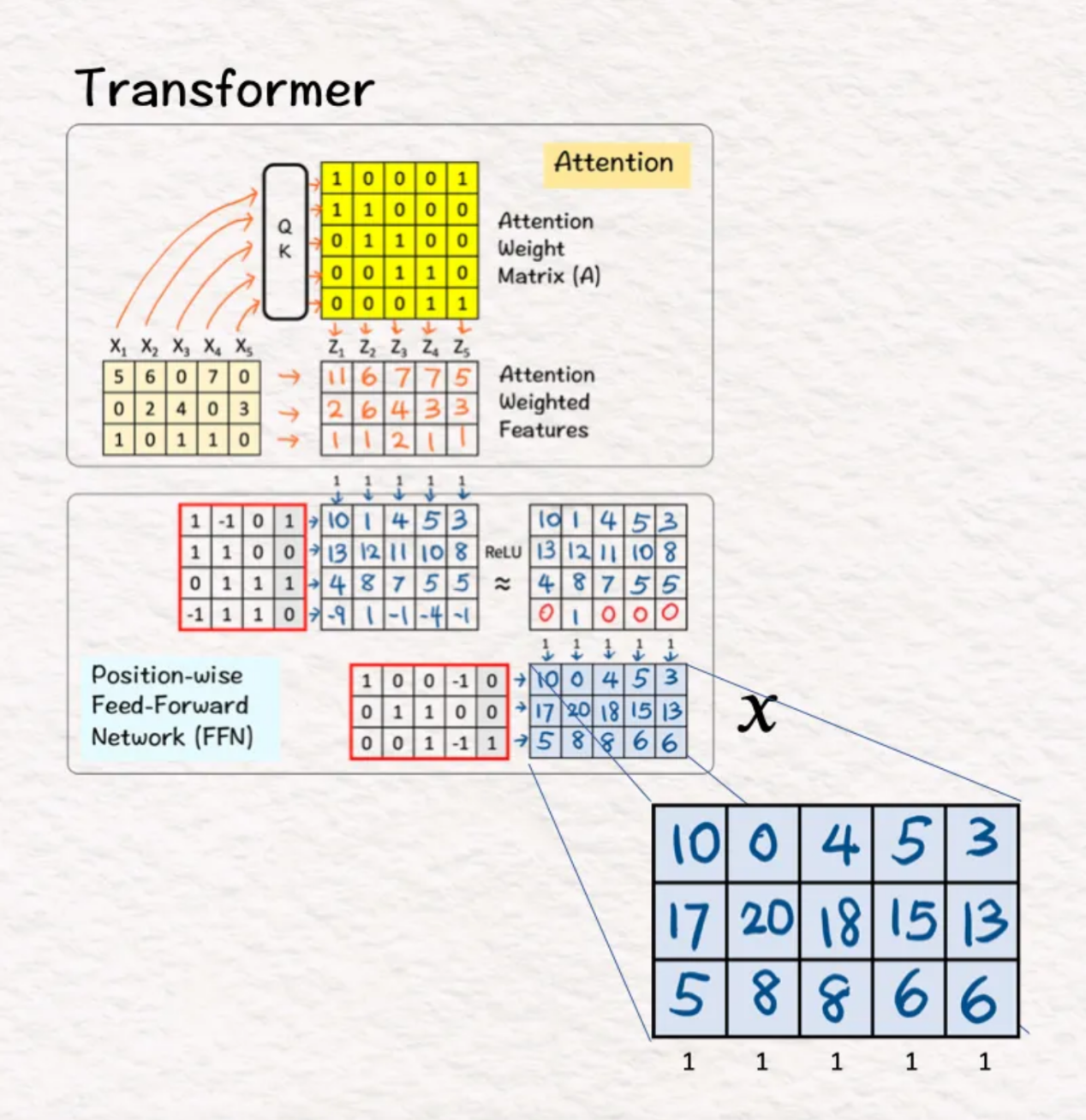
给定:四个训练样本X1、X2、X3、X4。
(1)自动(Auto)处理
第一步是将训练样本复制到目标Y'。Autoencoder的工作是重建这些训练样本。由于目标本身就是训练样本,因此使用了单词“Auto”,这在希腊语中是“self”的意思。
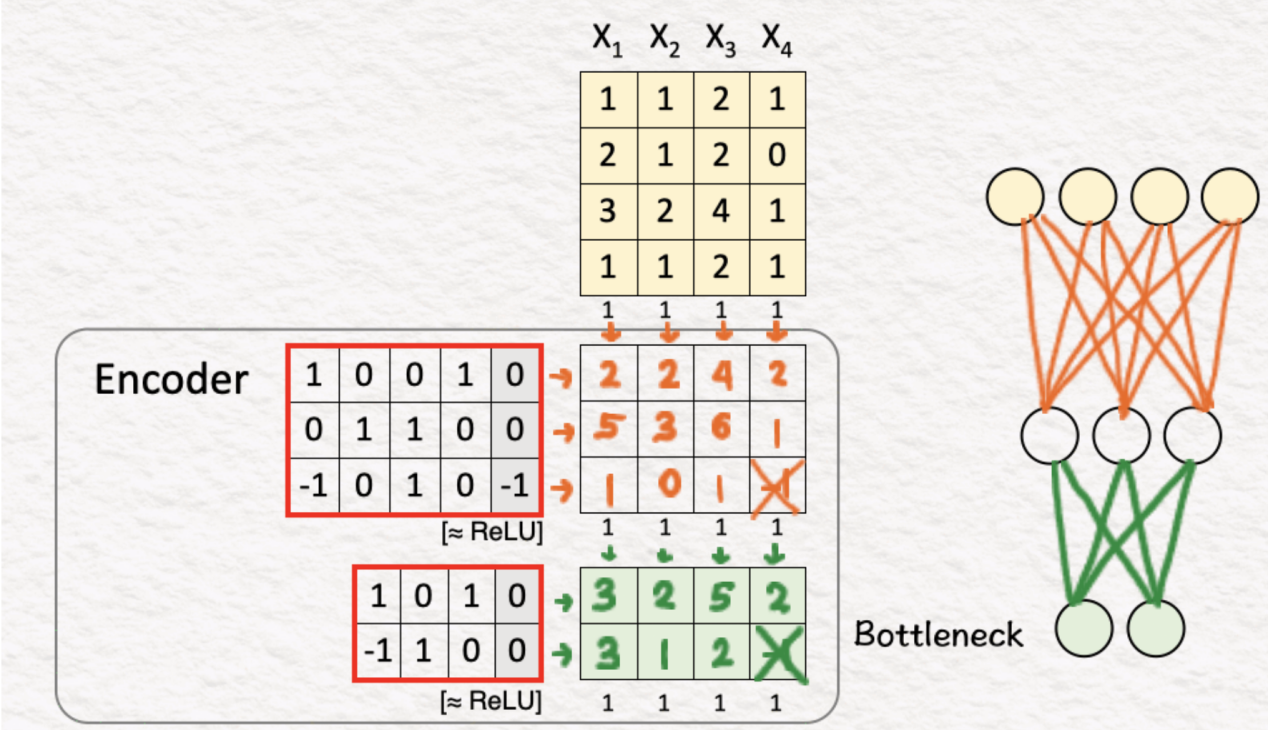
(2)编码器:第1层+ReLU
正如我们在之前的所有模型中所看到的,一个简单的权重和偏差矩阵与ReLU相结合后其功能是强大的,能够创造奇迹。因此,通过使用第一个编码层,我们将原始特征集的大小从4x4减小到3x4。
【简要回顾】
- 线性变换:将输入嵌入向量乘以权重矩阵W,再加上偏置向量b,
- z=Wx+b,其中W是权重矩阵,x是我们的单词嵌入,b是偏置向量。
- ReLU激活函数:接下来,我们将ReLU应用于这个中间z。
ReLU返回输入的元素最大值和零。从数学上讲,h=max{0,z}。
(3)编码器:第2层+ReLU
前一层的输出由第二编码器层处理,这将输入大小进一步减小到2x3。这就是提取相关特征的地方。这一层也被称为“瓶颈”,因为这一层中的输出特征比输入特征低得多。
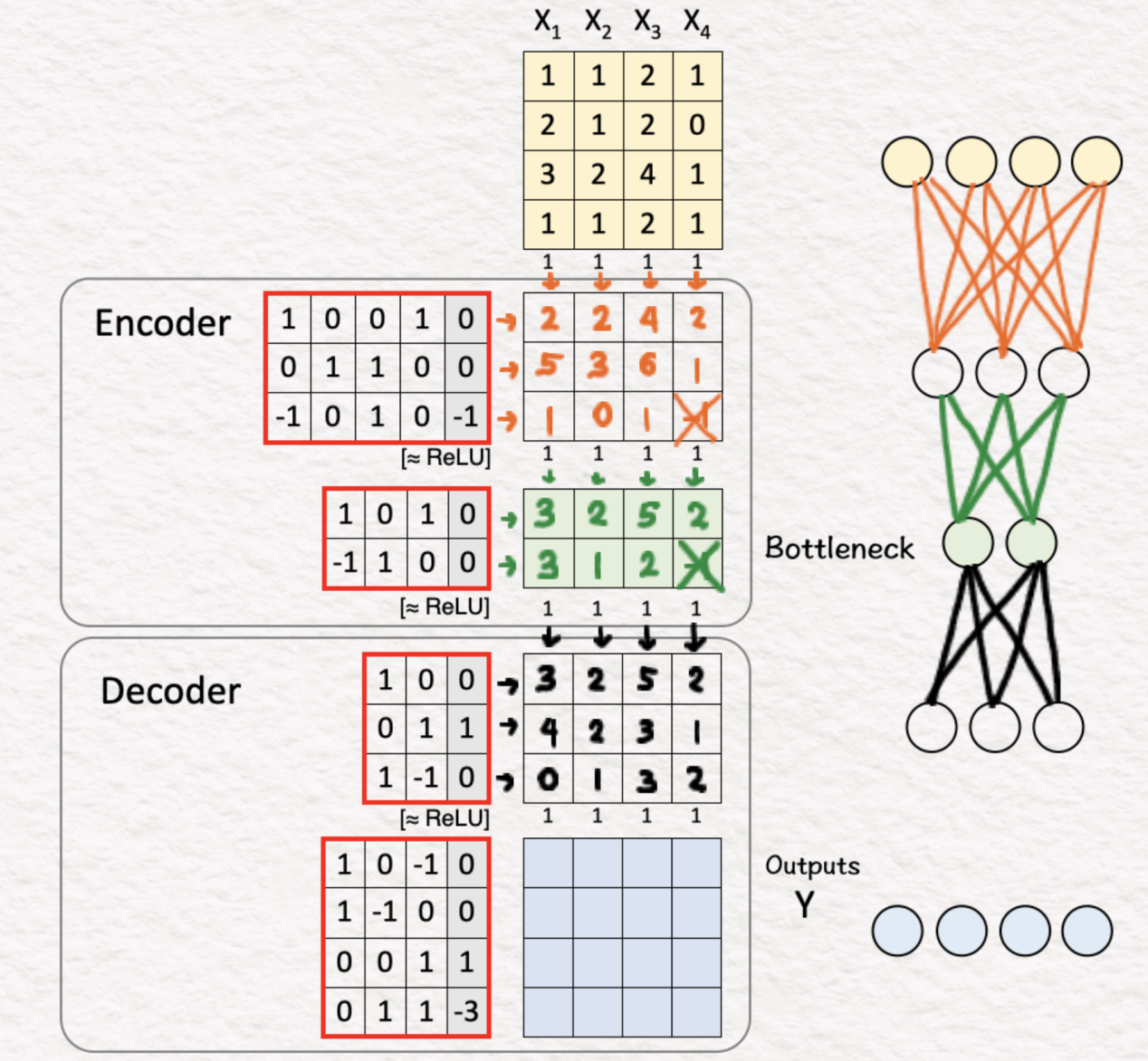
(4)解码器:第1层+ReLU
一旦编码过程完成,下一步是解码相关功能,以“返回”最终输出。为此,我们将上一步的特征与相应的权重和偏差相乘,并应用ReLU层。结果是一个3x4矩阵。
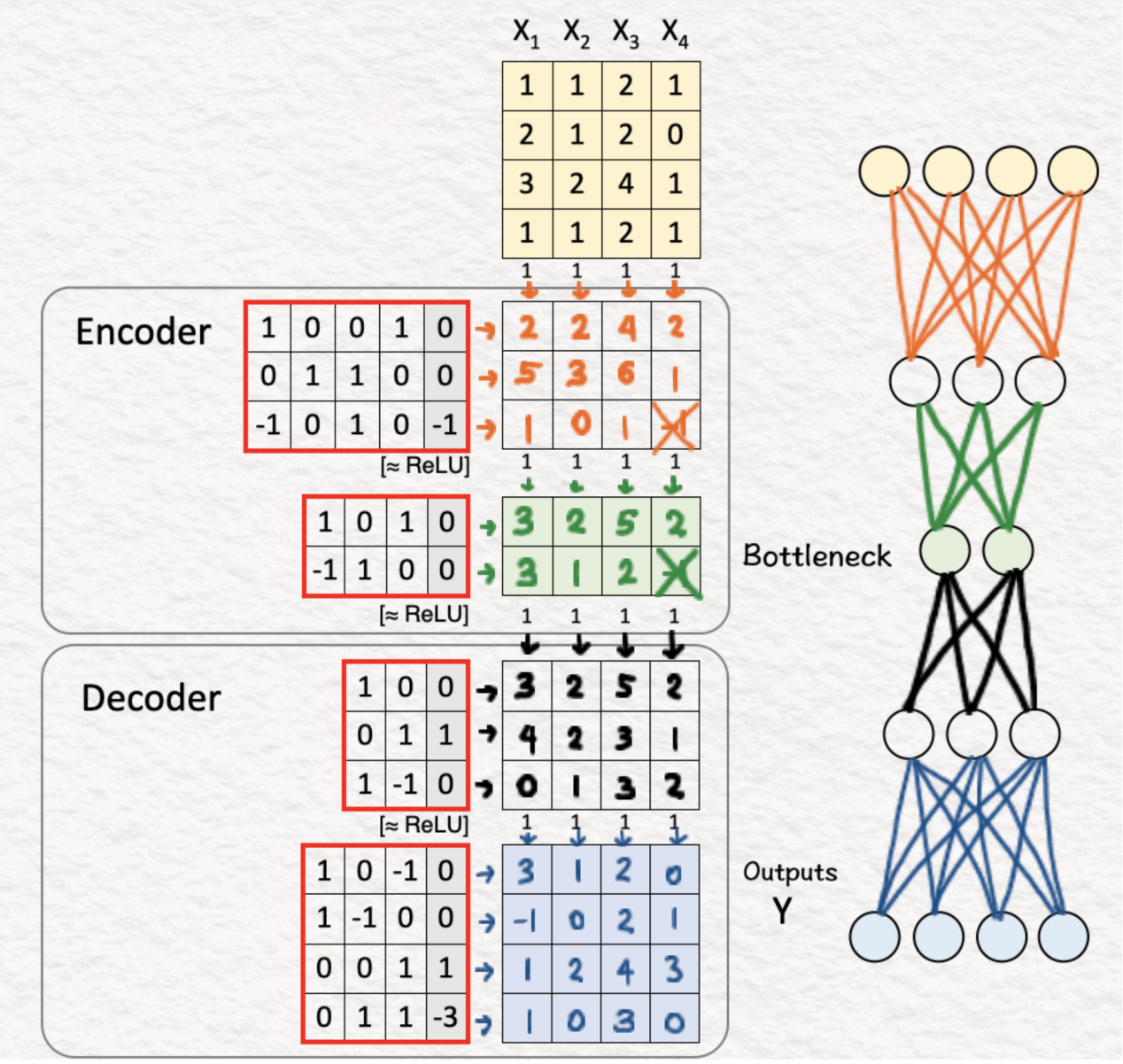
(5)解码器:第2层+ReLU
第二个解码器层(权重、偏置+ReLU)应用于先前的输出,以给出最终结果,即重建的4x4矩阵。我们这样做是为了回到原始维度,以便将结果与原始目标进行比较。
(6)损失梯度和反向传播
一旦获得来自解码器层的输出,我们就计算输出(Y)和目标(Y’)之间的均方误差(MSE)的梯度。为此,我们找到2*(Y-Y'),这给了我们激活反向传播过程的最终梯度,并相应地更新权重和偏差。
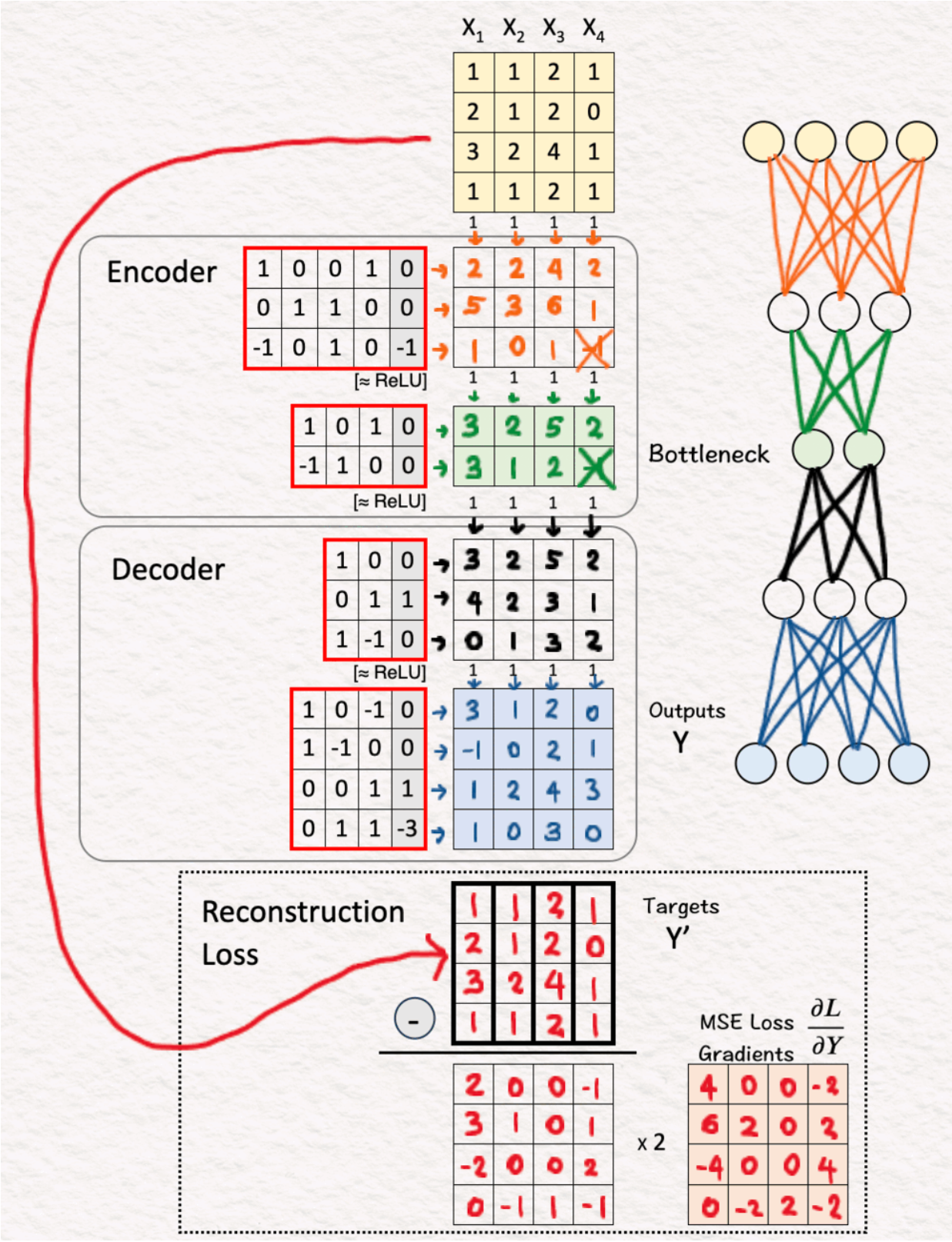
既然我们已经了解了自动编码器的工作原理,那么接下来,我们就可以开始探索其稀疏变体如何实现大型语言模型(LLM)的可解释性了。
稀疏自动编码器——它是如何工作的?
首先,假设我们得到:
- 前馈层处理之后转换器的输出结果,即,假设我们有五个特征(X)的模型激活。它们激活都很好,但并不能说明模型是如何做出决定或做出预测的。
这里的首要问题是:
是否有可能将每个激活(3D)映射到有助于理解的更高维度空间(6D)?
(1)编码器:线性层
编码器层的第一步是将输入X与编码器权重相乘,并添加偏差(如自动编码器的第一步中所做的)。
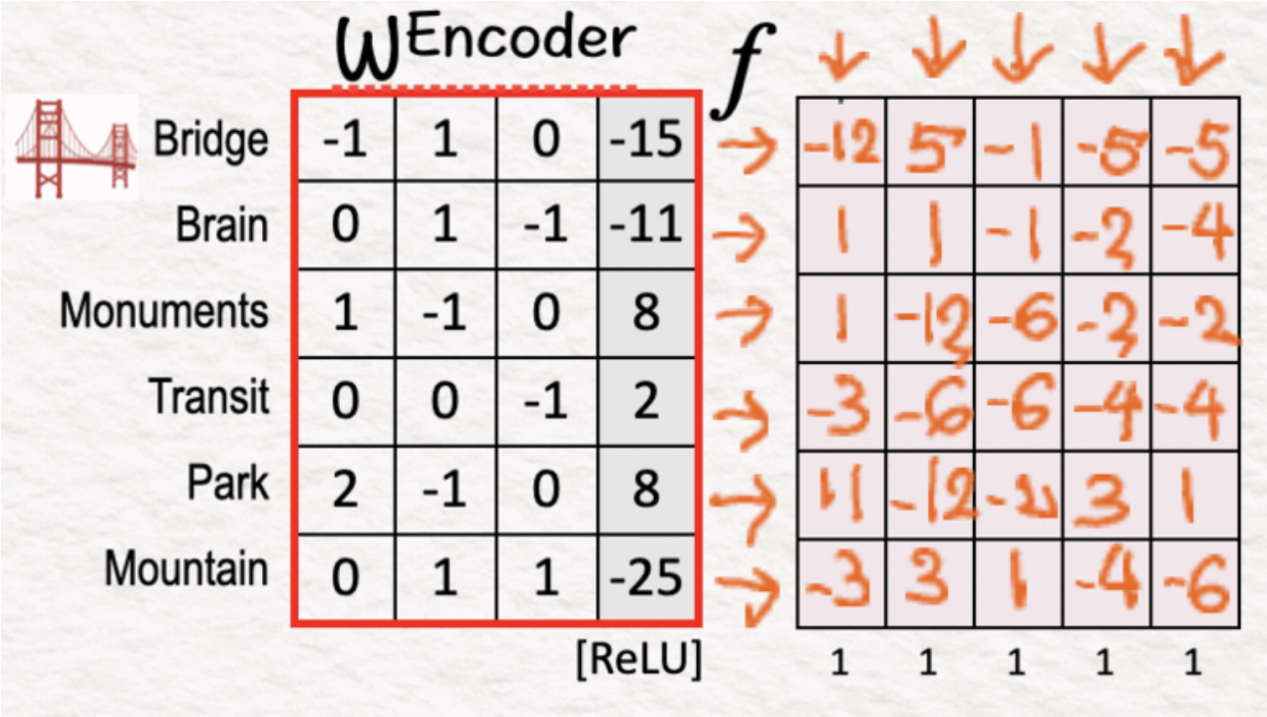
(2)编码器:ReLU
下一个子步骤是应用ReLU激活函数来添加非线性并抑制负激活。这种抑制导致许多特征被设置为0,这实现了稀疏性的概念——输出稀疏和可解释的特征f。
当我们只有一个或两个正的特征时,就产生了可解释性。如果我们检查f6,我们可以看到X2和X3是正的,可以说两者都有“峰”的共同点。
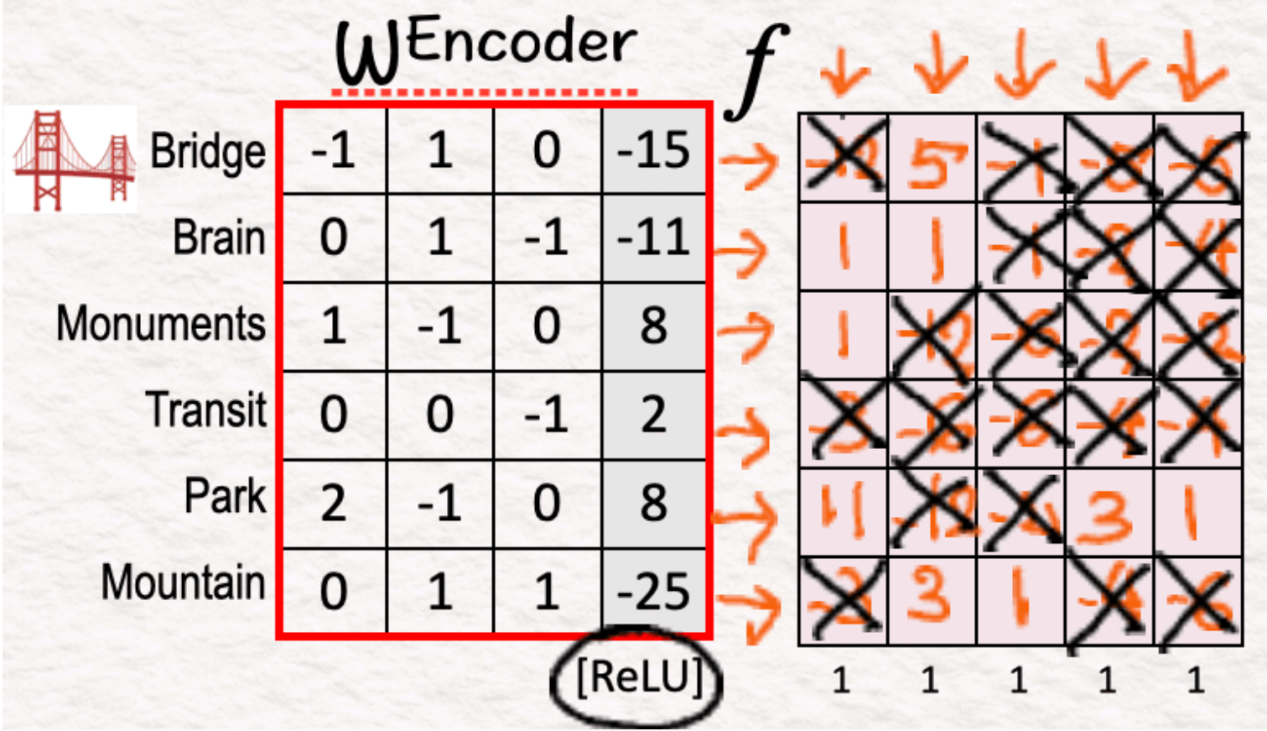
(3)解码器:重建
一旦我们完成了编码器,接下来就进入解码器阶段。在此,我们将f与解码器权重相乘,并添加偏差。这输出了X’,这是根据可解释特征对X的重构。
正如在自动编码器中所做的那样,我们希望X'尽可能接近X。为了确保这一点,进一步的训练至关重要。
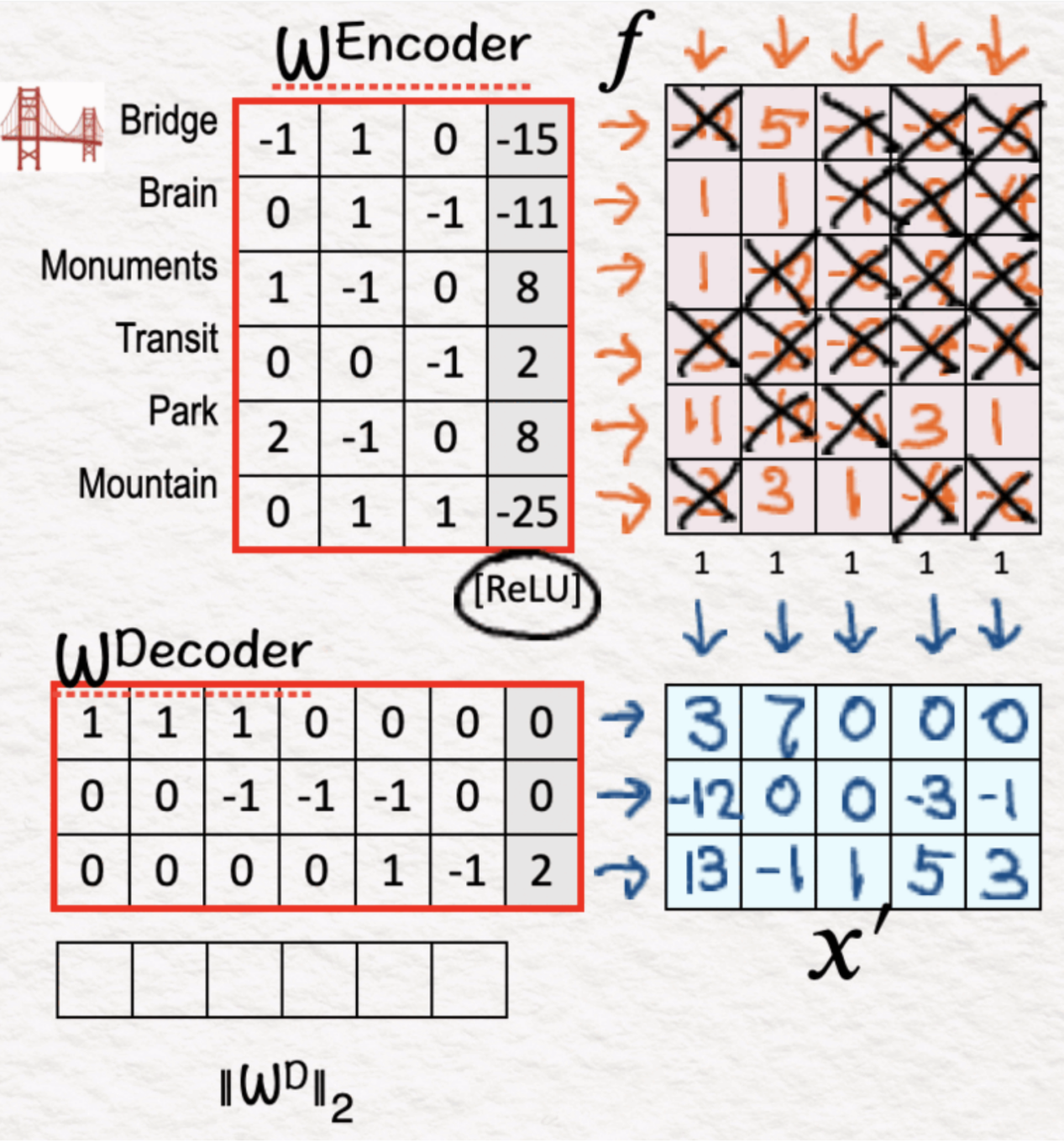
(4)解码器:权重
作为中间步骤,我们在该步骤中计算每个权重的L2范数。我们把它们放在一边待用。
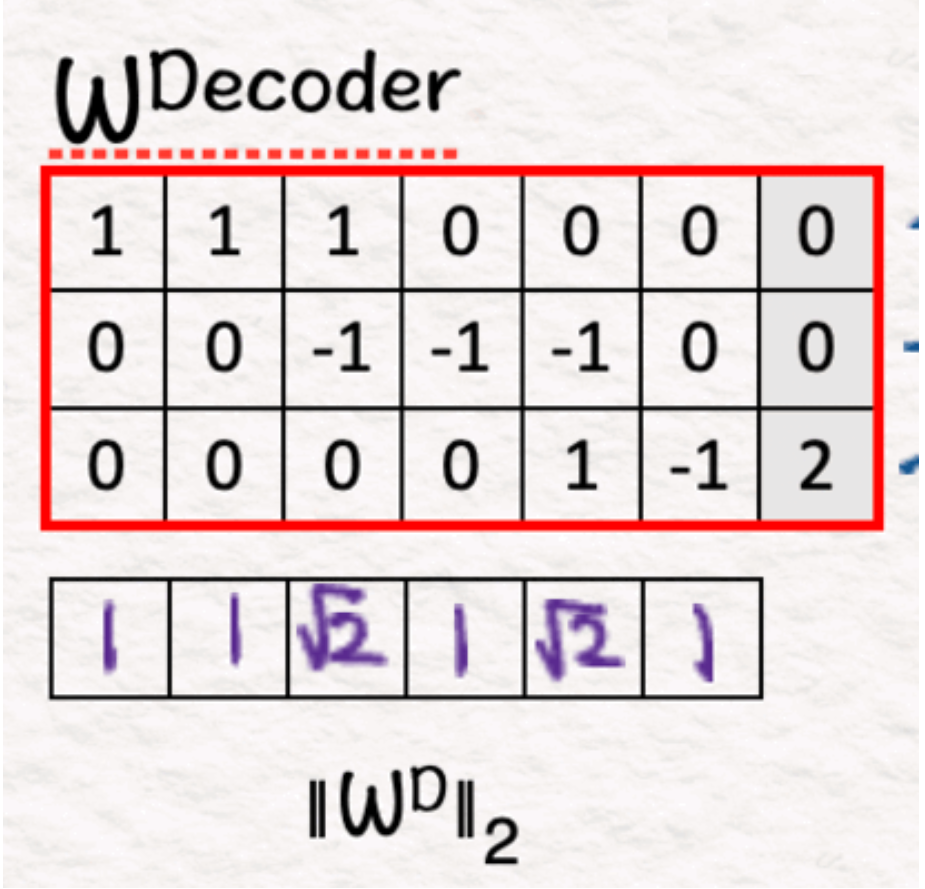
关于L2范数
L2范数也被称为欧几里得范数,它使用以下公式计算向量的大小:
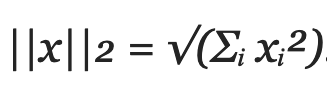
换句话说,它对每个分量的平方求和,然后取平方根作为结果。这个范数提供了一种直接的方法来量化欧几里得空间中向量的长度或距离。
训练
如前所述,稀疏自动编码器引入广泛的训练,以使重建的X’更接近X。为了说明这一点,我们继续进行以下步骤:
(5)稀疏性:L1损失
这里的目标是获得尽可能多的接近零/零的值。我们通过调用L1稀疏性来惩罚权重的绝对值来做到这一点——核心思想是我们希望使总和尽可能小。
关于L1损耗
L1损失计算为权重的绝对值之和:L1=λ∑|w|,其中λ是正则化参数。
这鼓励许多权重变为零,简化了模型,从而增强了可解释性。
换言之,L1有助于建立对最相关特征的关注,同时防止过拟合,提高模型泛化能力,并降低计算复杂度。
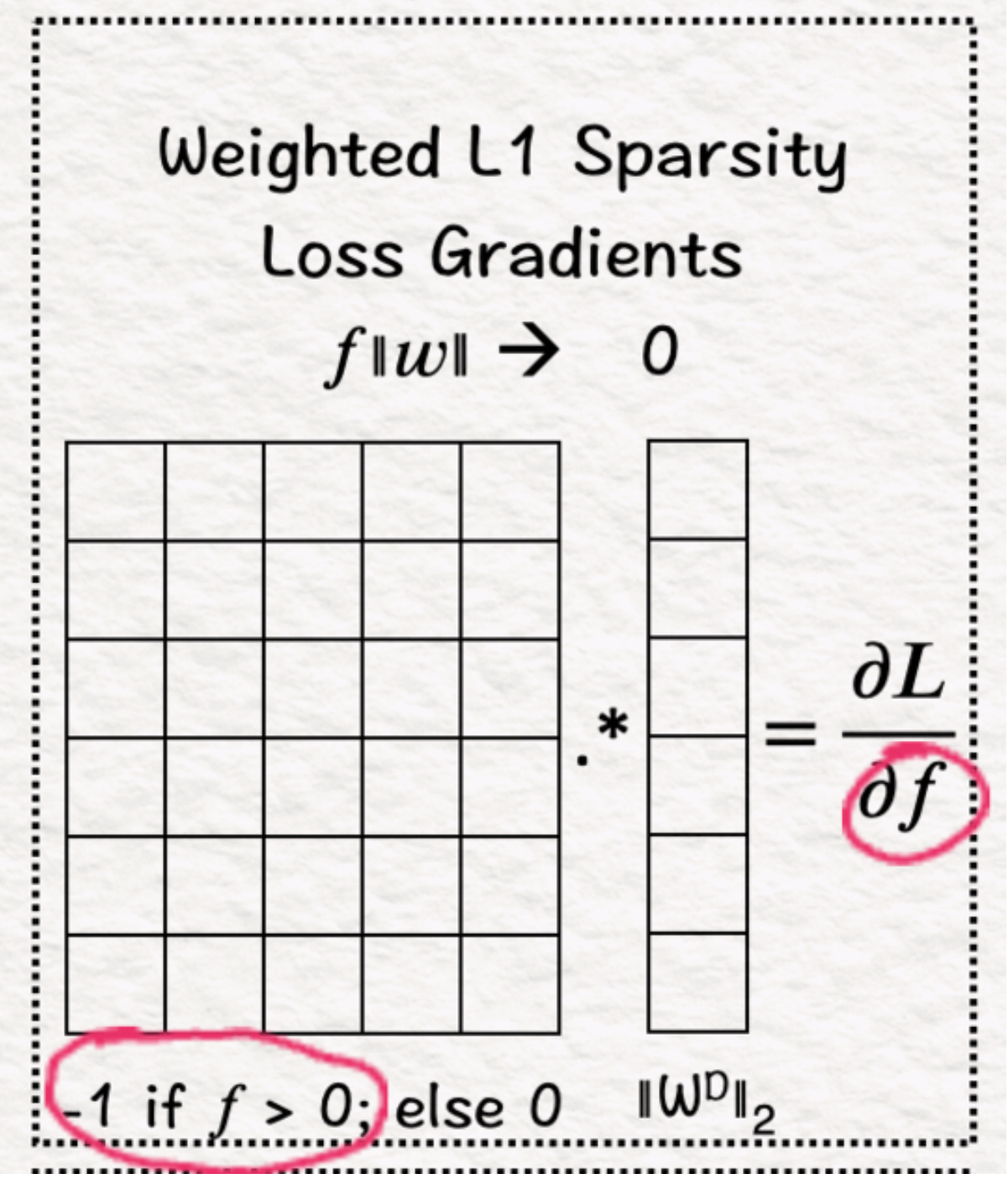
(6)稀疏度:渐变
下一步是计算L1的梯度,对于正值为-1。因此,对于f>0的所有值,结果将设置为-1。
L1惩罚是如何将权重推向零的?
L1惩罚的梯度通过施加恒定力的过程将权重推向零,而与权重的当前值无关。以下是它的工作原理(本小节中的所有图片均由作者提供):
L1惩罚表示为:
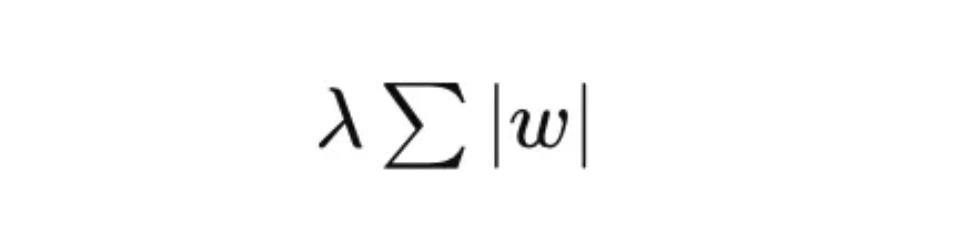
此惩罚相对于权重w的梯度为:
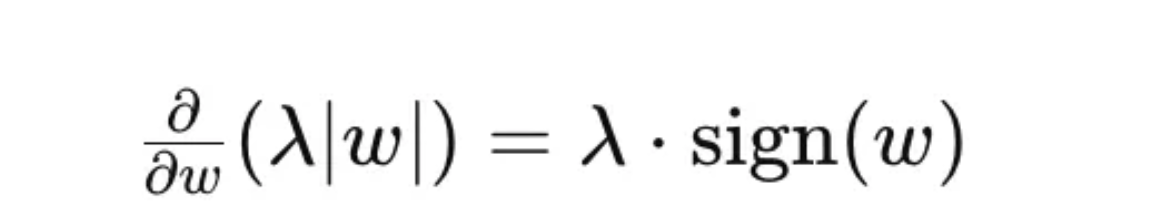
其中符号(w)为:
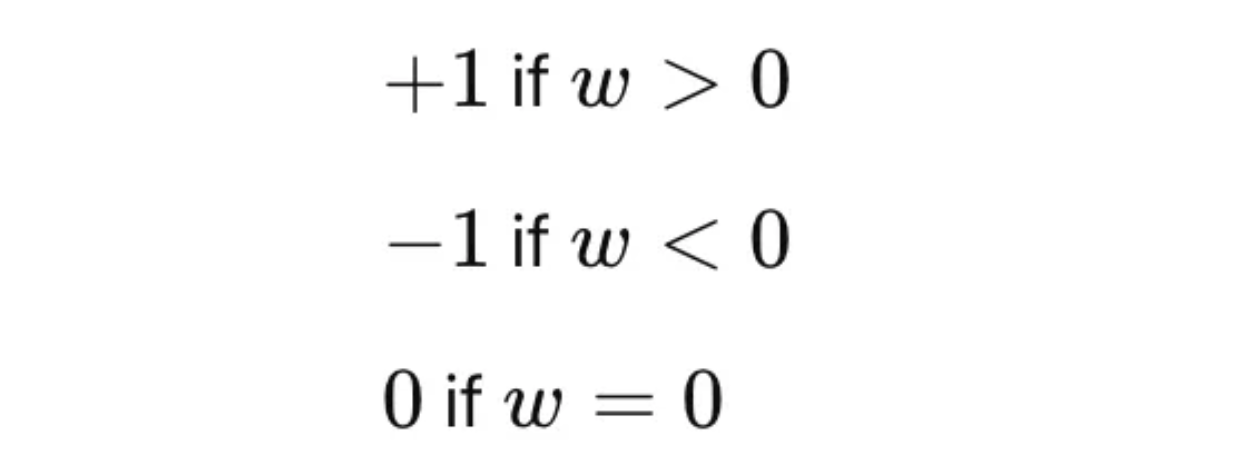
在梯度下降过程中,权重的更新规则为:

其中𝞰η代表学习率。
λ与权重值(取决于其符号)的常数相减(或相加)会降低权重的绝对值。如果重量足够小,这个过程可以将其精确地驱动到零。
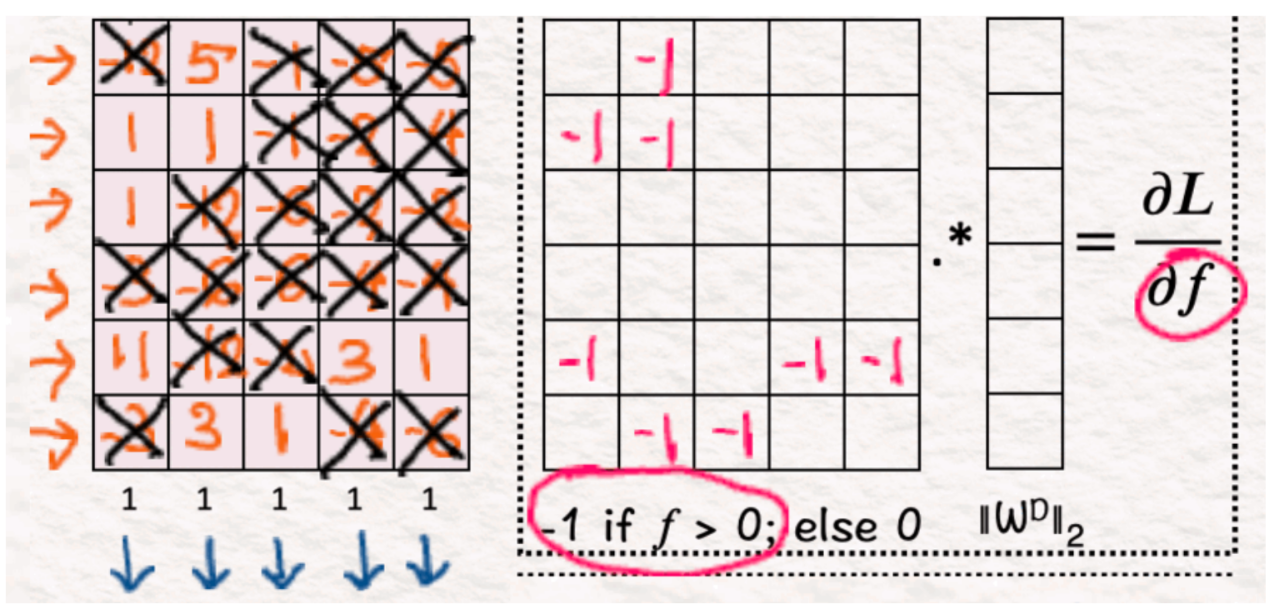
(7)稀疏度:零
对于所有其他已经为零的值,我们保持它们不变,因为它们已经被清零。
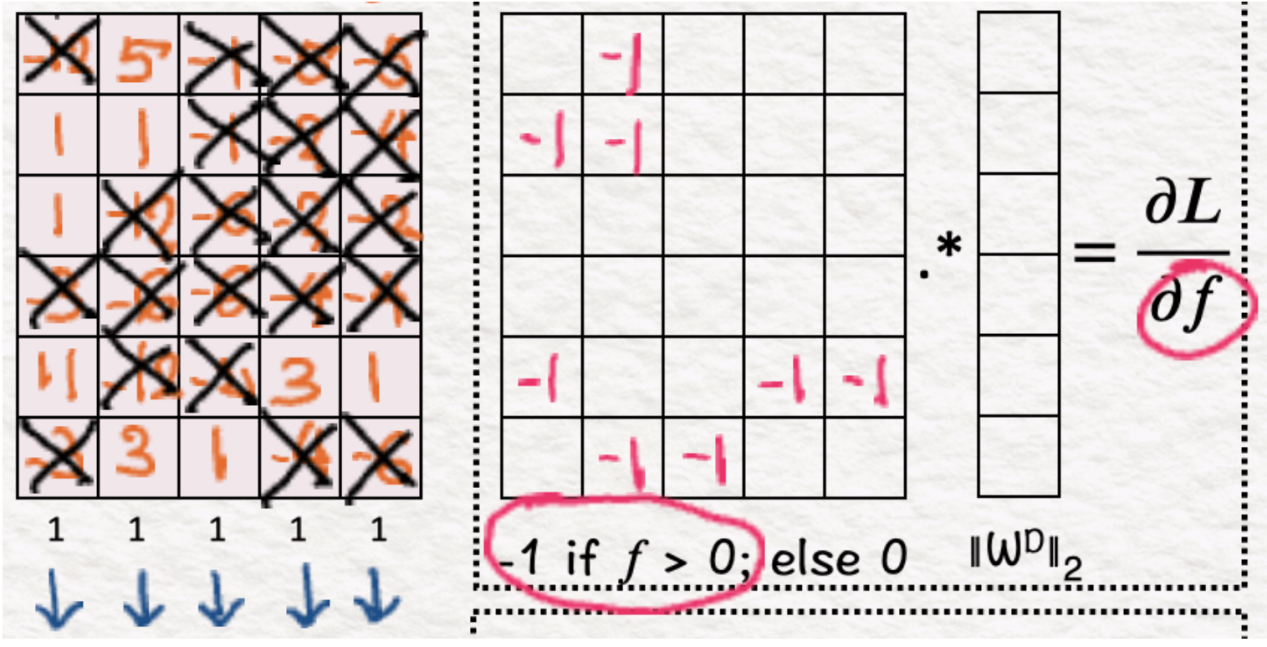
(8)稀疏度:权重
我们将步骤6中获得的梯度矩阵的每一行乘以步骤4中获得的相应解码器权重。这一步骤至关重要,因为它防止了模型学习大的权重,这会在重建结果时添加不正确的信息。
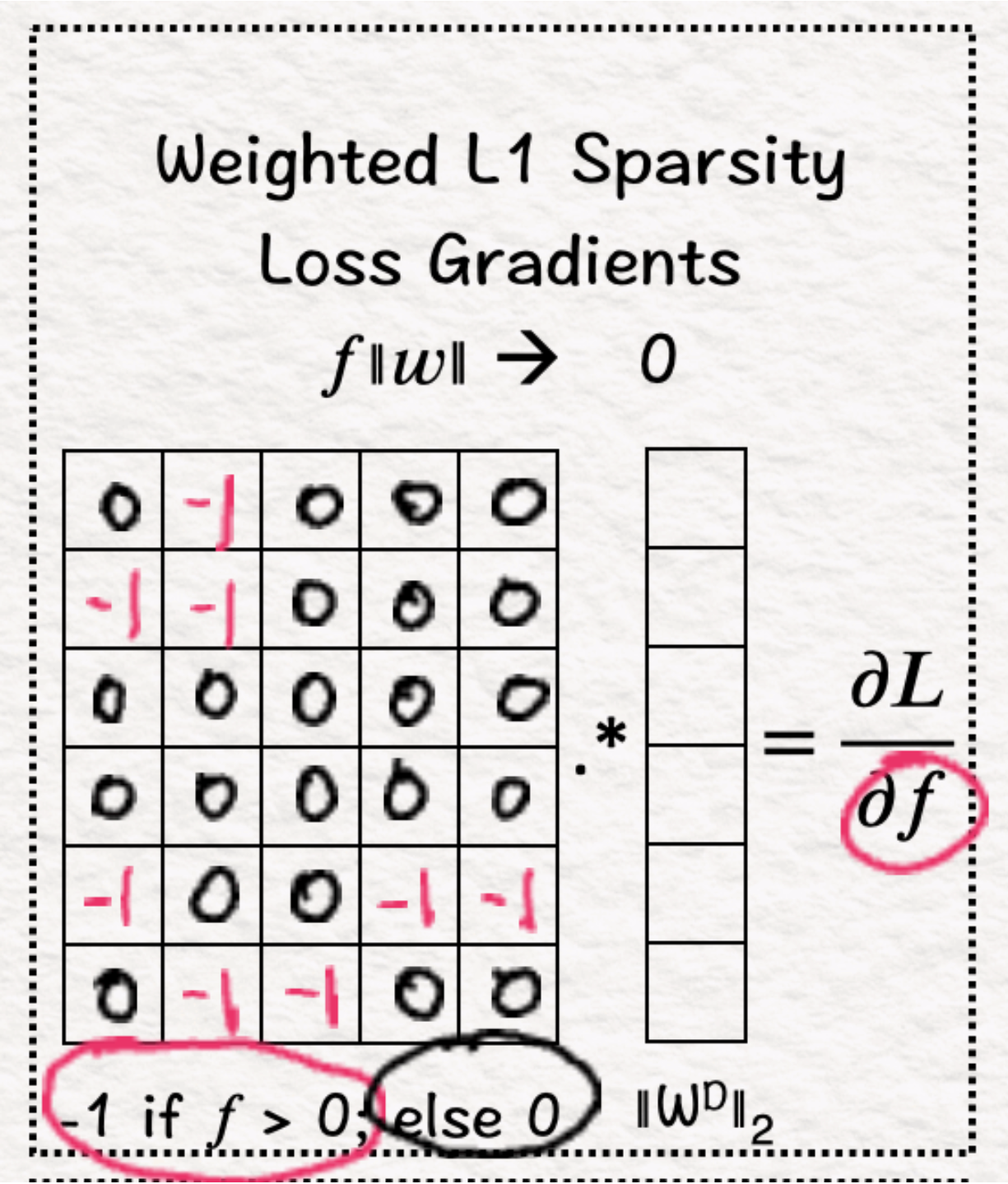
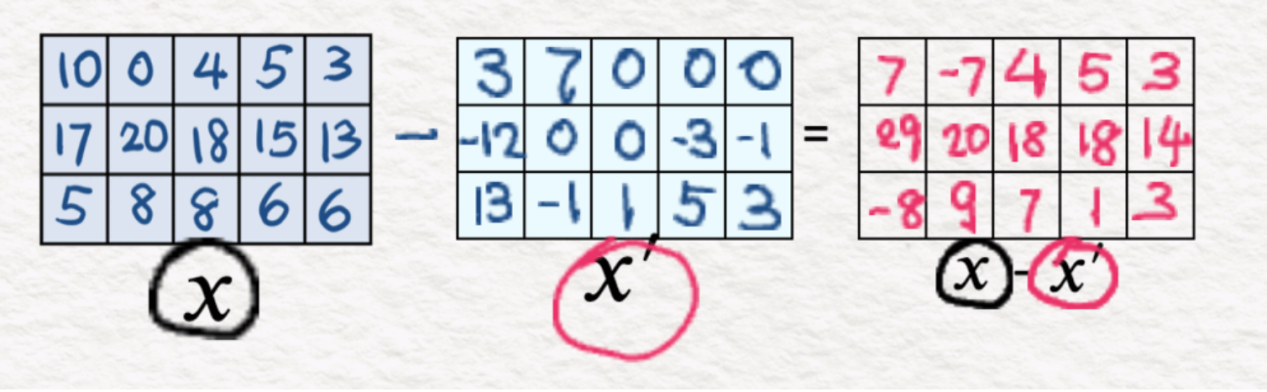
(9)重建:MSE损失
我们使用均方误差或L2损失函数来计算X’和X之间的差。如前所述,目标是将误差最小化到最低值。
(10)重建:渐变
L2损耗的梯度为2*(X'-X)。
因此,正如最初的自动编码器所看到的那样,我们运行反向传播来更新权重和偏差。这里的问题是在稀疏性和重建之间找到一个良好的平衡。
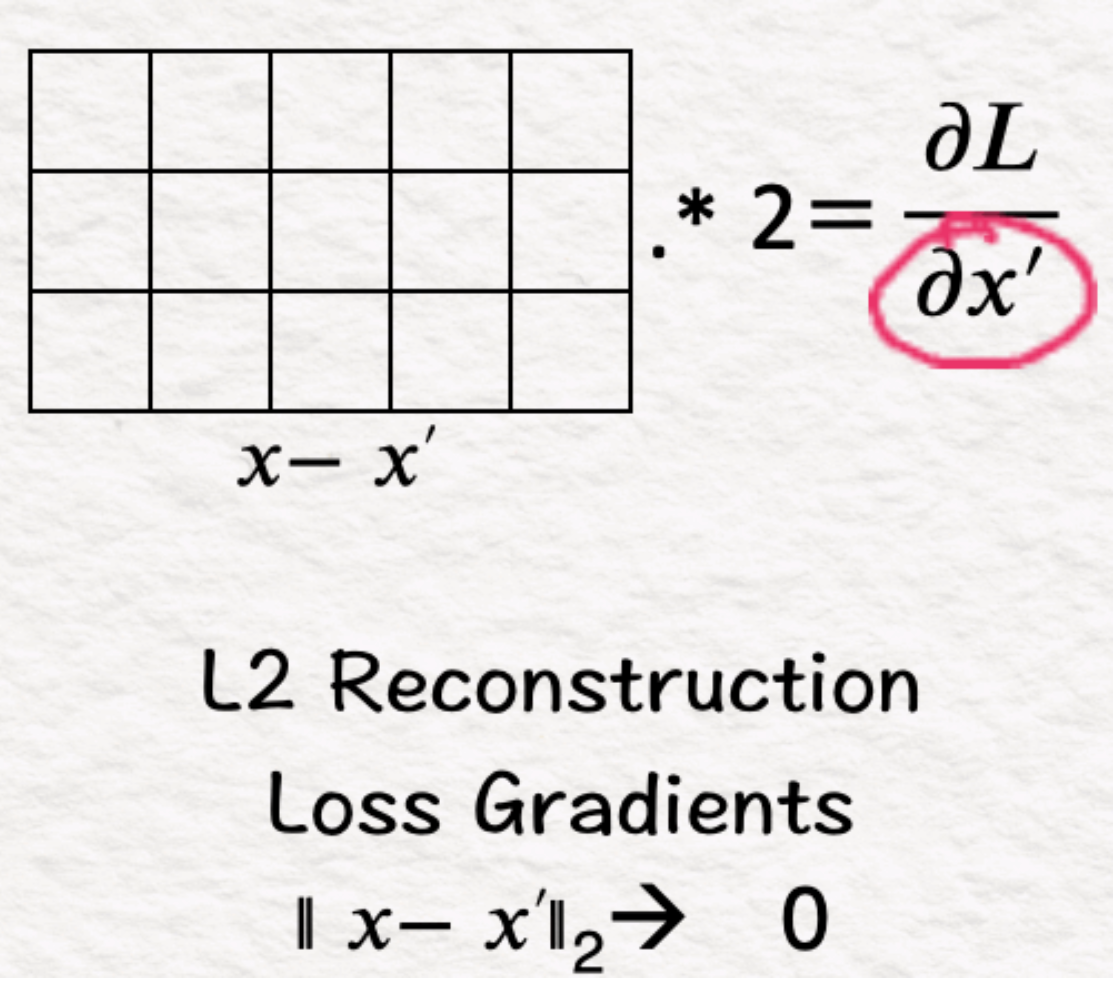
至此,我们就结束了对于稀疏自动编码器的讨论——我们以一种非常聪明和直观的方式学习了模型是如何理解一个想法以及作出针对性反应的。
小结一下
- 自动编码器总体上由两部分组成:编码器和解码器。编码器使用权重和偏差与ReLU激活函数相结合,将初始输入特征压缩到较低的维度,试图仅捕获相关部分。另一方面,解码器获取编码器的输出,并将输入特征重建回其原始状态。由于自动编码器中的目标本身就是初始特征,因此使用了“自动”一词。与标准神经网络一样,其目的是实现目标和输入特征之间的最低误差(差),这是通过在网络中传播误差梯度,同时更新权重和偏差来实现的。
- 稀疏自动编码器由标准自动编码器的所有组件以及一些附加组件组成。这里的关键是训练步骤中的不同方法。由于这里的目的是检索可解释的特征,我们希望将那些意义相对较小的值清零。一旦编码器使用ReLU激活来抑制负值,我们就更进一步,并对结果使用L1损耗,通过惩罚权重的绝对值来鼓励稀疏性。这是通过向损失函数添加惩罚项来实现的,其中的损失函数是权重的绝对值之和:λ∑|w|。保持非零的权重对模型性能是至关重要的。
利用稀疏度提取可解释特征
作为人类,我们的大脑对特定刺激的反应只是激活了一小部分神经元。同样,稀疏自动编码器通过利用L1正则化等稀疏性约束来学习输入的稀疏表示。通过这样做,稀疏自动编码器能够从复杂数据中提取可解释的特征,从而增强学习特征的简单性和可解释性。这种反映生物神经过程的选择性激活有助于关注输入数据的最相关方面,使模型更加稳健和高效。
随着Anthropic公司努力理解人工智能模型的可解释性,他们的倡议强调了对透明和可理解的人工智能系统的需求,尤其是当他们越来越融入关键决策过程时。通过专注于创建强大且可解释的模型,Anthropic公司为人工智能的发展做出了贡献,人工智能可以在现实世界的应用中得到信任和有效利用。
总之,稀疏自动编码器对于提取可解释特征、增强模型鲁棒性和确保效率至关重要。正在进行的关于理解这些强大模型及其推理方式的工作强调了人工智能中可解释性的日益重要,为更透明的人工智能系统铺平了道路。这些概念是如何演变的,以及如何推动我们走向一个需要人工智能在我们生活中安全集成的未来,还有待观察!
附言:如果你想自己完成这个练习,这里有一个空白模板的链接供你使用:
徒手练习空白模板:
https://drive.google.com/file/d/1xiAjdlWCAzhj-I-YOb7wSMeroUOQzdlE/view?usp=sharing。
至此,你可以去享受乐趣,帮助Zephyr保护真理圣典的安全了!
再次特别感谢Tom Yeh教授对这项工作的支持!
引用文献
[1] Towards Monosemanticity: Decomposing Language Models With Dictionary Learning, Bricken et al. Oct 2023 https://transformer-circuits.pub/2023/monosemantic-features/index.html
[2] Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet, Templeton et al. May 2024 https://transformer-circuits.pub/2024/scaling-monosemanticity/
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Explore the concepts behind the interpretability quest for LLMs,作者:Srijanie Dey, PhD
链接:
https://towardsdatascience.com/deep-dive-into-anthropics-sparse-autoencoders-by-hand-️-eebe0ef59709。