在电子商务、金融交易或其他高并发业务场景中,日均处理千万级别的订单是一个巨大的挑战。为了有效地存储、检索和管理这些订单数据,设计一个高效的存储架构至关重要。本文将探讨如何设计一个能够应对高并发写入和查询的存储架构,并提供C#示例代码来展示如何实现部分功能。
一、存储架构设计
- 数据库选择:
关系型数据库(如SQL Server、MySQL):适合结构化数据存储,提供事务支持和复杂的查询功能。
NoSQL数据库(如MongoDB、Cassandra):适合非结构化数据存储,扩展性好,适合大数据量和高并发的场景。
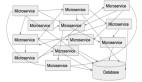
- 分库分表:
将数据分散到多个数据库或多个表中,以减轻单个数据库或表的压力。
使用哈希、范围或其他分片策略来分配数据。
- 读写分离:
使用主从复制或集群技术,将读操作和写操作分散到不同的数据库实例上。
写操作集中在主库,读操作可以从多个从库进行,以提高系统的吞吐量和响应速度。
- 缓存策略:
使用Redis等内存数据库作为缓存层,缓存热点数据和计算结果,减少对数据库的直接访问。
设置合理的缓存失效策略,以保持数据的一致性。
- 消息队列:
使用Kafka、RabbitMQ等消息队列技术来解耦订单处理流程,提高系统的可扩展性和容错性。
通过异步处理订单数据,减轻数据库的写入压力。
二、C#示例代码
以下是一个简单的C#示例,展示如何使用Entity Framework Core(一个流行的ORM框架)来操作数据库中的订单数据。
1. 定义订单模型
2. 定义数据库上下文
3. 订单数据访问服务
4. 使用依赖注入和订单服务
在ASP.NET Core应用中,你可以通过依赖注入来使用OrderService。
三、实践建议
- 性能测试:在实际部署前,对存储架构进行充分的性能测试,确保它能够承受预期的负载。
- 监控与告警:建立监控系统来跟踪数据库的性能指标,如响应时间、吞吐量等,并设置告警机制以便及时响应潜在问题。
- 数据备份与恢复:定期备份数据以防止数据丢失,并制定灾难恢复计划以确保业务的连续性。
- 持续优化:随着业务的发展和数据量的增长,持续监控和优化存储架构以保持其高效运行。
通过合理的架构设计和不断的优化调整,我们可以构建一个能够应对日均千万订单的高性能存储系统。