机器学习运维(MLOps)是一组用于自动化和简化机器学习(ML)工作流程和部署的实践。所选择的部署策略可以显著影响系统的性能和效用。所以需要根据用例和需求,采用不同的部署策略。在这篇文章中,我们将探讨三种常见的模型部署策略:批处理、实时和边缘计算。
批处理
批处理部署适合于不需要实时决策的场景,主要需要在指定的时间间隔处理大量数据。模型不是不断更新或对新数据作出反应,而是在一段时间内收集的一批数据上运行。该方法涉及在预定时间处理大块数据。常见的用例包括夜间风险评估、客户细分或预测性维护等。这种方法非常适合于实时洞察不重要的应用程序。
优点:
批处理可以安排在非高峰时间,优化计算资源和降低成本。与实时系统相比,更容易实现和管理,因为它不需要持续的数据摄取和即时响应能力。
能够处理大型数据集,使其成为数据仓库、报告和离线分析等应用程序的理想选择。
缺点:
数据收集和结果之间存在显著延迟,可能不适用于时间敏感的应用程序。
用例:
欺诈检测:通过分析历史数据来识别欺诈交易。
预测性维护:根据收集数据中观察到的模式来安排维护任务。
市场分析:分析历史销售数据,从中获得见解和趋势。
示例:
例如我们想要分析电子商务平台的客户评论的情绪。使用预训练的情感分析模型,并定期将其应用于一批评论。
import pandas as pd
from transformers import pipeline
# Load pre-trained sentiment analysis model
sentiment_pipeline = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
# Load customer reviews data
reviews_data = pd.read_csv("customer_reviews.csv")
# Perform sentiment analysis in batches
batch_size = 1000
for i in range(0, len(reviews_data), batch_size):
batch_reviews = reviews_data["review_text"][i:i+batch_size].tolist()
batch_sentiments = sentiment_pipeline(batch_reviews)
# Process and store batch results
for review, sentiment in zip(batch_reviews, batch_sentiments):
print(f"Review: {review}\nSentiment: {sentiment['label']}\n")我们从CSV文件中读取客户评论数据,并以1000条为一批处理这些评论。对于每个批次,我们使用情感分析流程来预测每个评论的情感(积极或消极),然后根据需要处理和存储结果。
实际的输出将取决于customer_reviews.csv文件的内容和预训练的情感分析模型的性能。
实时处理
实时部署在数据到达时立即对其进行处理,从而实现即时操作。这种方法对于需要实时数据处理和决策的应用程序是必不可少的。实时部署在处理数据并几乎即时提供输出时,适用于需要立即响应的应用程序,如欺诈检测、动态定价和实时个性化等。
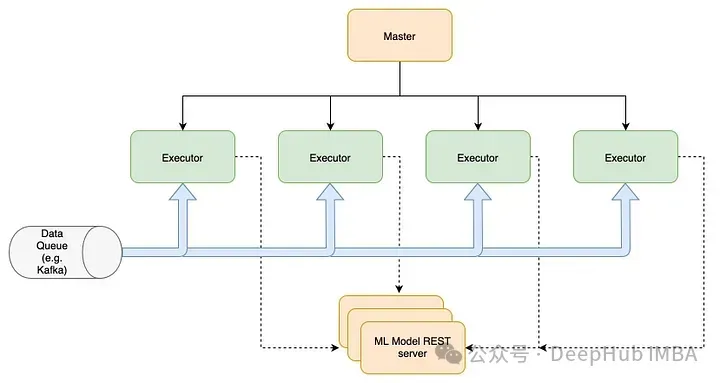
优点:
提供即时反馈,对时间敏感的应用程序至关重要,支持在毫秒到秒之间做出决策。提供动态和响应的交互,支持与最终用户直接交互的应用程序,提供无可感知延迟的响应,可以提高用户粘性。能够快速响应新出现的趋势或问题,提高运营效率和风险管理。
缺点:
需要强大且可扩展的基础设施来处理可能的高吞吐量和低延迟需求。并且确保运行时间和性能可能既具挑战性又成本高昂。
用例:
客户支持:聊天机器人和虚拟助手为用户查询提供即时响应。
金融交易:基于实时市场数据做出瞬间决策的算法交易系统。
智慧城市:利用实时数据进行实时交通管理和公共安全监控。
示例:
我们希望对金融交易执行实时欺诈检测,需要部署一个预先训练的欺诈检测模型,并将其公开为web服务。
import tensorflow as tf
from tensorflow.keras.models import load_model
import numpy as np
from flask import Flask, request, jsonify
# Load pre-trained fraud detection model
model = load_model("fraud_detection_model.h5")
# Create Flask app
app = Flask(__name__)
@app.route('/detect_fraud', methods=['POST'])
def detect_fraud():
data = request.get_json()
transaction_data = np.array(data['transaction_data'])
prediction = model.predict(transaction_data.reshape(1, -1))
is_fraud = bool(prediction[0][0])
return jsonify({'is_fraud': is_fraud})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8080)比如使用TensorFlow加载一个预训练的欺诈检测模型。然后我们创建一个Flask web应用程序,并定义一个endpoint /detect_fraud,它接受包含交易细节的JSON数据。对于每个传入请求,数据经过预处理等流程,输入模型并返回一个JSON响应,判断这条数据是否具有欺诈性。
为了增加服务的响应速度,一般情况下都是使用,使用Docker这样的容器化工具,并将容器部署到云平台或专用服务器上,并且可以进行自动化的资源调度和扩展。
边缘计算
边缘部署涉及在网络边缘的设备上运行机器学习模型,更接近数据生成的位置。这种方法在本地处理数据而不是将数据发送到集中式服务器来减少延迟和带宽使用。这种方法用于在将数据发送到中心服务器太慢或过于敏感的情况下,如自动驾驶汽车、智能摄像头等。
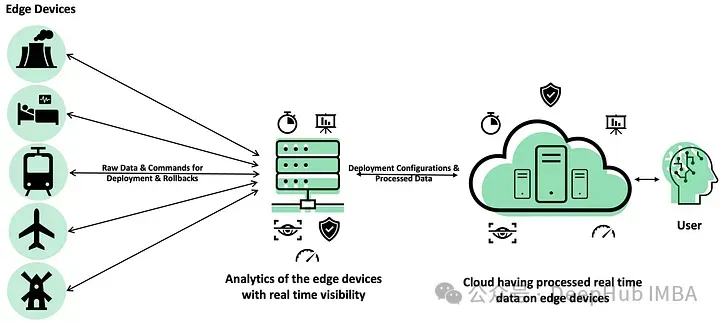
优点:
在本地处理数据,减少了向中心服务器回传数据的需要,节省了带宽,降低了成本。。通过在源附近处理数据来最大限度地减少延迟,非常适合需要快速响应时间的应用程序。
独立于网络连接运行,即使在远程或不稳定的环境中也能确保持续的功能。并且敏感数据在设备上存储,最小化暴露和合规风险。
缺点:
边缘设备的处理能力通常低于服务器环境,这可能限制了部署模型的复杂性。并且在众多边缘设备上部署和更新模型可能在技术上具有挑战性的,尤其是版本的管理。
用例:
工业物联网:对制造工厂的机械进行实时监控。
医疗保健:可穿戴设备分析健康指标并向用户提供即时反馈。
自动驾驶汽车:车载传感器数据处理,用于实时导航和决策。
我们以最简单的在移动设备上执行实时对象检测作为示例。使用TensorFlow Lite框架在Android设备上优化和部署预训练的对象检测模型。
import tflite_runtime.interpreter as tflite
import cv2
import numpy as np
# Load TensorFlow Lite model
interpreter = tflite.Interpreter(model_path="object_detection_model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Function to perform object detection on an image
def detect_objects(image):
# Preprocess input image
input_data = preprocess_image(image)
# Set input tensor
interpreter.set_tensor(input_details[0]['index'], input_data)
# Run inference
interpreter.invoke()
# Get output tensor
output_data = interpreter.get_tensor(output_details[0]['index'])
# Postprocess output and return detected objects
return postprocess_output(output_data)
# Main loop for capturing and processing camera frames
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if ret:
objects = detect_objects(frame)
# Draw bounding boxes and labels on the frame
for obj in objects:
cv2.rectangle(frame, (obj['bbox'][0], obj['bbox'][1]), (obj['bbox'][2], obj['bbox'][3]), (0, 255, 0), 2)
cv2.putText(frame, obj['class'], (obj['bbox'][0], obj['bbox'][1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (36, 255, 12), 2)
cv2.imshow('Object Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()以TensorFlow Lite格式加载一个预训练的对象检测模型,模型针对移动和嵌入式设备进行了优化。
在主循环中,不断地从设备的相机中捕获帧,将它们传递给detect_objects函数,并为检测到的对象在帧上绘制边界框和标签。处理后的帧然后显示在设备的屏幕上。边框将以绿色绘制,对象标签将显示在每个边框的左上角。
这些代码可以使用各自的TensorFlow Lite api和库集成到Android或iOS应用程序中。
选择正确的部署策略
选择正确的机器学习模型部署策略是确保高效性和成本效益的关键。以下是一些决定部署策略时需要考虑的主要因素:
1. 响应时间需求
- 实时部署:如果应用程序需要即时反馈,如在线推荐系统、欺诈检测或自动交易系统。
- 批处理部署:如果处理的任务可以容忍延迟,例如数据仓库的夜间批量处理、大规模报告生成。
2. 数据隐私和安全性
- 边缘部署:当数据隐私是一个重要因素,或者法规要求数据不得离开本地设备时,边缘部署是理想选择。
- 中心化部署:如果数据的隐私性较低或可以通过安全措施在云端处理,则可以选择中心化部署。
3. 可用资源和基础设施
- 资源有限的环境:边缘设备通常计算能力有限,适合运行简化或轻量级的模型。
- 资源丰富的环境:具有强大计算资源的云环境适合实时或大规模批处理部署。
4. 成本考虑
- 成本敏感:批处理可以减少对实时计算资源的需求,从而降低成本。
- 投资回报:实时系统虽然成本高,但可能因响应速度快而带来更高的投资回报。
5. 维护和可扩展性
- 简单维护:批处理系统相对容易维护,因为它们的工作负载是预测的。
- 需要高可扩展性:实时系统需要能够应对突发的高流量,需要更复杂的管理和自动扩展能力。
6. 用户体验
- 直接与用户交互:需要即时响应来提升用户体验的应用,如移动应用中的个性化功能,更适合实时部罗。
- 后台处理:用户不直接感受到处理延迟的场景,如数据分析和报告,批处理更为合适。
结合上述因素,你可以根据具体的应用场景和业务需求来选择最适合的部署策略。这有助于优化性能,控制成本,并提高整体效率。
总结
了解批处理、实时和边缘部署策略的区别和应用程序是优化MLOps的基础。每种方法都提供了针对特定用例量身定制的独特优势,通过评估应用程序的需求和约束,可以选择最符合目标的部署策略,为成功的AI集成和利用铺平道路。