












出品 | 51CTO技术栈(微信号:blog51cto)
短视频赛道的战火已经彻底卷起来了,今天,一款让全球网友兴奋到刷屏的视频生成器上线了!
Dream Machine,这款可以根据文本和图像生成AI视频的工具向公众开放,免费,免费,免费!关键还在于,跟传说中的Sora技术路线大不相同,2分钟内就能生成!
话不多说,在解读技术之前,先看效果(什么才是真正的饕餮盛宴)!
1.大片预告—Justin
有人抢先体验了DreamMachine的人甚至生成了非常震撼预告片,战争、歌唱家、魔法师、骑士、海盗船长、骑手被处理的浑然天成。
这位体验者Justin赞叹道:你以为LumaLabsAI只是关于酷炫的3D物体。错了!事实证明,数千个高斯条纹可以轻松变成强大的视频生成模型。

2.新世纪渴望——Kaku Drop
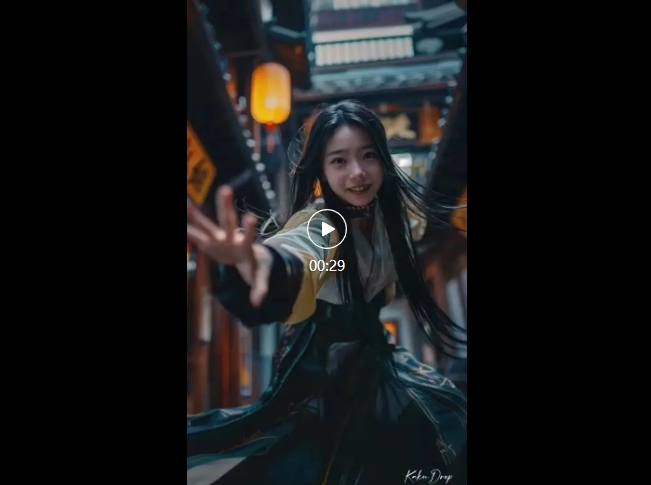
“一个新世代已经开始。我们在科技浪潮中重生并发展。我们展望未来,不耽念过去,并不断向前。”不同衣着风格的女生四处透露出福音战士的日系动画风格,面容却出奇得保持一致,场景构思十分前瞻新奇。网友惊呼:创作的进入门槛正在被彻底打破!
3. U WREE MINE —Next on Now

这里就不得不惊叹Luma最新模型太厉害了!电视机屏幕里的画面一致性做得非常棒,而且镜头拉伸、角度的变换、人物动作的处理几乎处理得堪称完美。
4.奇幻生物—Curious Reuge

再体验之后,创作者Curious大吃一惊,这个视频主要是通过图像转视频的功能声生成的。海底的白鲸、雨林的变色龙、非洲草原上猎豹……似乎到了这里全都披上了一层梦幻的笼纱,让人误以为进入到了堪比“猛兽侠”的火种时代。
以上更多是图生视频,文生视频的能力如何?
小编也第一时间进行了测试。

提示词:小米汽车,行驶在跨江大桥上。

提示词:牛顿坐在苹果树下,一颗红苹果砸到了他的头。

提示词:Newton was sitting under an apple tree when a red apple hit him on the head.
小编看到牛顿竟然会被苹果这样“砸”,实在是怀疑自己的提示词出了问题,哭笑不得,这一颗接一颗的苹果掉下来,即便没有砸到头,砸到手,不也得砸出事情来!
一、怎么做到的?
根据图像生成的短片为什么这么逼真?
相信大家都知道《珍珠耳环的少女》这幅画作,Dream Machine可以做到分钟内生成3D版并按照提示生成相应的动作和镜头切换,大家可以看下面的视频,非常惊艳。
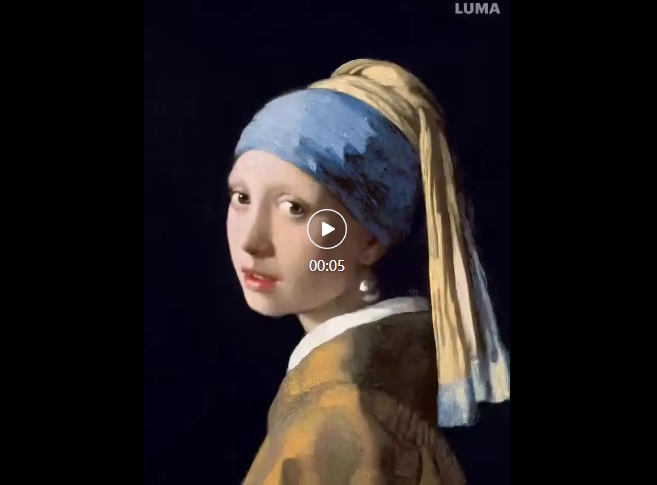
对比之前的鬼畜gif,是不是瞬间高大上了起来,相信之后的动态表情包有了更加无敌的生成器了!
想到这里,小编果断想到能不能让齐白石老先生的“虾”活过来!效果非常丝滑,镜头感也是拉满了,虾腿游弋的动作清晰可见!

二、不同于Sora的技术:三维重建术
小编从技术交流群中了解到,一位技术专家跟Luma的技术团队做了交流,Dream Machine的实现原理跟类Sora技术并不相同,很多工作都是从一项名叫NeRF的技术做的,即:先根据提示词生成3D场景,然后在渲染。
所以对于3D场景,效果就会不错,而对于较难3D重建的场景,比如“吃面”,效果就不一定好。
 图片
图片
NeRF技术,全称Neural Radiance Fields,即神经辐射场,是一种使用神经网络来隐式表达3D场景的技术,是Luma AI构建3D内容的核心。这一套最初由UC Berkeley和Google发布的深度学习系统,可以基于少量的2D图像,对3D场景的几何形状和外观进行建模。
这项技术应用非常广泛,包括但不限于3D建模、自动驾驶、导航系统等领域。
除此之外,Luma AI增长负责人Barkley Dai还表示,基于NeRF和Gaussian Splatting 3D重建技术,Luma AI可以基于2D图像数据快速构建高质量3D数据,用于机器学习和算法训练。
减少生成高质量3D内容所需的算力资源和时间,则是AI 3D生成技术落地的关键。自今年以来,Text to 3D所耗时长已经从小时级,缩减到了分钟级。
值得注意的是,去年11月,Luma AI在Discord上发布了了Text to 3D工具Genie,则将Text to 3D所耗时长缩减到秒级。基于大量3D形状、结构和场景数据进行深度神经网络训练,Genie建立了对语义和3D空间几何对应关系的理解能力。
三、Luma核心团队
成立于2021年,Luma AI是美国加州旧金山湾区的初创企业,该公司聚焦于3D内容生成技术,提供3D内容生成和3D内容重建技术解决方案。
Luma AI的核心团队,拥有海外头部大厂和高校的履历。创始人兼CEO Amit Jain出身苹果 AR/VR 部门,在3D计算机视觉、深度技术产品等方面有丰富经验。
 图片
图片
创始人兼CTO Alex Yu毕业于UC Berkeley,曾与人工智能研究实验室教授Angjoo Kanazawa共同进行NeRF(Neural Radiance Fields,神经辐射场)相关的3D计算机视觉研究。
 图片
图片
首席科学家Jiaming Song,曾就读于清华大学计算机科学与技术系,获得了斯坦福大学博士学位,在 Stefano Ermon 教授的指导下学习机器学习和生成模型。在加入 Luma 之前,他曾参与 NVIDIA AI Foundations 的图像/视频/3D 生成模型的开发。
Jiaming目前正在研究生成 3D 内容的基础模型。他参与了 DDIM(第一个快速扩散模型采样器)和 SDEdit(扩散模型中第一个图像到图像的转换方法)的开发。
 图片
图片
首席科学顾问金泽安珠(Angjoo Kanazawa)是加州大学伯克利分校 EECS 系的助理教授。她的研究领域是计算机视觉、计算机图形学和机器学习的交叉领域,专注于日常照片和视频背后的动态 3D 世界的视觉感知。她对重建世界上的一切感到兴奋!她是斯隆研究员 (2023),热衷于创造有用的事物。她在马里兰大学帕克分校获得博士学位。
 图片
图片
这里,给大家一个传送门:
https://lumalabs.ai/dream-machine/
赶紧开启自己的大片之旅吧!
对了,据隔壁桌爱玩文生视频的同事反映,她最爱的还是国产快手的“可灵”,吸引她的有三点:国产自研的,中国人更懂中国人;第二点是,大幅度的合理运动也可以生成;第三点就是时长可以高达2分钟,而且支持自由的宽高比。当然,据悉,可灵也采用了类Sora的技术架构。【对话OpenAI,Sora你还不对外开放?】
话说回来,大家更喜欢哪款?






















