













作者 | robinhzhang
Redis(Remote Dictionary Server)是一个开源的内存数据库,遵守 BSD 协议,它提供了一个高性能的键值(key-value)存储系统,常用于缓存、消息队列、会话存储等应用场景。本文主要向大家分享redis基本概念和流程,希望能和大家一起从源码角度分析一条命令执行过程,希望能帮助开发同学掌握redis的实现细节,提升编程水平、设计思想。

一、源码结构
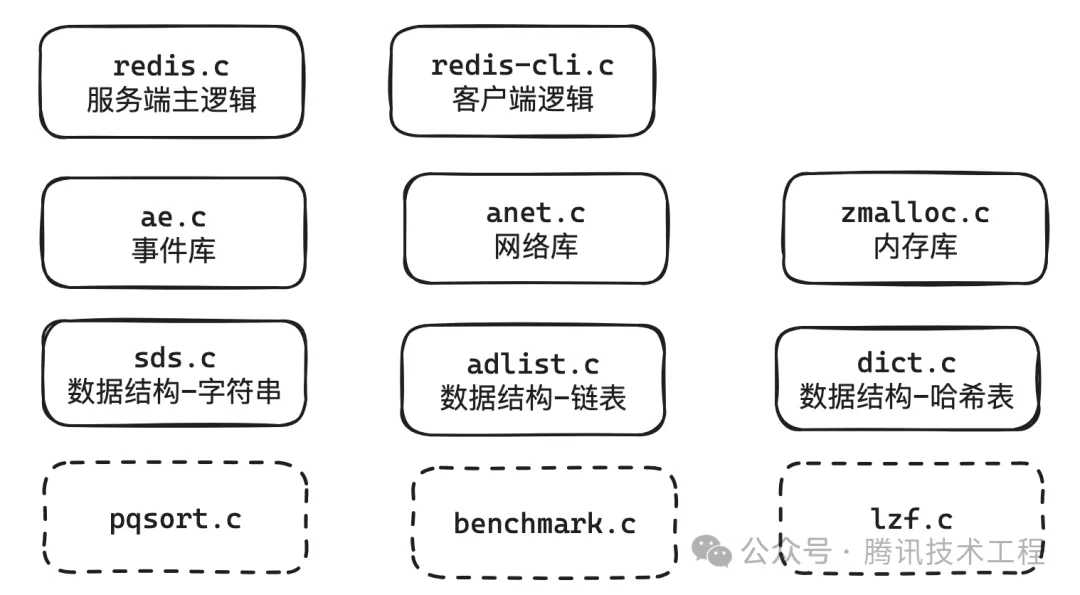
学习 Redis 源代码之前,我们需要对 Redis 代码的整体架构有一个了解,基于redis1.0源码,我们列出了主流程相关的如下源码文件。
二、核心数据结构
1. redisServer
redisServer是存储redis服务端运行的结构体,在启动的时候就会初始化完成,结构如下,它主要包含跟监听的socket有关的参数port和fd;对应存储数据的redisDb列表;链接的客户端列表clients;事件循环*el
2. redisClient
redisClient是客户端在服务端存储的状态信息,每当一个客户端与服务端链接时,都会新创建redisClient结构体到redisServer->clients列表中。
我们也用简单的示意图展示了redisClient的结构,它包含命令传输所使用的querybuf,命令在经过处理后会存放到argv中;然后比较重要的是*reply表示服务端给到客户端的回复的数据,这是个列表会在客户端写就绪的时候一个一个写回客户端,sentlen则是标识了传输的长度;然后就是对应的db与socket句柄fd。

3. redisDb
redisDb是redis的键值对存储的位置,主要包含两大块,一块存储数据,另一块存储过期信信息,dict结构实际上是两个哈希表,至于为什么有两个,这里是为了做渐进式rehash使用(后面会详细介绍),rehashidx用于表示rehash进度,iterators迭代器是表示遍历集合操作个数,表里面的元素就是entry,这里面包含key和value以及指向下一个元素的指针。
4. redisObject
redisObject是redis存储对象基本的表现形式,它可以存储类似SDS list set等数据结构,并且存储了一些信息用于内存管理,比如refcount这是一个整数字段,用于存储对象的引用计数。每当有一个新的指针指向这个对象时,引用计数会增加;当指针不再指向这个对象时,引用计数会减少。当引用计数降到 0 时,表示没有任何地方再使用这个对象,对象的内存可以被回收。lru在储对象的 LRU(最近最少使用)时间,这个时间戳是相对于服务器的 lruclock 的,用于实现缓存淘汰策略。当 Redis 需要释放内存时,它会根据这个时间戳来判断哪些对象是最近最少被使用的,从而决定淘汰哪些对象。
5. aeEventLoop
aeEventloop是redis事件模型基础数据,它主要包含文件事件和时间事件的两个链表。对于文件事件来说,包含文件句柄fd,事件类型mask,对应处理函数fileProc;对于时间事件来说包含id、执行时间(when_sec、when_ms)和对应执行函数timeProc 对应的源代码如下:

6. 小结
现在我们将redis核心概念的结构总结如下:

三、核心流程
了解完基本概念后,我们就看看基本流程了,首先我们从redis的main函数看起,看看启动的流程和命令执行的基本流程。
1. redis启动流程
(1) 主入口main()
在看一个软件的源码,一般从main函数看起,redis启动的main函数位于redis.c中,可以看起启动时,首先初始化了配置initServerConfig(),然后初始化了server端服务initServer(),接下来注册处理函数为acceptHandler的文件事件,然后启动了redis的主循环开始处理事件了。
然后我们看看initServer做了什么初始化,鉴于本文是阐述基本原理,因此注释掉了非主链路上的代码,可以看到它初始化了客户端列表、事件循环、db、创建了时间事件,将这几个核心的组件初始化了
(2) 主循环aeEventProcess执行过程
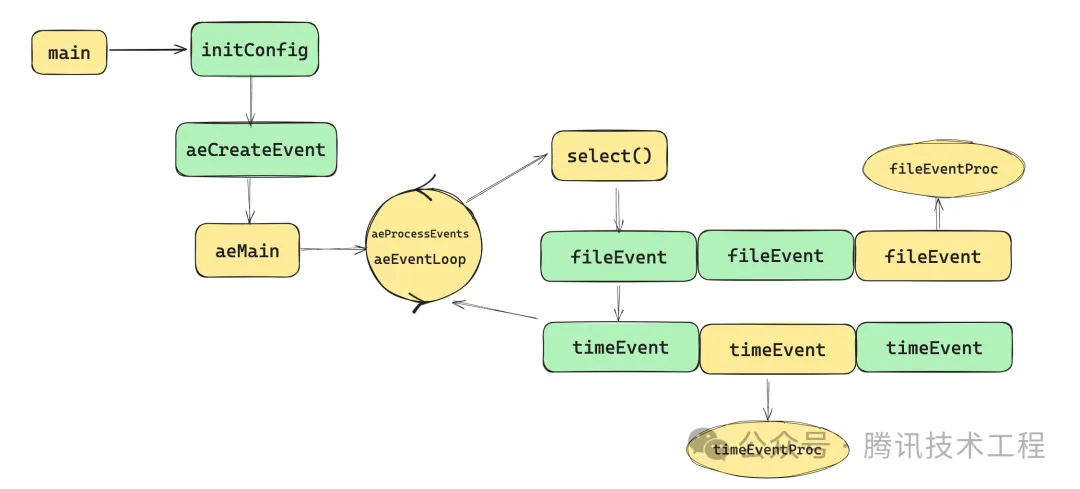
从上一节我们知道redis在main函数中调用aeMain函数 aeMain函数则不停的循环调用aeEventProcess处理事件,redis是事件驱动的程序,他主要包含文件事件和时间事件,在aeProcessEvents中处理处理这些事件。
①将这些文件事件装到不同的集合(可读、可写、异常)中
②计算超时时间 在调用select()函数的时候,在监听的fd没有就绪时,会阻塞住;这里还需要处理时间事件,因此我们需要给select()设置一个超时时间,以防阻塞的时候错过了执行时间事件。超时时间计算通过找到最近的一条时间事件的执行时间计算的到
③执行文件事件 拿到超时时间后就开始执行事件了,首先调用select(),传入事件集合(&rfds, &wfds, &efds),拿到就绪文件事件的个数,然后开始挨个检查就绪的文件事件执行,值的注意的是在redis1.0中调用的是select()系统调用,在后续的redis版本中调用的是epoll()相关函数。
④执行时间事件 时间事件的执行就相对简单一些,主要逻辑就是比较事件执行时间是否比当前时间大了,到达执行时间便执行;另外一个点是看这个事件是一次性的还是周期性,一次性的事件要删掉;另外下一次执行的时间点是回调函数返回的,然后写到事件的结构体中
(3) 小结
整个过程如图,简单来说:在redis启动时,在初始化配置和server的数据后,便启动了主循环aeMain,主循环的任务就是等待事件就绪和处理事件。对于文件事件,redis使用了 IO多路复用技术,通过系统调用select(),检查就绪的文件事件,就绪后则会遍历aeEventLoop进行事件处理;对于时间事件,则是与系统当前时间比较,就绪的执行。
2. 命令执行的完整流程
了解完redis整体事件驱动的运行架构后,我们看下redis的一条命令执行的过程中经过了哪些过程 简单来说有四个过程:redis启动、客户端前来连接、客户端发送命令到服务端、服务端回复结果给客户端。 下面让我们详细看看:
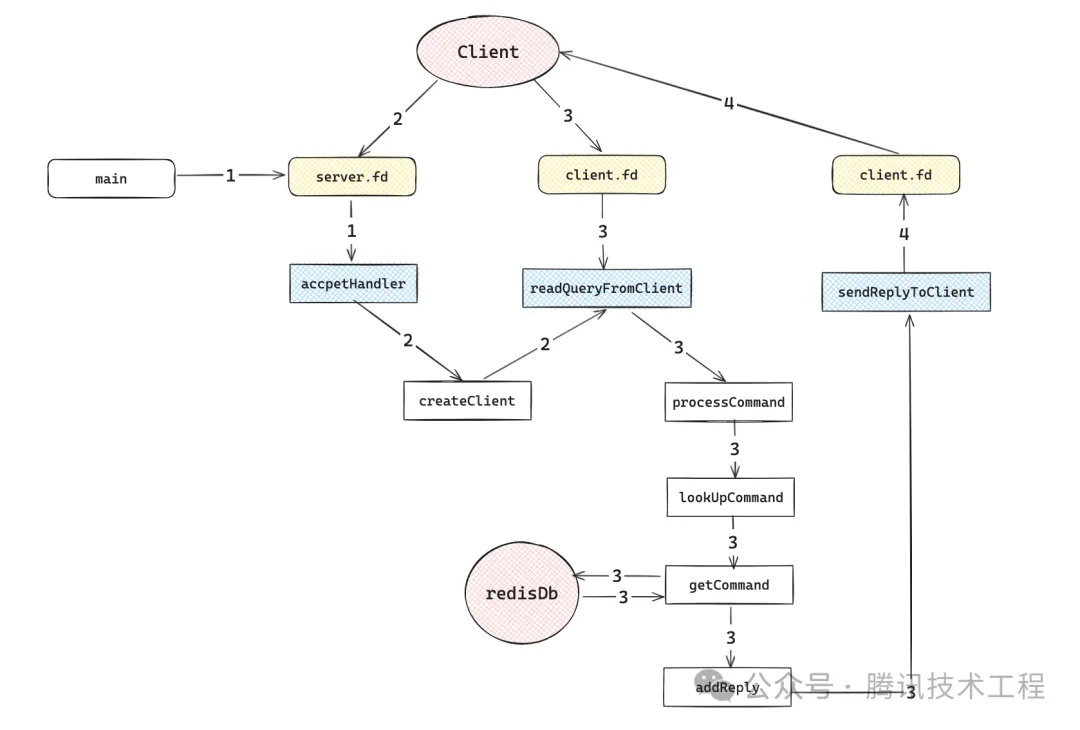
(1) 过程1(redis启动)
上一章中,redis在启动的时候会通过anetTcpSever创建一个socket server,再调用aeCreateFileEvent注册一个readable事件,回调函数为acceptHander,对应文件的句柄就是server的fd。
(2) 过程2(客户端与服务端建立链接)
第一个事件中处理函数是acceptHander,顾名思义就是接收客户端了链接并进行进一步处理,首先执行了anetAccept()函数,拿到了客户端和服务端交互的文件句柄fd,接下来执行createClient()函数,创建客户端实例
在createClient()中,初始化了redisClient的一些参数,最重要的是注册了一个文件事件,对应的执行函数是readQueryFromClient
(3) 过程3 (客户端发送命令给服务端)
接上文 当客户端发送命令到服务端时,数据到达服务端经过网卡、协议栈等一系列操作后,达到可读状态后,就会执行readQueryFromClient(),处理客户端传过来的命令,首先会执行read()方法从缓冲区中读取一块数据,将其追加到c->querybuf后面,根据redis协议进行querybuf的解析,并将其转换成sds的redisObject,存储到argv中,然后执行processCommand()处理命令,注意这里只是展示主流程的代码和说明,这里为了保证客户端输入能在各种情况下都work做了比较多的校验和错误处理;另外redis客户端和服务端交互的协议有两种一种是inline的、另外一种是bulk的,在querybuf转换成argv时,根据协议不同(bulklen==-1),走的也是不同的解析逻辑。
接下来我们继续看看重头戏processCommand的处理过程,首先执行lookupCommand,从cmdTable中遍历找到符合要求的命令,然后进行一些认证和数据合法性校验后,执行cmd的proc函数执行命令,执行完毕后,清理命令执行的过程数据。
让我们以get命令为例看看 getCommand()做了什么事,首先从DB里面去查找这个key,然后调用addReply,将结果回复加到回复队列中去,可以看到它回复了协议头、数据、协议尾三段数据。
让我们看看lookupKeyRead 做了什么,最终执行的是dict的方法dictFind,这个函数首先根据key算出在table中的位置,然后开始遍历entry链表,通过dictCompareHashKeys方法比较key是不是相等最终找到这个key取出返回。
具体是怎么回复结果的呢,addReply函数通过调用aeCreateFileEvent 创建了写入类型的文件事件,然后就是尾插法将要回复的obj添加到c->reply的尾部,等待fd写就绪时执行事件
(4) 过程4 (写就绪将结果写回客户端)
当 socket 的发送缓冲区有足够空间,并且网络状态允许数据发送时,socket 变为写就绪状态时,这时候就会aeEventLoop->fileEvents中取出就绪的reply事件,执行sendReplyToClient()函数,这个函数会遍历c->reply列表,按照顺序一个一个通过调用write()方法写回给客户端,值的注意的是,Redis 限制了单次事件循环中可以写入的最大字节数(REDIS_MAX_WRITE_PER_EVENT),防止一个客户端占用所有的服务器资源,特别是当该客户端连接速度非常快(例如通过本地回环接口 loopback interface)并且发送了一个大请求(如 KEYS * 命令),如果c->reply全写完了,就干掉这个写入事件
四、其他关键功能实现
1. 过期的实现
如前文所说,redis单独有个dict记录key的过期信息:
redis的key过期了不会立即删除,截止redis2.6的源码,有两种删除方式,一种是在执行key相关的命令执行之前调用expireIfNeeded(),检查key是否过期了。
另外一种是在启动的时候注册了serverCron时间事件,severcorn会定期调用activeExpireCycle()方法,这个方法核心逻辑调用dictGetRandomKey获取一些随机的key,然后检查下key是否过期了,如果过期了执行key删除和资源释放操作,值的一提的是activeExpireCycle使用了一种自适应算法来尝试过期(expire)一些超时的键。这个算法的目的是平衡 CPU 使用和内存占用,感兴趣的同学自己翻阅代码了解下。
2. 渐进式rehash
(1) 大哈希表rehash问题
经过上文我们已经知道dict实际上是个两个拉链的哈希表,在不断的添加key的过程中,hash表的冲突会增多,导致拉链会越来越长,极端情况下,哈希表的查找速度会退化到O(n),这时候就需要进行扩容处理了,扩容时会涉及大量的key计算新的hash值转移到新表,如果key的数量很多,这将是一个成本很高的操作。在早期的redis版本中(redis 1.0时)还是直接进行rehash操作。
(2) 渐进式rehash出现
显然,当哈希表巨大无比的时候,这样重的操作对于单线程的redis是不可以接受的,于是redis在2.x引入了渐进式rehash的方式,渐进式rehash将大而重的rehash操作分解为一个一个小的操作,将消耗均摊到每一个add请求中,我们从set key value 看起,看看redis rehash具体是怎么做的。
(3) 渐进式rehash-单步rehash
首先 setGenericCommand(),最终会调用dictAddRawd()函数,dictAddRawd()会在dict中新增一个key,然后调用dictSetVal()函数将值写进去。
接下看看dictAddRaw(),这个函数比较清晰,首先先看看是不是正在处于rehash状态(通过判断rehashIdx == -1),如果是则进行一步rehash,然后调用 _dictKeyIndex() 拿到这个新元素在表里面的index,接下来就是为新的entry分配内存,将节点插在头部,最后设置entry的key字段。
我们重点看看_dictRehashStep做了什么,首先判断了迭代器是不是为0,判断是不是迭代器正在遍历字典,如果有则不rehash,如果没有则开始执行一步rehash,首先校验下rehash是不是正在进行,如果不是则退出;接下来通过判断d->ht[0].used == 0(ht[0]表的元素完全被转移到ht[1]中了)看看是不是rehash完了,如果是的话,将ht[1]作为主表,清理原本的ht[0],并且将rehash标志位置为-1 (d->rehashidx = -1) 当然,如果没有rehash完,则开始rehash操作,首先找到第一个不为空的槽位,然后把这个槽位以及后面的entry list一个一个转移到ht[1]中。
(4) rehash扩容时机
什么时候开始rehash呢,这就看_dictKeyIndex()了,它调用了_dictExpandIfNeeded()函数。
_dictExpandIfNeeded()函数首先看看是不是初始化扩容,如果表ht[0]的size是0,则进行初始化扩容;如果不是则计算负载因子是不是达到了扩容的阈值,然后调用dictExpand()
(5) 渐进式rehash前置准备
dictExpand函数中,分配一个新的ht表,初始化参数,如果ht[0]是空的,说明是初始化扩容,直接将新创建的ht表给到ht[0],如果不是则将新创建的ht表给到ht[1],并且将rehashidx置为0,这时候就开始rehash了。
(6) 小结
redis渐进式rehash的过程如下图:
- 在有添加key的操作中,会调用dictAddRaw()函数,这里会根据rehashidx== -1看看是不是在rehash中,如果是则进行单步rehash;
- 另外再尝试获取一个entry的index时,redis会看看当前ht[0]表是不是该扩容了,如果是则分配ht[1]的资源并将rehashidx置为0,开始reshsh;
- 当ht[0].used变为0时,则认为rehash完成了,这时候将h[1]作为主表,释放之前h[0]的资源

3. redis对象生命周期
(1) redisObject与refcount
上文中我们了解到,为了高效管理内存,避免在命令处理时产生的拷贝,redis提出了share everything的思想,采用了引用计数法管理内存,计数在redisObject->refcount字段,在新创建redisObject时设置refcount为1,调用incrRefCount(),引用计数会+1
调用decrRefCount()时,会讲refcount-1,当引用计数为0时,会按照类型进行内存释放。
(2) set命令key/value生命周期
让我们以set命令为例,看看key和value声明周期是怎么管理的 首先从上文知道 当调用set命令发送到服务端时会调用readQueryFromClient读取并进行预处理时会调用createObject,将key和value转成redisObject放到argv中,这时候key:1 value:1
然后调用processCommand()处理命令,processCommand()通过lookupCommand()拿到:
最终执行了setGenericCommand(),这里如果是正常处理的话,可以看到调用了incrRefCount将argv[1]和argv[2]的引用计数都增加了1,这时候key:2 value:2
在processCommand()执行结束的时候,会调用resetClient重制客户端资源为下次命令做好准备,这时候会将argv的引用计数全部-1,这时候key:1 value:1,就仅仅是dict存储的那一份了再引用了。
小结:整个过程可以通过下图看到:
- 命令处理时,createObject()得到keyObj valueObj,refcount都为1
- 执行setCommand的时候,调用了incrRefCount()方法,两者refCount都变为2
- 在processCommand调用结束的时候,执行resetClient清理资源为下条做准备时,执行了decrRefCount,两者又都变为1,此时,key val的引用计数为1,即在dict中存在的一个引用

get命令我们不过多阐述,这里阐述下具体过程:
- 命令处理时,createObject()得到keyObj valueObj,key refcount为1
- 然后调用getCommand后,再调用dictFind,在找到后addreply的时候调用了incrRefCount(),value的refcount此时从1变为2
- 在命令执行完毕的时候,会重置客户端,执行了decrRefCount,此时key的refcount变为0,被清除掉
- 在reply元素传输完毕删除的时候调用listDelNode删除元素,然后会调用list->free函数,free函数实际上是decrRefCount,这是value的refcount由2变为1。

五、总结与展望
本文阐述了三方面的基本内容:
- redis基本的概念,包含redisServer redisDb redisClient aeEventLoop等核心概念;
- 介绍了redis启动和命令处理的基本流程;
- 介绍了重要的过程,过期、渐进式rehash和redisObject生命周期,当然redis 除了本文介绍了单机方面的一些知识外,还有分布式、集群、数据结构等很多值得学习的地方。






















