












本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人理解
文章提出了一个基于扩散的4D占用生成模型OccSora来模拟自动驾驶世界模型的进展。该模型使用一个四维场景标记器来获得四维占用输入的时空表示,并实现长序列占用视频的高质量重建。然后,学习时空表征的扩散转换器,并根据轨迹提示生成4D占用。OccSora可以生成具有真实3D布局和时间一致性的16秒视频,展示其对驾驶场景时空分布的理解能力。
开源链接:https://wzzheng.net/OccSora/
主要贡献
传统的自动驾驶模型依靠车辆自身的运动来模拟场景的发展,所以无法像人类那样对场景感知和车辆运动有深刻的理解;世界模型的出现能够更深层次地理解自动驾驶场景和车辆运动之间的综合关系。然而现阶段的大多数方法采用自回归框架来模拟3D场景,这阻碍了该模型有效地生成长期视频序列的能力。
所以如图1所示,相较于先前的方法,该模型基于2D视频生成模型Sora,提出了一个4D世界模型OccSora。其设计了一种基于扩散的世界模型来实现遵循物理规律的可控场景生成。具体来说,采用多维扩散技术传递准确时空四维信息,并以真实汽车轨迹为条件实现轨迹可控的场景生成,从而更深入地理解自动驾驶场景与车辆运动之间的关系。OccSora通过训练和测试,可以生成符合物理逻辑的自动驾驶4D占用场景,实现基于不同轨迹的可控场景生成。提出的自动驾驶4D世界模型为理解自动驾驶和物理世界中的动态场景变化开辟了新的可能性。
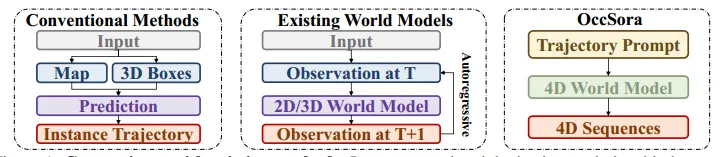
图1 现有方法的比较
具体方法
1、自动驾驶系统的世界模型
4D占用可以全方位的捕捉三维场景的结构、语义和时间信息,有效促进弱监督或自监督学习,可应用于视觉、激光雷达或多模态任务。基于此,该论文把世界模型X表示为4D占用R。图2展示了OccSora的总体框架。
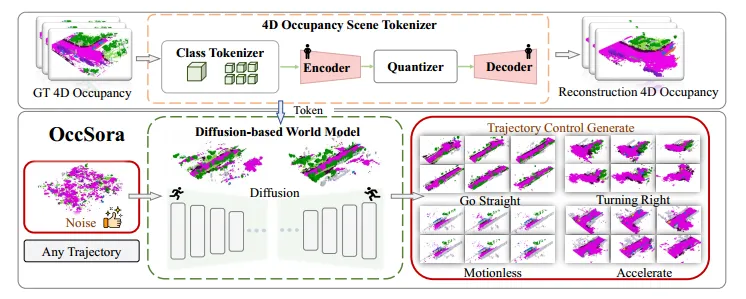
图2 OccSora模型总体框架

2、4D占用场景标记器

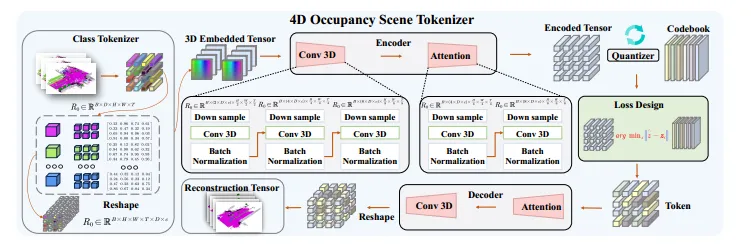
图3 4D占用场景标记器的结构
(1)类别嵌入和标记器

(2)3D视频编码器

(3)码本和训练目标

(4)3D视频解码器

3、基于扩散的世界模型

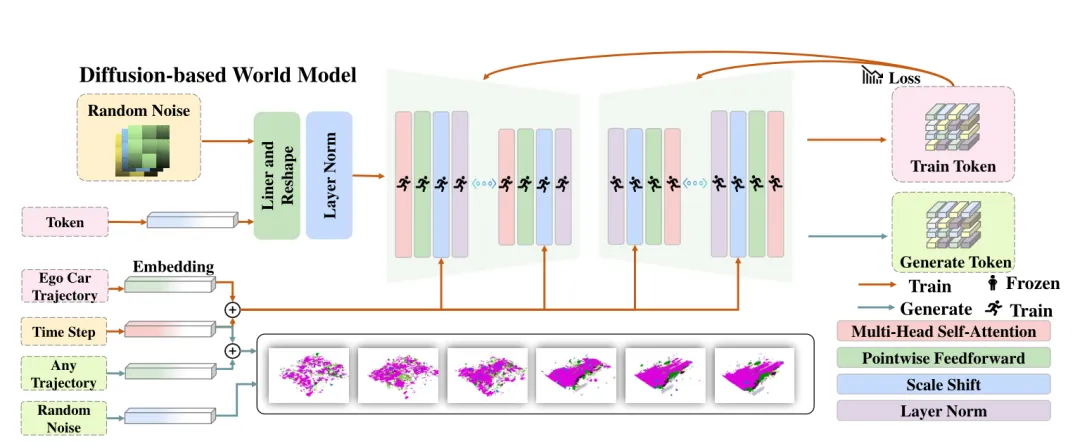
图4 基于扩散的世界模型的框架
(1)token嵌入

(2)轨迹调节嵌入

(3)扩散transformer
4、实验
OccSora作为自动驾驶领域的4D占用世界模型,可以在不需要任何3D边界框、地图或历史信息输入的情况下,更深入地理解自动驾驶场景与车辆轨迹之间的关系。它可以构建一个遵循物理定律的长时间序列世界模型。
(1)实现细节
(2)4D占用重建
压缩和重建四维占用是学习图像生成所需的潜在时空相关性和特征的必要条件。与传统的视频和图像处理模型不同,OccSora的操作比单帧占用率高一个维度,比图像高两个维度。因此,实现有效的压缩和准确的重建是至关重要的。图5描绘了4D占用的真实情况和重建情况。
 图5 4D占用场景标记器重建的可视化
图5 4D占用场景标记器重建的可视化
此外还对4D占用重建进行了定量分析,如表1所示。从表中可以看出,即使OccSora实现了比OccWorld高32倍的压缩比,它仍然保持了原始OccWorld模型近50%的mIoU。这种统一的时间压缩有效地捕获了各种元素的动态变化,与渐进式自回归方法相比,提高了长序列建模能力。
表1 4D占用重建的定量分析
(3)4D占用生成
在四维占用生成任务的基于扩散的世界模型中,使用OccSora模型生成的token,经过32帧的训练,作为生成实验的输入。在图6中展示了从10,000到1,200,000步的跨训练迭代的可视化结果。这些视觉结果表明,随着训练迭代次数的增加,OccSora模型的精度不断提高,显示出连贯场景的生成。
 图6 精确场景的逐步生成可视化
图6 精确场景的逐步生成可视化
同样的将提出的OccSora模型与其他代模型进行了比较和定量评估。作为第一个用于自动驾驶的4D占用世界模型,仅将其与传统的图像生成、2D视频生成和静态3D占用场景生成方法进行了比较。如表2所示,OccSora模型在起始距离(FID)方面取得了不错的性能,证明了所提出方法的有效性。
表2OccSora与其他模型在生成能力上的比较
轨迹视频生成。OccSora能够根据不同的输入轨迹生成各种动态场景,从而学习自动驾驶中自我车辆轨迹与场景演化之间的关系。如图7所示,将不同的车辆轨迹运动模式输入到模型中,展示了直行、右转和静止的4D占用情况。此外进行了不同尺度的轨迹生成实验,结果表明,静止场景的FID得分最低,而弯曲场景的FID得分较高,这表明连续建模弯曲运动场景的复杂性和建模静止场景的简单性。
 图7 不同输入轨迹下的4D占用生成
图7 不同输入轨迹下的4D占用生成
场景视频生成。在合理的轨迹控制下,场景的多样性至关重要。为了验证在可控轨迹下生成场景的泛化性能,OccSora模型对三种轨迹下不同场景的4D占用场景重建进行了测试。在图8中,左右两部分分别展示了在同一轨迹下产生不同场景的能力。在重建的场景中,周围的树木和道路环境表现出随机变化,但仍然保持了原始轨迹的逻辑,显示了在生成与原始轨迹对应的场景及其在不同场景中的泛化方面保持鲁棒性的能力。
 图8 在轨迹控制下生成多种连续场景
图8 在轨迹控制下生成多种连续场景
(4)消融实验
标记器与嵌入分析。对提出的组件进行了消融实验,包括不同的压缩尺度、类标记器离散化的数量、时间步嵌入和车辆轨迹嵌入,如表3所示。当类标记器离散化的数量从8个减少到4个时,重构精度下降了大约18%。
表3 不同组件之间的消融实验结果
在去除时间步长嵌入组件后,FID得分也有所下降。在没有位置嵌入的情况下,生成的场景缺乏运动控制,并且受数据分布的影响几乎呈线性运动模式。此外,在较低的压缩比下,尽管重建性能优于较高的压缩比,但缺乏高维特征相关性会阻碍有效场景的生成。
生成步骤分析。去噪的总步数和去噪率会在一定程度上影响生成质量。如图9所示,随着去噪率的提高,生成的场景逐渐清晰。从表4的定量结果可以看出,增加去噪步骤总数可以在一定程度上提高生成精度。然而,token大小和信道数量对生成质量的影响要比对去噪步骤总数的影响大得多。
表4 不同尺度对去噪步骤和去噪率的定量分析。
 图9 不同轨迹或去噪步骤下去噪比的影响
图9 不同轨迹或去噪步骤下去噪比的影响
5、结论与限制
在本文中,介绍了一个生成4D占用的框架,以模拟自动驾驶中的3D世界发展。使用4D场景标记器,获得了输入的密集表示,并实现了长序列占用视频的高质量重建。然后,学习时空表征的扩散转换器,并在轨迹提示的条件下生成4D占用。通过在nuScenes数据集上的实验,证明了场景进化的准确性。未来,将研究更精细的4D占用世界模型,探索闭环设置下端到端自动驾驶的可能性。
局限性。4D占用世界模型的优势在于建立了对场景和运动之间关系的理解。然而,由于体素数据粒度的限制,无法构建更精细的4D场景。生成结果还显示运动对象的细节不一致,可能是由于训练数据的小尺寸。

























