本文经计算机视觉研究院公众号授权转载,转载请联系出处。

- 论文地址:https://arxiv.org/pdf/2405.19629
PART/1
摘要
Transformers是自然语言处理领域的一项革命性技术,它也对计算机视觉产生了重大影响,有可能提高准确性和计算效率。YotoR将坚固的Swin Transformer主干与YoloR颈部和头部相结合。在实验中,YotoR模型TP5和BP4在各种评估中始终优于YoloR P6和Swin Transformers,比Swin Transformer模型提供了改进的目标检测性能和更快的推理速度。这些结果突出了进一步的模型组合和改进Transformer实时目标检测的潜力。最后强调了YotoR的更广泛含义,包括它在增强基于Transformer的图像相关任务模型方面的潜力。
PART/2
背景&动机
在过去的十年里,卷积神经网络彻底改变了计算机视觉应用,实现了目标检测、图像分割和实例分割等任务求解。尽管近年来卷积网络主干得到了改进,甚至在一些任务上超过了人类的性能,但Transformer在计算机视觉任务中的使用在几年内仍然难以捉摸。Transformer在计算机视觉任务中的首次应用于2020年提出。然而,由于图像的高分辨率,Transformers的使用仅限于图像分类等低分辨率应用。像物体检测这样的高分辨率任务需要开发更专业的Transformer架构,比如Swin Transformer,它通过动态改变注意力窗口来规避变形金刚的计算限制,并允许它们用作多视觉任务的通用主干。此外,基于DETR等Transformer的目标检测头在以前由卷积神经网络主导的任务中已经成为最先进的。
另一方面,以Yolo/YoloR家族为例的实时目标检测器对于依赖高帧率的任务(如自动驾驶)或受有限硬件资源限制的平台上的任务仍然是必不可少的。尽管计算机视觉的Transformer最近取得了进展,但实时物体检测主要依赖于卷积神经网络。它们在特征提取中建立的可靠性和计算效率一直是Transformers需要克服的挑战。然后,将Transformer与类Yolo目标检测器相结合,可以提供能够实现高帧率和高检测精度的新型架构。
PART/3
新框架
多任务架构的使用前景看好,因为它们可以整合多种信息模态以提高所有任务的性能。然而,设计能够在实时中执行多任务的建筑结构是具有挑战性的,因为使用每个任务的网络集合会负面影响系统的运行时间。

在这项工作中,引入了一系列网络体系结构,将Swin Transformer主干与YoloR头融合在一起。受Yolo命名法的启发,这些架构被命名为YotoR:You Only Transform One Representation。这反映了使用由Transformer块生成的单一统一表示,该表示通用且适用于多个任务。该提案背后的想法是使用强大的Swin Transformers特征提取来提高检测精度,同时还能够通过使用YoloR头以快速推理时间解决多个任务。
Backbone
与YoloR及其基本模型P6之间的关系类似,YotoR TP4是YotoR模型的起点,代表了最基本的组件组合。使用不变的SwinT主干也有一个显著的优势,可以应用迁移学习技术。这是因为,通过不改变Swin Transformer的结构,可以使用其创建者公开提供的重量。这简化了将预先训练的Swin-Transformer权重转移到其他数据集的过程,加快了训练过程并提高了性能。

Head
为了构建YoloR模型,决定以Scaled YoloV4的架构为基础。特别是,他们从YoloV4-P6光作为基础开始,并依次对其进行修改,以创建不同版本的YoloR:P6、W6、E6和D6。这些版本之间的变化如下:
–YoloR-P6:用SiLU替换了YoloV4-P6-light的Mish激活功能
–YoloR-W6:增加了主干块输出中的通道数量
–YoloR-E6:将W6的通道数乘以1.25,并用CSP卷积代替下采样卷积
–YoloR-D6:增加了骨干的深度
YotoRmodels
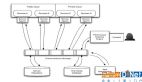
选择YotoR模式进行实施涉及到两个重要方面。首先,分析了Swin Transformer主干生成的特征金字塔尺寸与YoloR头所需尺寸之间的差异。这些维度之间的显著差异可能会在网络中造成瓶颈,从而限制其性能。其次,为了调整连接,Swin Transformer的功能必须重新整形为带有注意力图的图像。然后将其归一化并通过1×1卷积来调整通道的数量。这样做是为了使YoloR头具有与DarknetCSP主干相同的功能大小,并软化连接之间的信息瓶颈。

显示了YotoR BP4体系结构。它介绍了STB(Swin Transformer Block),代表了不同YotoR架构中使用的Swin TransformerBlock。此外,在这些组件之间还包含一个线性嵌入块。这个线性嵌入块来自用于目标检测的Swin Transformer实现,并在没有更改的情况下被合并到YotoR实现中。之所以选择这四个模型,是因为它们由YoloR和Swin Transformer的基本架构组成,从而可以进行有效的比较来评估所提出的模型的有效性。虽然考虑了对YotoR BW4或YotoR BW 5等大型模型进行训练和评估,但V100 GPU的资源限制使此选项不可行。
PART/4
实验及可视化
训练参数:



左图:val2017和testdev的图片。右图:YotoR BP4的预测。
与开始时的状态比较(批次=1,GPU=V100)。*表示我们自己使用16GBV100GPU确认的测量结果