概述:在Python爬虫过程中,HTTP状态码403通常是因为网站的反爬虫机制生效。解决方法包括设置合适的User-Agent、使用代理IP、降低爬取频率、携带必要的Cookies和模拟合法的页面跳转。对于动态渲染页面,可考虑使用Selenium等工具。在爬取前需遵循网站的robots.txt规定,尊重合法API。综合这些方法,可以规避反爬虫机制,但需确保遵守法规和网站规定。
HTTP状态码403表示服务器理解请求,但拒绝执行它。在爬虫中,这通常是由于网站的反爬虫机制导致的。网站可能检测到了你的爬虫行为,因此拒绝提供服务。以下是可能导致403错误的一些原因以及相应的解决方法:
1.缺少合适的请求头(User-Agent):
- 原因: 有些网站会检查请求的User-Agent字段,如果该字段不符合浏览器的标准,就会拒绝服务。
- 解决方法: 设置合适的User-Agent头,模拟正常浏览器访问。
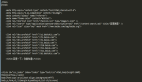
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'}
response = requests.get(url, headers=headers)2.IP被封禁:
- 原因: 如果你的爬虫频繁访问某个网站,可能会触发网站的IP封禁机制。
- 解决方法: 使用代理IP轮换或者减缓爬取速度,以避免IP被封。
proxies = {'http': 'http://your_proxy', 'https': 'https://your_proxy'}
response = requests.get(url, headers=headers, proxies=proxies)3.请求频率过高:
- 原因: 爬取速度过快可能会被网站认为是恶意行为。
- 解决方法: 在请求之间增加适当的延迟,以模拟人类访问行为。
import time
time.sleep(1) # 1秒延迟4.缺少必要的Cookies:
- 原因: 有些网站需要在请求中包含特定的Cookie信息。
- 解决方法: 使用浏览器登录网站,获取登录后的Cookie,并在爬虫中使用。
headers = {'User-Agent': 'your_user_agent', 'Cookie': 'your_cookie'}
response = requests.get(url, headers=headers)5.Referer检查:
- 原因: 有些网站会检查请求的Referer字段,确保请求是从合法的页面跳转而来。
- 解决方法: 设置合适的Referer头,模拟正常的页面跳转。
headers = {'User-Agent': 'your_user_agent', 'Referer': 'https://example.com'}
response = requests.get(url, headers=headers)6.使用动态渲染的页面:
- 原因: 一些网站使用JavaScript动态加载内容,如果只是简单的基于文本的爬取可能无法获取完整的页面内容。
- 解决方法: 使用Selenium等工具模拟浏览器行为。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
page_source = driver.page_source7.遵循Robots.txt规定:
- 原因: 爬虫爬取的行为可能违反了网站的robots.txt中的规定。
- 解决方法: 查看robots.txt文件,确保你的爬虫遵循了网站的规定。
8.使用合法的API:
- 原因: 有些网站提供了正式的API,通过API访问可能更合法。
- 解决方法: 查看网站是否有提供API,并合法使用API进行数据获取。
通过以上方法,你可以尝试规避反爬虫机制,但请注意在进行爬取时应该尊重网站的使用规定,避免过度请求和滥用爬虫行为。