相信很多的小伙伴在面试的时候,涉及到MQ的面试题,消息丢失是必问面试题之一。那么对于消息丢失你又是如何理解的呢?
下面我们一起来看一下。
本文以 Kafka 举例说明。

一、什么是消息丢失?
消息丢失的定义是:在消息传递的过程中,在某个环节意外丢失,也就是消息没有成功的发送或者没有被正确的接收。
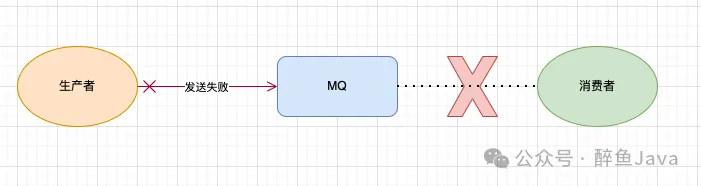
生产者未能成功发送消息。
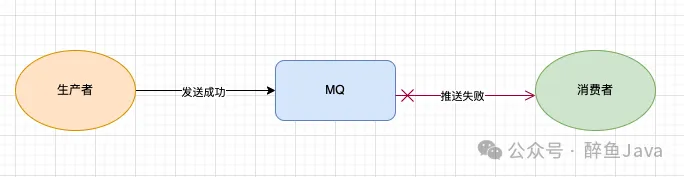
消费者未能正确接收消息。
消费者未能正确处理消息。

对于第三条可以理解为特殊的消息丢失,因为消费者的逻辑处理错误,程序bug等其他原因,造成消息在处理过程中消息丢失或者被忽略(异常之后错误的应答等),也就是说消息没有正确的被消费掉,我们也可以认为是一种消息丢失。
二、消息丢失的原因有哪些
1.消息生产阶段
- 生产者配置错误:生产者在发送消息时,配置错误的主体、分区或者消息的过期时间,造成消息无法正确发送到MQ中。
- 网络故障:生产者与MQ集群之间网络故障。
2.消息存储阶段
- 磁盘故障:以Kafka举例,如果磁盘出现故障,Kafka中的消息无法洛盘,可能导致消息的丢失。
- 日志压缩策略:使用了压缩比较高的压缩策略从而可能在压缩的过程中丢失消息。
3.消息消费阶段
- 消费者处理失败:在处理消费逻辑时,由于程序bug等原因,造成系统异常,错误应答从而丢失消息。
- 消费者提交偏移量错误:当消费者消费完消息之后,提交错误的偏移量造成消息的重复消费或者消息丢失。
三、消息丢失的解决方案有哪些
1.消息生产阶段
(1) 配置正确的主体、分区、以及TTL。
(2) 使用ACK应答,等待消息被MQ写入成功之后在确认为发送成功。
- ack=1:默认值,leader副本成功写入消息即发送成功。
- ack=0:发送消息后不等待服务端确认。
- ack=-1或者ack=all:生产者需要等待ISR中的所有副本都成功写入消息才为消息发送成功。
(3) 消息发送重试。
- retries:配置生产者发送消息重试次数。
(4) 配置合理的压缩策略。
- compression.type 支持none、gzip、snappy、lz4、zstd。
(5) 设置合理的消息缓冲区大小。
- buffer.memory:默认33554432。生产者用于缓存一批发送到服务器消息的总内存字节数。
(6) 使用合适的序列化器,防止序列号错误造成消息丢失。
其他的配置可以参考官网 Kafka 生产者配置:https://kafka.apache.org/documentation/#producerconfigs
2.消息存储阶段
- 配置适当的副本数量和ISR。在发生故障的时候消息仍然可以从其他的副本中进行恢复。
- 使用监控,实时检测消息的复制、磁盘的使用率。
- 定期备份。
3.消息消费阶段
(1) 编写健壮的代码,说的容易,写起来还是得多测试。对于可能产生的异常原因进行分析处理。当发生异常时,可以做如下处理:
- 记录错误,有异常处理机制,保证能够正确的处理异常情况。
- 消息重试消息。(需要注意消费幂等以及死循环造成消息堆积)
(2) 使用手动提交偏移量。(需保证所有的异常情况代码中都有对应的异常处理机制,也就是第一点,健壮的代码)
(3) 使用自动提交偏移量。(需要保证消费逻辑正确)
(4) 使用监控,监控消费者的消费情况,发现异常立即上报。
(5) 正确的消费者组管理,类似消费者重平衡或者重启等造成的消息偏移量丢失。
(6) 备份,发生异常或者消息丢失时,可以跟踪到消费者的消费情况,直接使用备份恢复。
总结
上面我们分析了什么是消息丢失,产生的原因有哪些以及如何解决。通过看完这篇文章相信你对Kafka中的消息丢失也有了一定的了解,在工作中使用的时候也就不会没有底气了。
相信有眼尖的小伙伴发现了,在消费者的处理逻辑中,多次消费会造成消息的多次重复消费。消息的重试也有可能造成消息的堆积。那么这些问题就是下节课我们要说的。