作者 | 陈峻
审校 | 重楼
引言

如今,基于互联网服务的欺诈案例时常登顶媒体头条,而使用在线服务和数字交易的金融行业尤其成为了重灾区。网络洗钱、保险欺诈、网银盗用、虚假银行交易等复杂金融欺诈行为层出不穷,我们亟待通过行之有效的欺诈识别与检测的手段,来保护个人和组织免受巨大的经济损失。
作为一种自适应性强、可扩展性高的技术,机器学习算法具有从数据中学习、发现复杂模式的能力,因此被广泛地应用于各种科学领域。而检测金融欺诈正是其能够大显身手的新赛道。
模型介绍
目前,被用于金融欺诈检测的典型算法包括:逻辑回归(LR)、支持向量机(SVM)、K-近邻(KNN)、奈夫贝叶斯(NB)、决策树(DT)、随机森林(RF)和增强奈夫贝叶斯 (TAN)等。其中,
- SVM使用最佳超平面对数据点进行分类
- KNN根据K-Nearest Neighbors对交易进行分类
- NB使用概率学习来估计类别的概率
- DT通过生成决策树以进行基于特征的分类
- RF结合决策树以减少过拟合
- TAN通过树状依赖结构来增强NB以捕捉特征相关性
这些模型为识别和检测金融欺诈提供了多种方法,有助于建立出强大的实时欺诈检测系统。当然,它们各有利弊,在为具体应用选择算法时,我们需要考虑数据集的大小、特征空间、处理需求、以及可解释性等因素。
为此,一种改进的集合机器学习(Ensemble Machine Learning)技术应运而生。它能够将多个单独的算法模型组合在一起,通过重点优化模型的各项参数、提高性能指标,以及整合深度学习(如Bagging、Boosting和Stacking),进而创建出可以修复识别到的错误、并减少假阴性的强大欺诈检测系统。
集合学习检测模型
既然是组合,那么我们便可以综合选配各种机器学习分类器。而每一种分类器都会以其独特的优势发挥应有的作用。

如上图所示,一个典型的金融欺诈类识别与检测模型会包括如下组件:
- SVM,擅长为类别分离确定适当的超平面
- LR,对事件概率进行建模
- RF,能够建立稳健的决策树
- KNN,根据近邻中的多数类进行分类
- Bagging,会使用KNN作为基本分类器,以进一步丰富集合
- Boosting,使用RF作为基础分类器
- 最下方的投票分类器(Voting Classifier)可以综合上述分类器的各种预测结果
由于采用了集合机器学习的协同方式,因此该模型在检测金融领域少数类别的数据,以及解决类别不平衡方面,具有出色的表现。其根本意愿在于,集合模型有助于聚集不同的弱学习算法,以增强其整体识别与检测能力,进而提高相关决策的可解释性和透明度。此外,与深度学习架构相比,集合式计算的密集度较低,因此也更适合金融领域本来就计算资源有限的场景。
检测模型的评估
我们该如何来评估机器学习系统对于具体金融欺诈的检测效果呢?通常,业界会采用如下基本流程:
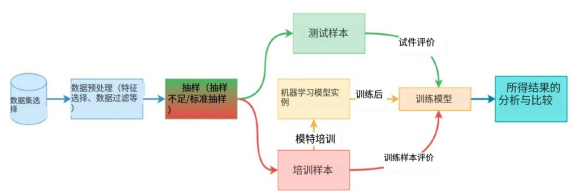
- 首先,选择一个包含了合法交易和欺诈交易记录的数据集。
- 由于数据集中存在着各种无序、原始、残缺、以及重复的实例,系统的检测很容易出现误差,因此我们需要进行数据预处理,使其适合模型的训练和测试。
- 接着,鉴于欺诈交易只占整体交易数据的一小部分,我们需要对不平衡的数据集进行采样。
- 然后,系统将整理好的采样数据分为训练样本和测试样本,使用其中的训练样本对已选的机器学习模型进行训练,并使用这两种样本来观察训练模型的行为。
- 在获得准确率、精确度、召回率、F1分数等选定评估参数的结果后,对系统的整体能力进行分析和比较。
模型评估标准
在评估模型的清晰度和理解度时,业界通常会使用混淆矩阵(Confusion Matrix)。如下图所示,该矩阵由真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)四个直观的象限组成:

基于上述矩阵,目前被业界广泛认可的是模型评估标准通常包括:准确率、精确度、召回率和F1分数四个方面的指标。其中:
- 准确率,是所有正确预测(TP + TN)与样本中预测或条目总数(TP + TN + FN + FP)之比。
- 精确度,是TP与模型所做的所有正面预测(TP + FP)之比。换句话说,它是模型做出的正面预测的准确度。
- 召回率,是用来衡量机器学习模型识别正向类所有实例的能力指标。它是正确预测到的阳性观察结果(TP)与实际阳性观察结果总数(TP+FN)的比率。
- F1分数,是将精确度和召回率的结果合并为一个平衡的平均值指标。
评估模型的准确率
目前,有专家将集合学习模型与里面包含的LR、RF、KNN、Bagging、Boosting模型进行了逐一比较。就同样的数据集测试样本而言,其结果的精确度、召回率和F1分数如下表所示:
LR | RF | KNN | Bagging | Boosting | 集合学习模型 | |
精确度 | 0.945938 | 0.999891 | 0.999174 | 0.999 | 0.999092 | 0.999601 |
召回 | 0.944256 | 0.99989 | 0.999173 | 0.999 | 0.999092 | 0.9996 |
F1分数 | 0.944204 | 0.99989 | 0.999173 | 0.999 | 0.999092 | 0.9996 |
可见,集合学习模型能够很好地捕捉到相关数据,对其进行精确预测,从而实现了对特定数据的高灵敏度,并保持了稳定的较低误判率。
下表则更全面地向您展示了将各种典型机器学习算法,被运用到实时金融欺诈场景的准确率综合比较:
金融欺诈场景 | 机器学习算法 | 准确率 |
信用卡欺诈检测 | 卷积神经网络 | 99% |
信用卡欺诈检测 | 长短期记忆 | 99.5% |
欺诈性信用卡识别 | 直觉贝叶斯 | 96.1% |
欺诈性信用卡识别 | KNN | 95.89% |
欺诈性信用卡识别 | 随机森林 | 97.58% |
欺诈性信用卡识别 | 序列卷积神经网络 | 92.3% |
银行B2C 在线交易 | 卷积神经网络 | 91% |
信用卡交易数据集 | 分布式深度神经网络 | 99.9422% |
评估模型效率
除了准确率维度,我们也应该评估模型的计算效率。这往往涉及到在检测过程中,模型所需的训练和测试时间,以及这些过程对内存和存储等系统资源的利用率。
算法训练 | 在训练样本上测试 | 在测试样本上测试 | ||||
时间(毫秒) | 内存使用量(MiB) | 时间(毫秒) | 内存使用量(MiB) | 时间(毫秒) | 内存使用量(MiB) | |
LR | 3.5 | 1190.03-1190.64 | 2.9 | 1190.65-1190.65 | 2.5 | 1190.77-1190.77 |
RF | 1135 | 1295.93-1296.31 | 19.9 | 1296.31-1296.31 | 8.28 | 1296.31-1296.33 |
KNN | 0.597 | 1190.77-1288.20 | 1431 | 1288.20-1294.43 | 355 | 1295.43-1295.89 |
Bagging | 9.23 | 1147.86-1841.64 | 10179 | 1841.89-819.89 | 2331 | 820.93-1342.43 |
Boosting | 883 | 1341.71-1454.40 | 14.8 | 1454.46-1458.23 | 6.05 | 1456.50-1456.86 |
集合学习模型 | 2049 | 1455.36-2282.86 | 11681 | 2282.89-2158.89 | 2928 | 2155.05-2028.86 |
注意:上表中的内存使用值是以兆字节(MiB)为单位,换算系数关系为1 MiB等于1.04858 MB。
总体而言,不同算法的训练和测试时间各不相同。其中,LR、SVM和KNN算法的训练时间较长,但测试时间较短;而其他模型则呈现出相反的趋势。
小结
综合上述,通过利用各种计算学习算法,我们不但可以提高金融欺诈检测的准确性和效率,而且能够尽早地发现潜在的欺诈活动,进而及时采取预防和抵御的措施,以减少其影响。
同时,随着信用卡欺诈技术的不断发展,能够有效综合各种算法优势的集合机器学习检测模型,已为我们进一步开发更具扩展性和适应性的欺诈检测系统,奠定了基础。从而在保证金融系统安全的同时,持续维护了消费者对于多元化互联网金融交易的信心。
作者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。