在日常开发中,经常涉及到 VO、DTO、DO等对象之间的属性拷贝,为了避免使用原始的setter和getter方法,我们通常过借助一些三方工具,本文我们将聊聊某程序员使用BeanUtils.copyProperties工具,导致差点被开除的血泪史。

一、BeanUtils.copyProperties是什么?
BeanUtils.copyProperties是一个对象拷贝的常用工具,Spring和Apache都提供了对应的静态方法,两者源码如下:
// org.springframework.beans.BeanUtils
public static void copyProperties(Object source, Object target) throws BeansException {
copyProperties(source, target, null, (String[]) null);
}
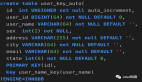
// org.apache.commons.beanutils.BeanUtils
public static void copyProperties(final Object dest, final Object orig)
throws IllegalAccessException, InvocationTargetException {
BeanUtilsBean.getInstance().copyProperties(dest, orig);
}通过上述两个源码方法可以发现:两个方法中的入参源对象和目标对象 顺序是反的,所以在使用时,一定要注意具体导入的是哪一个BeanUtils,切勿把入参顺序搞反。
接着,分别解析两种方式的源码实现原理:
1.Spring实现
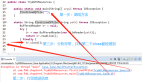
org.springframework.beans.BeanUtils的源码实现如下图:

整个源码的实现逻辑总结成下面 7个步骤:
- Spring的 BeanUtils拷贝,使用的是反射机制
- 先获取target中所有字段以及它们的getter和setter方法
- 遍历target的字段,如果字段有setter方法或者不是忽略对象则进行下一步操作,否则忽略
- 用target的字段去source中获取对应的值(通过getter方法),有值则进行下一步,否则忽略
- 获source和target中同一个字段的类型,并且判断类型是否相同,相同则继续下一步,否则忽略
- 如果source和target的字段是非public,则通过反射修改权限
- 最后,通过反射完成赋值
- 通过源码分析,我们能够看出org.springframework.beans.BeanUtils的拷贝屏蔽了很多的异常,总结如下:
- source和target的字段缺少getter和setter方法,拷贝失败
- source和target的字段名称不同,拷贝失败,即字段名相同才可以拷贝
- source和target的字段类型不同,拷贝失败,即类型相同才可以拷贝
- 对于Map类型,无法拷贝
对于上述前 3种拷贝失败的场景,编译期间无法感知,一旦代码上线大概率会出 bug,另外,因为使用的反射机制,性能略有影响。
2.Apache实现
org.apache.commons.beanutils.BeanUtils的源码实现如下图:
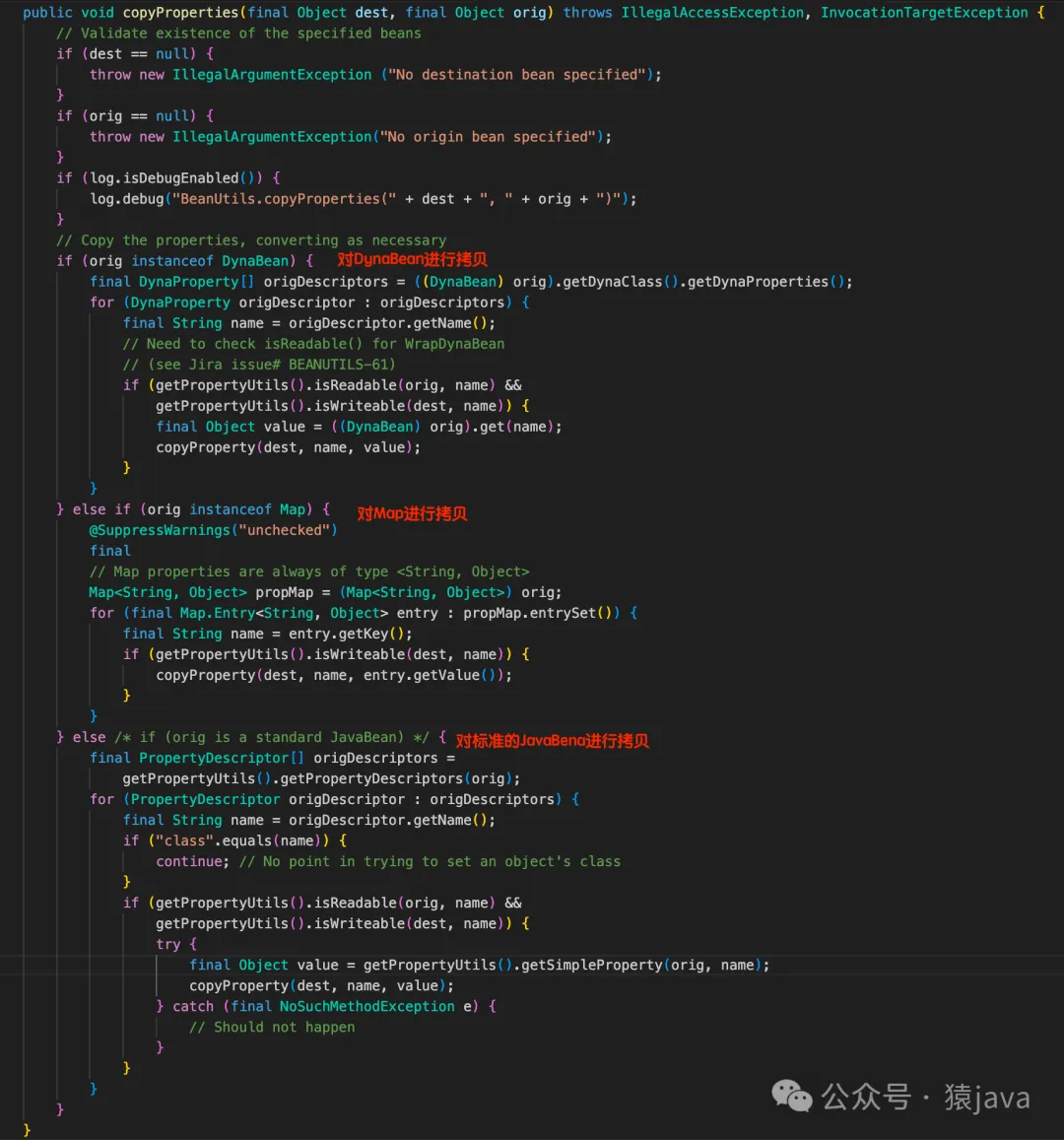
通过源码我们能够看出:Apache的实现其实是对Spring的一种增强,增加了DynaBean和Map两种类型的拷贝,它们的实现都是采用反射机制。
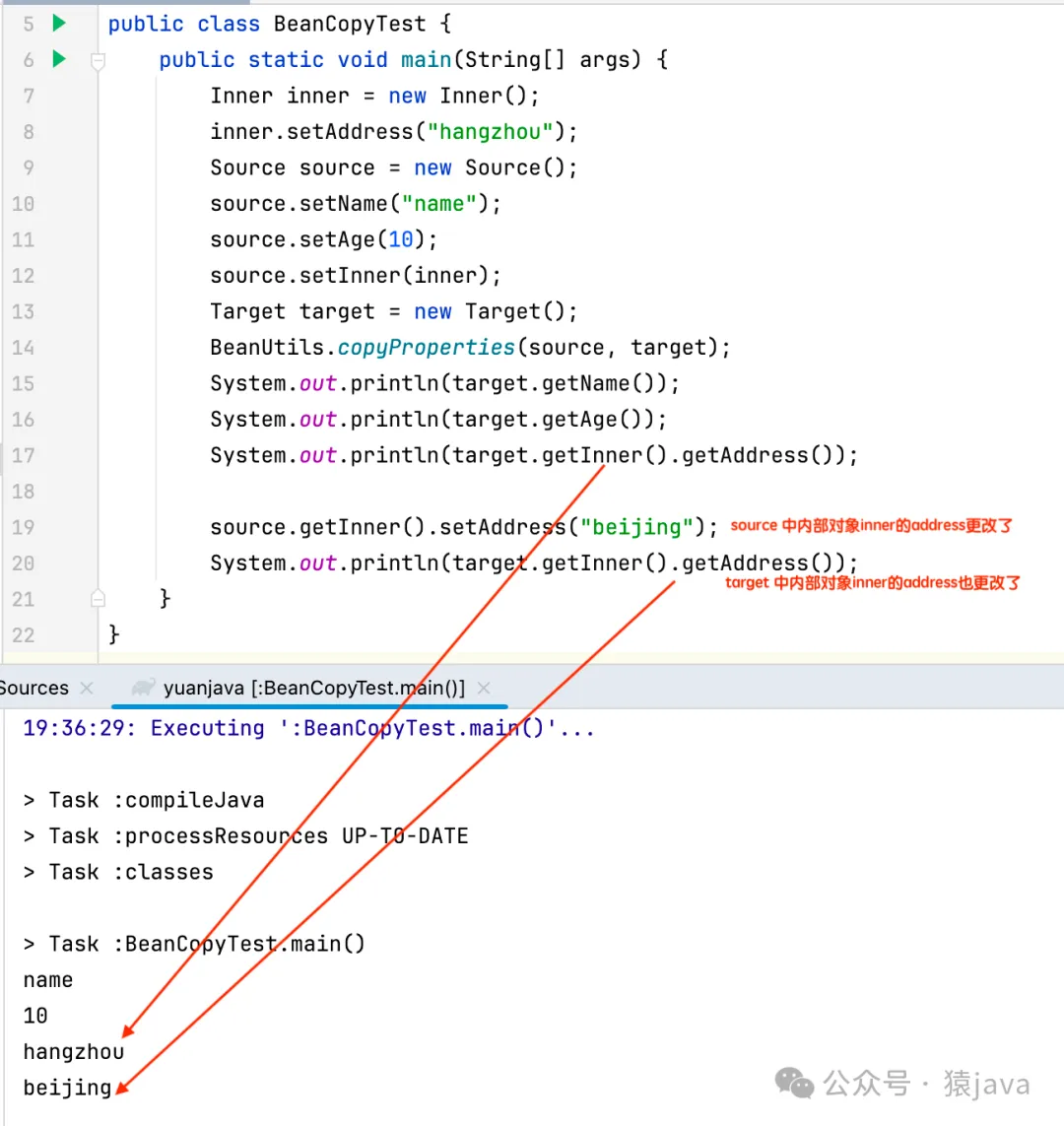
另外,Spring和 Apache的两种实现方案都是浅拷贝,也就是说,如果对象中还有内嵌对象,如果不做额外处理,拷贝会失败。
所谓浅拷贝,浅拷贝是一种复制对象的方式,它创建一个新对象,这个新对象是原对象的副本,但对于对象中引用类型的字段,浅拷贝只复制它们的引用,而不复制它们所指向的实际对象。换句话说,浅拷贝只拷贝对象的第一层属性,对于属性中的引用类型,只拷贝引用地址。
如下示例,当source内部Inner对象的 address字段更改了,target的也跟着变更了:
二、为什么不推荐BeanUtils.copyProperties
在上面源码分析的过程中可以发现:只有同时满足下面 3个条件才能拷贝成功:
- source和target的字段需要有getter和setter方法
- source和target的字段名称需要相同
- source和target的字段类型需要相同
以上 3个条件缺失任何一个拷贝都会失败,但是编译器无法感知,对程序员不友好。
假如,在开发中忘记写getter和setter,使用BeanUtils.copyProperties拷贝不会有异常,但是业务逻辑上没有达到预期,所以这种异常要么在测试中发现,要么需要跑真实的业务逻辑才能发现。
还有一种场景,假如source中有个money字段一开始被程序员A定义成double类型,后面被程序员B 修改成了BigDecimal,程序员B发现代码没有报错,而且是一个小修改就直接上线了。
1天后,有人反馈线上出问题了,经过好一番努力地排查发现,使用BeanUtils.copyProperties拷贝,source中的money字段是BigDecimal类型,而target的money字段是double类型,最终导致拷贝失败,而这位差点被开除的程序员恰好是这种场景。
基于上述描述,BeanUtils.copyProperties无法在编译期间对拷贝字段的修改及时感知错误,假如公司上线规范不严,或者回归测试不全面,一旦出现上述字段名称或者类型被修改,很大可能造成线上问题,所以需要慎用BeanUtils.copyProperties。
三、替代方案
既然BeanUtils.copyProperties拷贝存在上述问题,那么,有没有什么好的替代方案呢?
有,通常替代方案有 2种:使用原始的setter和getter方法 和 MapStruct。
1.原始的setter和getter
使用原始的setter和getter方法进行拷贝,虽然会编写一些看似啰嗦的代码,但是它具备以下优点:
- 控制的粒度更细,更灵活
- 性能比BeanUtils.copyProperties的反射更高效
- 如果拷贝字段有名称和类型更改或者setter和getter方法丢失,编译期立马能发现
- 如下示例,可以将多个Source的字段按需拷贝到Target上:
import java.util.UUID;
public Target convetSourceToTarget(Source1 source1, Source2 source2) {
Target target = new Target();
target.setId(UUID.randomUUID().toString());
target.setName(source1.getName());
target.setAge(source1.getAge());
target.setAddress(source2.getAddress());
}2.MapStruct
(1) 使用示例
MapStruct是一个很优秀的 Java库,也是用于简化对象之间的拷贝工作,其主要特点如下:
- 编译时生成代码:MapStruct在编译时生成映射代码,避免了运行时的性能开销
- 类型安全:生成的代码是类型安全的,编译时即可发现映射错误
- 易于使用:通过注解配置,使用简单直观
为了更好地说明 MapStruct,我们以一个示例进行说明:
首先,我们需要增加mapstruct的依赖:
// maven 依赖
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>1.5.2.Final</version>
</dependency>
// gradle依赖
implementation 'org.mapstruct:mapstruct:1.5.2.Final'然后,定义一个Mapper接口:
import org.mapstruct.Mapper;
import org.mapstruct.Mapping;
import org.mapstruct.factory.Mappers;
@Mapper
public interface TestMapper {
TestMapper INSTANCE = Mappers.getMapper(TestMapper.class);
/**
* 在Mapping中定义对象的 source和 target字段,
* 如果source和 target的类型不一样,编译期会报错
*/
@Mapping(source = "name", target = "fullName")
UserDTO toDTO(UserEntity entity);
}接着,定义两个实体类:
public class UserDTO {
private String fullName;
private int age;
}
public class UserEntity {
private String name;
private int age;
}最后,写一个测试类:
public class MapStructTest {
public static void main(String[] args) {
UserEntity entity = new UserEntity();
entity.setName("John");
entity.setAge(30);
UserDTO dto = TestMapper.INSTANCE.toDTO(entity);
System.out.println(dto.getFullName()); // 输出: John
System.out.println(dto.getAge()); // 输出: 30
}
}上述代码,在编译器会自动创建一个TestMapperImpl实现类,如下图:
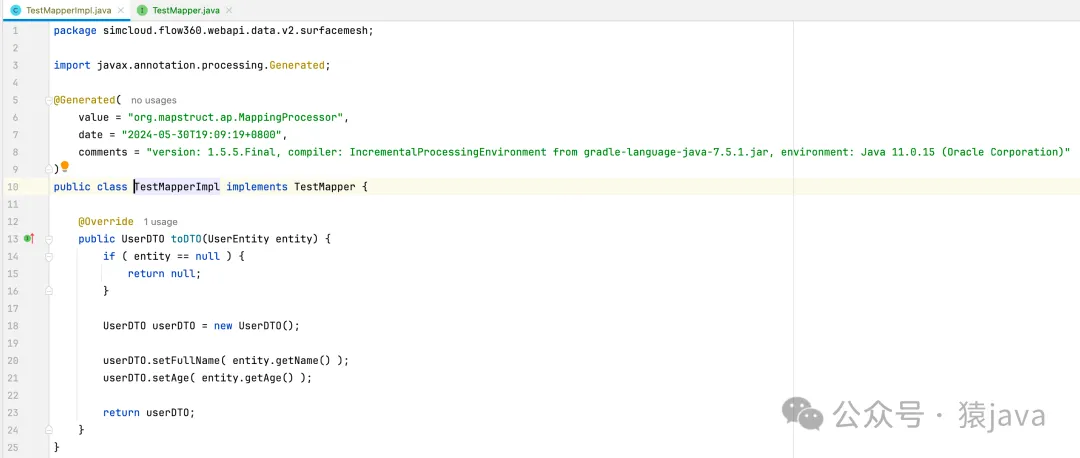
(2) 实现原理
最后,总结下MapStruct实现原理:
① 注解处理器机制
MapStruct使用了 Java的注解处理器机制,通过实现javax.annotation.processing.Processor接口,在编译时扫描和处理特定的注解。
② 注解扫描与处理
MapStruct定义了@Mapper、@Mapping 等注解,编译器会调用注解处理器来处理这些注解。
③ 代码生成
MapStruct会根据注解信息,解析源类和目标类的结构,并生成相应的映射,大致有以下几个步骤:
- 解析注解和类结构:MapStruct 解析@Mapper接口、方法签名以及@Mapping注解,获取源类和目标类的字段信息。
- 生成映射方法:根据解析结果,生成具体的映射方法,并调用源类的getter方法获取值并赋值给目标类的对应字段。
- 处理复杂映射:对于嵌套对象、集合等复杂结构,MapStruct会递归生成相应的映射代码
④ 类型安全与错误检查
在代码生成过程中,MapStruct会进行类型检查,确保源字段和目标字段的类型匹配,如果发现类型不匹配会报编译时错误。
⑤ 支持自定义
MapStruct允许用户自定义映射逻辑,比如下面的示例,通过qualifiedByName和 @Named注解实现了一个自定义的方法:
@Mapping(target = "tags", source = "tagSet", qualifiedByName = "defaultToEmptySet")
UserEntity fromDO(UserDTO dto);
@Named("defaultToEmptySet")
default Set<String> defaultToEmptySet(Set<String> items) {
return items == null ? new LinkedHashSet<>() : items;
}四、如何选择?
原始的setter和getter方法简单且灵活,mapstruct通过注解的方式,比起原始的setter和getter门槛会高一点。
两种方式都是编译行为,因此,一旦拷贝的字段发生改变能及时感知,对程序员比较友好。
具体如何选择,可以根据团队约定而定,如果是个人学习,优先推荐mapstruct,可以作为一个学习和实践点。
五、总结
本文通过分析BeanUtils.copyProperties的源码,总结了它的几个缺点,综合评估,建议慎用!
接着,通过分析mapstruct的原理以及使用案例,它完美解决了BeanUtils.copyProperties的缺点,是对象拷贝很不错的选择。
对于原始的setter和getter也是对象拷贝很不错的选择。
温馨建议:如果使用三方的工具类,一定要事先了解其优缺点和安全性问题,这样才能在使用过程中能做到心中有谱,处事不乱,避免拆盲盒导致不必要的事故。如果有更多的精力,再去研究下其原理,吸收他人优秀的思维。