












在 Transformer 大一统的时代,计算机视觉的 CNN 方向还有研究的必要吗?
今年年初,OpenAI 视频大模型 Sora 带火了 Vision Transformer(ViT)架构。此后,关于 ViT 与传统卷积神经网络(CNN)谁更厉害的争论就没有断过。
近日,一直在社交媒体上活跃的图灵奖得主、Meta 首席科学家 Yann LeCun 也加入了 ViT 与 CNN 之争的讨论。

这件事的起因是 Comma.ai 的 CTO Harald Schäfer 在展示自家最新研究。他(像最近很多 AI 学者一样)cue 了 Yann LeCun 表示,虽然图灵奖大佬认为纯 ViT 并不实用,但我们最近把自己的压缩器改成了纯 ViT,没有卷积,需要更长时间的训练,但是效果非常不错。

比如左图,被压缩到了只有 224 字节,右边是原始图像。
只有 14×128,这对自动驾驶用的世界模型来说作用很大,意味着可以输入大量数据用于训练。在虚拟环境中训练相比真实环境成本更低,在这里 Agent 需要根据策略进行训练才能正常工作。虽然训练更高的分辨率效果会更好,但模拟器就会变得速度很慢,因此目前压缩是必须的。
他的展示引发了 AI 圈的讨论,1X 人工智能副总裁 Eric Jang 回复道,是惊人的结果。
Harald 继续夸赞 ViT:这是非常美丽的架构。
此处有人就开始拱火了:大师如 LeCun,有时也无法赶上创新的步伐。

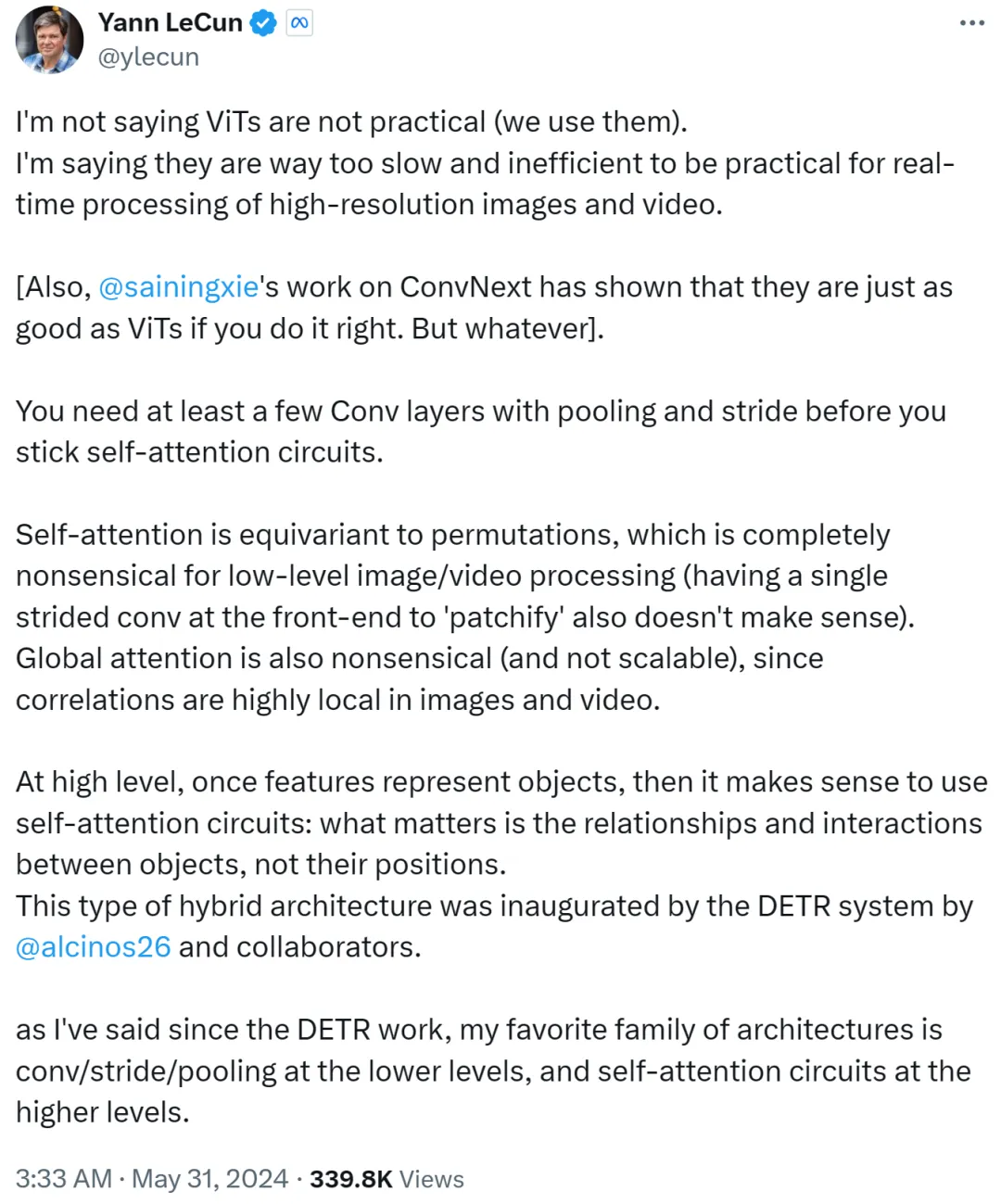
不过,Yann LeCun 很快回复辩驳称,他并不是说 ViT 不实用,现在大家都在使用它。他想表达的是,ViT 太慢、效率太低,导致不适合实时处理高分辨率图像和视频任务。
Yann LeCun 还 Cue 了纽约大学助理教授谢赛宁,后者参与的工作 ConvNext 证明了如果方法得当,CNN 也能和 ViT 一样好。
他接下来表示,在坚持自注意力循环之前,你至少需要几个具有池化和步幅的卷积层。
如果自注意力等同于排列(permutation),则完全对低级别图像或视频处理没有意义,在前端使用单个步幅进行修补(patchify)也没有意义。此外由于图像或视频中的相关性高度集中在局部,因而全局注意力也没有意义且不可扩展。
在更高级别上,一旦特征表征了对象,那么使用自注意力循环就有意义了:重要的是对象之间的关系和交互,而非它们的位置。这种混合架构是由 Meta 研究科学家 Nicolas Carion 及合著者完成的 DETR 系统开创的。
自 DETR 工作出现以后,Yann LeCun 表示自己最喜欢的架构是低级别的卷积 / 步幅 / 池化,以及高级别的自注意力循环。
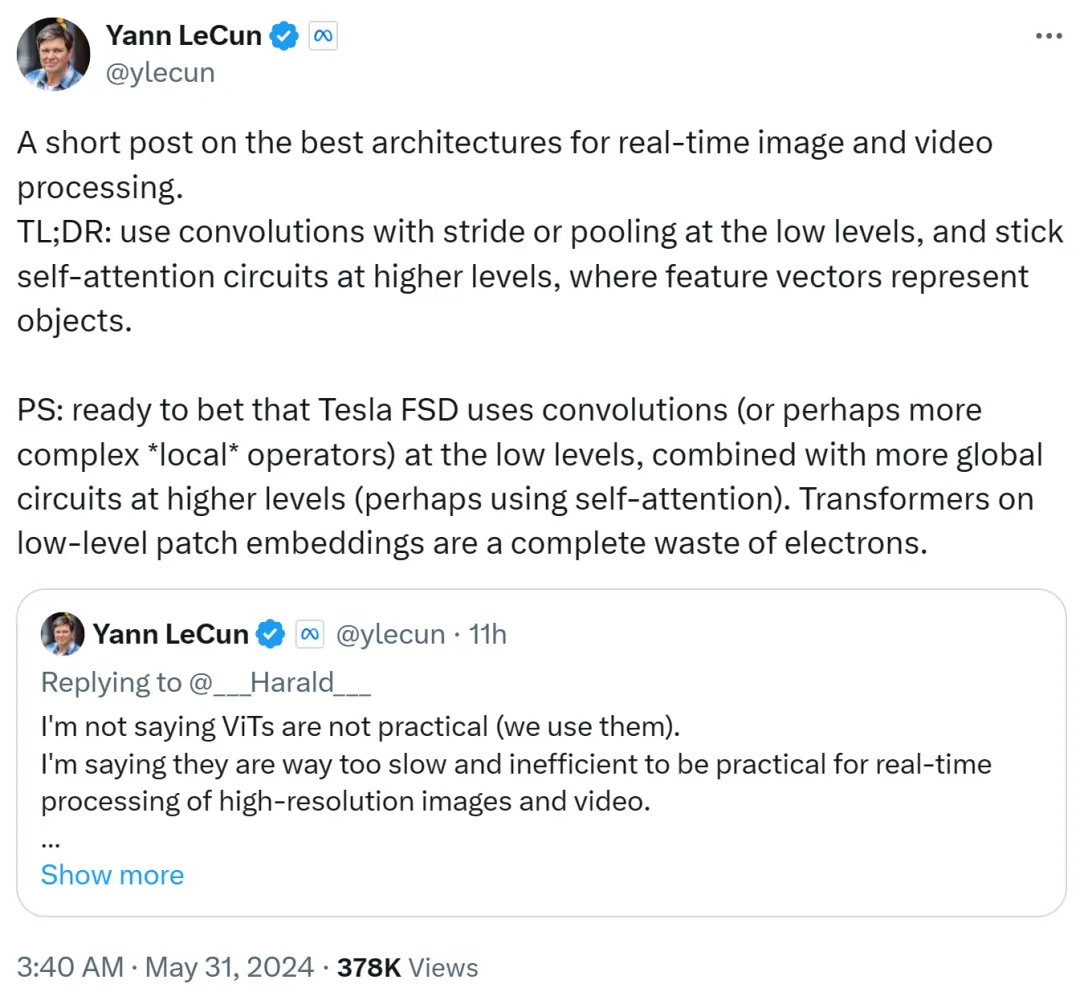
Yann LeCun 在第二个帖子里总结到:在低级别使用带有步幅或池化的卷积,在高级别使用自注意力循环,并使用特征向量来表征对象。
他还打赌到,特斯拉全自动驾驶(FSD)在低级别使用卷积(或者更复杂的局部运算符),并在更高级别结合更多全局循环(可能使用自注意力)。因此,低级别 patch 嵌入上使用 Transformer 完全一种浪费。
我猜死对头马斯克还是用的卷积路线。
谢赛宁也发表了自己的看法,他认为 ViT 非常适合 224x224 的低分辨率图像,但如果图像分辨率达到了 100 万 x100 万,该怎么办呢?这时要么使用卷积,要么使用共享权重对 ViT 进行修补和处理,这在本质上还是卷积。
因此,谢赛宁表示,有那么一刻自己意识到卷积网络不是一种架构,而是一种思维方式。
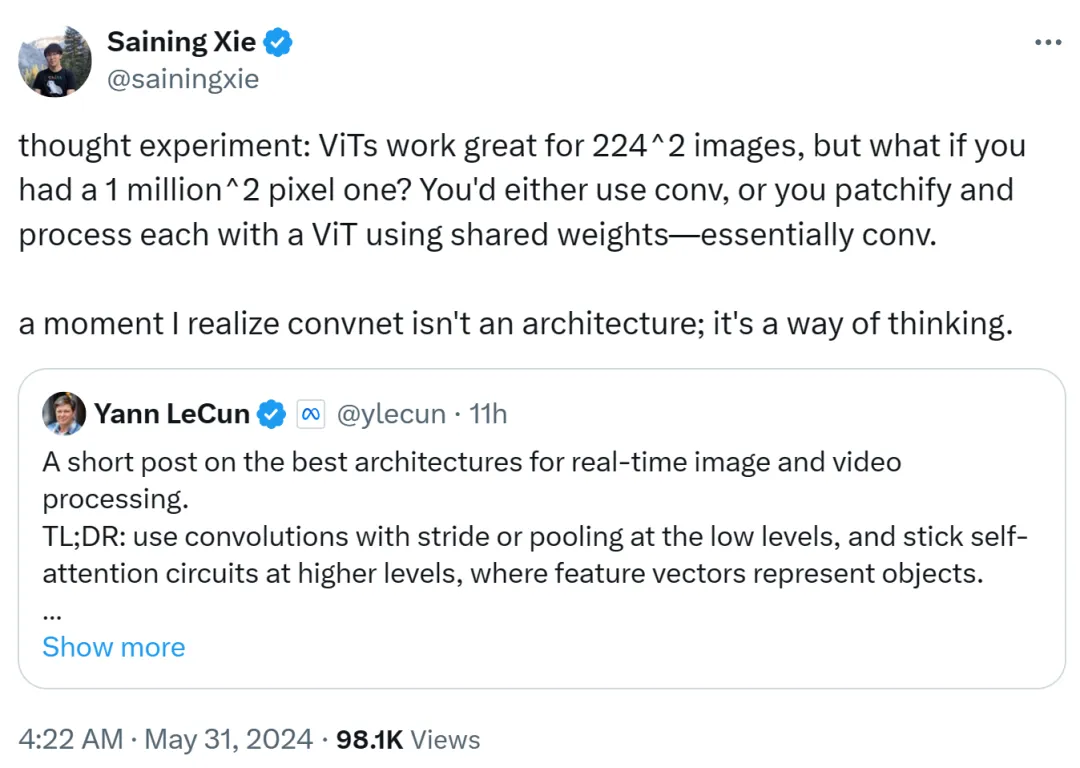
这一观点得到了 Yann LeCun 的认可。

谷歌 DeepMind 研究者 Lucas Beyer 也表示,得益于常规卷积网络的零填充,自己很确定「卷积 ViT」(而不是 ViT + 卷积)会工作得很好。

可以预见,这场 ViT 与 CNN 之间的争论还将继续下去,直到未来另一种更强大架构的出现。



























