













从谷歌离职一年之际,「人工智能教父」Hinton接受了采访。
——也许是因为徒弟Ilya终于被从核设施中放了出来?(狗头)

视频地址:https://www.youtube.com/watch?v=tP-4njhyGvo
当然了,采访教父的小伙子也非等闲之辈,Joel Hellermark创立的Sana已经融资超过8000万美元,
他本人也曾因为在推进AI方面的工作,而入选福布斯30 under 30(30位30岁以下精英)。最近,《卫报》又将Joel评为35岁以下改变世界的前10名。
——这个13岁学编程、16岁开公司的小天才,与真正的科学家之间,又能碰撞出怎样的火花呢?

下面,让我们跟随两人的对话,一同探寻AI教父的心路历程,以及幼年Ilya的一些趣事。
剑桥白学了
为了弄清楚人类的大脑如何工作,年轻的教父首先来到剑桥,学习了生理学,而后又转向哲学,但最终也没有得到想要的答案。
「That was extremely disappointing」。
于是,Hinton去了爱丁堡,开始研究AI,通过模拟事物的运行,来测试理论。
你在爱丁堡时候的直觉是什么?
「在我看来,必须有一种大脑学习的方式,显然不是通过将各种事物编程到大脑中,然后使用逻辑推理。我们必须弄清楚大脑如何学会修改神经网络中的连接,以便它可以做复杂的事情。」
「我总是受到关于大脑工作原理的启发:有一堆神经元,它们执行相对简单的操作,它们是非线性的,它们收集输入,进行加权,然后根据加权输入给出输出。问题是,如何改变这些权重以使整个事情做得很好?」
Ilya:我不想炸薯条了
某个星期日,Hinton坐在办公室,突然有人在外面哐哐敲门(原话:that's sort of an urgent knock)。
Hinton去开门,门外的年轻人正是Ilya。

Ilya:这个夏天我在炸薯条,实在是干够了,还不如来你实验室干活。
Hinton:你应该先预约,然后我们谈一下。
Ilya:就现在怎么样?
——Hinton表示,这就是Ilya的性格特点。
Hinton给了Ilya一篇关于反向传播的论文,两人于一周后再次见面。
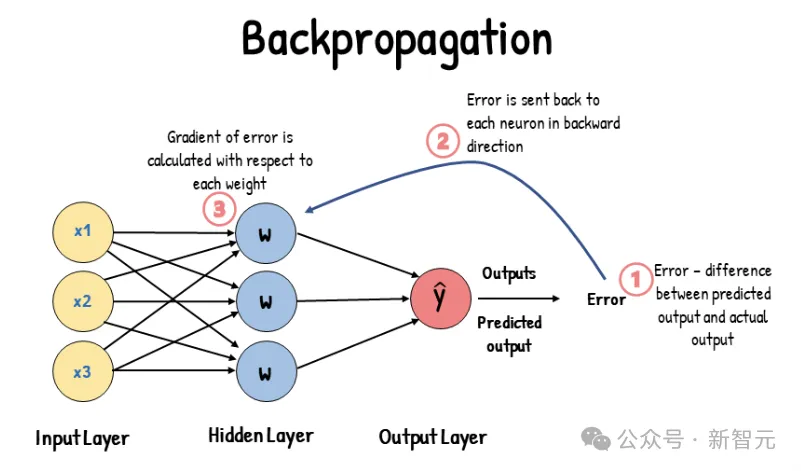
Ilya:I didn't understand it.
Hinton:?这不就是链式法则吗,小伙子你怎么回事?
Ilya:不是那个,我不明白你为啥不用个更好的优化器来处理梯度?
——Hinton的眼睛亮了一下,这是他们花了好几年时间在思考的问题。

Hinton表示,Ilya总是有很好的直觉,他从小就对人工智能感兴趣,并且显然很擅长数学。
Hinton还记得,有一次的项目比较复杂,涉及到大量的代码重组,以进行正确的矩阵乘法。
Ilya受够了折磨,于是有一天跑过来找Hinton,
Ilya:我要为Matlab写一个接口,自动做这些转换。
Hinton:不行,Ilya,那需要你一个月的时间。我们必须继续这个项目,不要分散注意力。
Ilya:没关系,我今天早上写完了。
Ilya的直觉
Ilya很早就有一种直觉:只要把神经网络模型做大一点,就会得到更好的效果。Hinton认为这是一种逃避,必须有新的想法或者算法才行。
但事实证明,Ilya是对的。
新的想法确实重要,比如像Transformer这样的新架构。但实际上,当今AI的发展主要源于数据的规模和计算的规模。
或许正是因为Ilya的这种直觉,才有了后来OpenAI的惊人成就。

当时过境迁、沧海桑田,光阴让Ilya变为了成熟的大人,同时也带走了他的头发。
模型真的能思考
2011年,Hinton带领Ilya和另一名研究生James Martins,发表了一篇字符级预测的论文。他们使用维基百科训练模型,尝试预测下一个HTML字符。
模型首次采用了嵌入(embedding)和反向传播,将每个符号转换为嵌入,然后让嵌入相互作用以预测下一个符号的嵌入,并通过反向传播来学习数据的三元组。
当时的人们不相信模型能够理解任何东西,但实验结果令人震惊,就像是模型已经学会了思考。

预测下一个符号,与传统的自动完成功能有很大的不同。传统的自动完成功能会存储一组三元组单词。然后,你会看到不同的单词出现在第三位的频率,这样你就可以进行预测。
但现在,情况已经不同了。要预测下一个符号,你必须理解所说的内容。我认为通过预测下一个符号可以强迫模型进行理解,它的理解方式与我们非常相似。
举个例子,如果你问GPT-4,为什么堆肥堆像原子弹?大多数人都无法回答这个问题,因为他们认为原子弹和堆肥堆是完全不同的东西。
但GPT-4会告诉你,两者能量尺度不同,时间尺度也不同。但相同的是,当堆肥堆变热时,它会更快地产生热量;而当原子弹产生更多的中子时,其产生中子的速度也会随之加快。
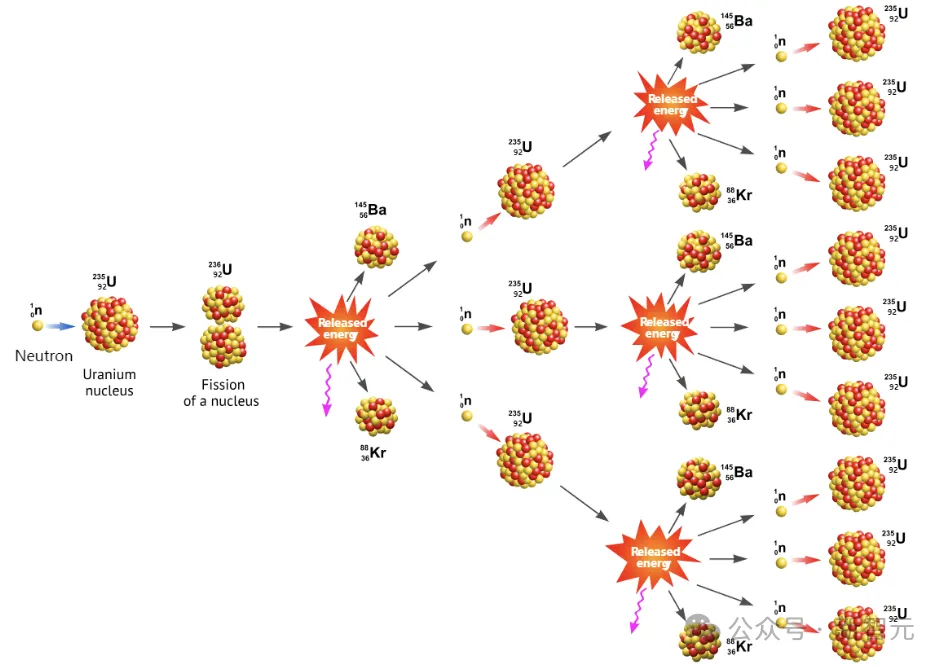
——这就引出了链式反应的概念。通过这种理解,所有的信息都被压缩到模型权重中。
在这种情况下,模型将能够对我们从未见过的各种类比进行处理,这就是人类能从模型中获得创造力的地方。
大型语言模型所做的是寻找共同的结构,使用共同的结构对事物进行编码,这样效率更高。
超越训练数据
在与李世石的那场著名比赛中,AlphaGo在第37步做出了所有专家都认为是错误的举动,——但后来被证明是AI绝妙的创造力。

AlphaGo的不同之处在于它使用了强化学习,使它能够超越当前状态。它从模仿学习开始,观察人类如何玩游戏,然后通过自我对弈,逐渐超越了训练数据。
Hinton还举了训练神经网络识别手写数字的例子,他把训练数据的一半答案故意替换成错误的(误差率50%),但是通过反向传播的训练,最终模型的误差率会降到5%或更低。
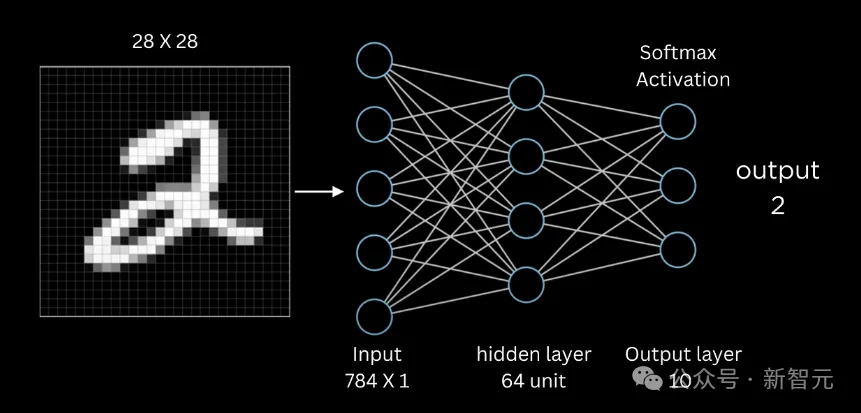
这就像是聪明的学生最终会超过自己的老师。大型神经网络实际上具有超越训练数据的能力,这是大多数人未曾意识到的。
此外,Hinton认为当今的多模态模型将带来很大的改变。
仅从语言角度来看,模型很难理解一些空间事物。但是,当模型成为多模态时(既能接收视觉信息,又能伸手抓东西,能拿起物体并翻转),它就会更好地理解物体。多模态模型需要更少的语言,学习起来会更容易。
预测下一个视频帧、预测下一个声音,我们的大脑或许就是这样学习的。
英伟达不送GPU
Hinton是最早使用GPU处理神经网络计算的人之一。
2006年,一位研究生建议Hinton使用GPU来计算矩阵乘法。他们最开始使用游戏GPU,发现运算速度提高了30倍。之后Hinton购买了一个配备四个GPU的Tesla系统。
2009年,Hinton在NIPS会议上发表了演讲,告诉在场的一千名机器学习研究人员:「你们都应该去购买英伟达的GPU,这将是未来的趋势,你们需要GPU来进行机器学习。」
然后,Hinton给英伟达发了一封邮件,说我已经告诉一千名机器学习研究人员去购买你们的显卡,你们能否免费给我一个?
——英伟达并没有回复。
很久以后,Hinton把这个故事告诉老黄,老黄赶紧送了一个。

硬件模拟神经网络
在谷歌的最后几年里,Hinton一直在思考如何尝试进行模拟计算。这样,我们就可以使用跟大脑一样的功率(30瓦),来运行大型语言模型,而不是一兆瓦的功率。
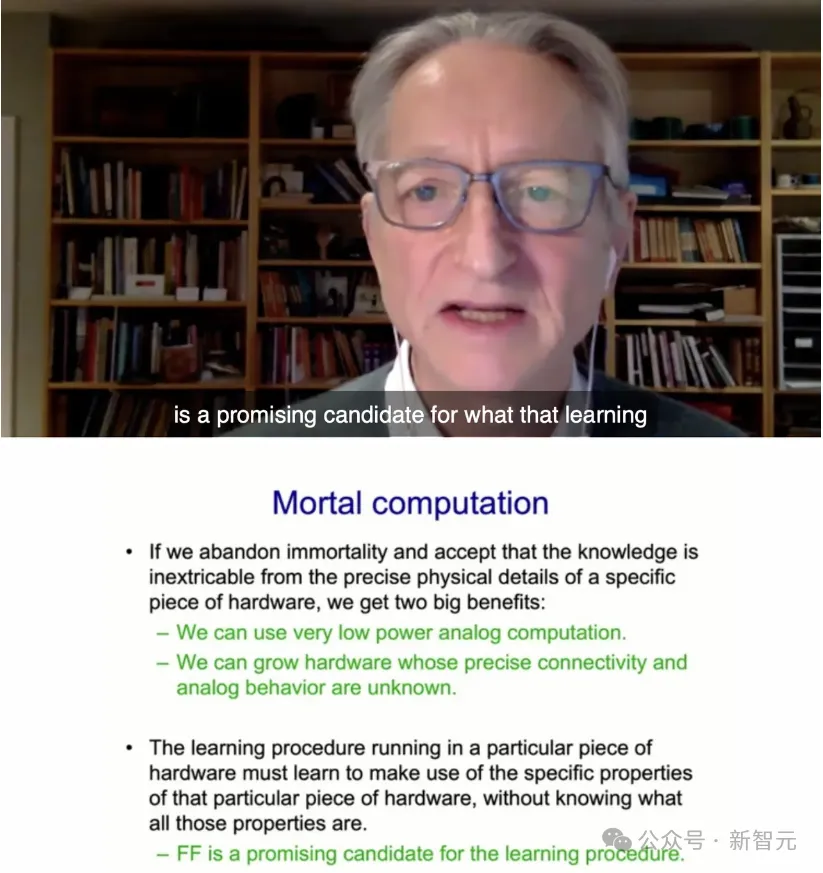
每个人的大脑都不相同,所以在这种低功耗的模拟计算中,每个硬件都会有所不同,各个神经元的精确属性也不同。
人终有一死,大脑中的权重在人死后就会丢失,但数字系统是不朽的,权重可以被存储起来,计算机坏了也不影响。
假设有一大批数字系统,它们从相同的权重开始,各自进行微量的学习,然后共享权重,这样它们都能知道其他系统学到了什么。然而,我们人类无法做到这一点,因此在知识共享方面,数字系统远胜于我们。
快速权重
到目前为止,神经网络模型都只有两个时间尺度:接收输入时的快速变化,和调整权重时的缓慢变化。
然而在大脑中,权重的时间尺度有很多。
比如我说了一个词「黄瓜」,五分钟后,你戴上耳机,听到很多噪音和一些模糊的单词,但你能更好地识别「黄瓜」这个词,因为我五分钟前说过这个词。
大脑中的这些知识是如何存储的呢?显然是突触的暂时变化,而不是神经元在重复「黄瓜」这个词——Hinton称之为快速权重。
Hinton的担忧
Hinton认为,科学家应该做一些有助于社会的事情,当你被好奇心驱使时,你会做最好的研究。但是,这些事情会带来很多好处,也可能会造成很多伤害,我们需要关注它们对社会的影响。
比如坏人使用AI做坏事,将人工智能用于杀手机器人,操纵公众舆论或进行大规模监视。这些都是非常令人担忧的事情。
而人工智能领域的发展不太可能放缓,因为是它是国际性的,即使一个国家放缓,其他国家也不会。
这种担忧也让小编想起了与Hinton一脉相承的Ilya。
从多伦多的实验室,到OpenAI的核设施,Ilya一直牢记恩师的教诲:道路千万条,安全第一条。监管不规范,教父两行泪。






















