大家好,我是你们的老朋友小米!今天我们来聊一聊分布式系统中的一个重要话题——日志复制。这可是保证系统高可用性和数据一致性的关键技术哦~
1.前言
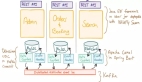
在分布式系统中,为了保证数据的一致性和系统的容错性,我们常常会将数据复制到多个服务器上。而其中一种常见的方法就是日志复制。无论是Raft一致性算法还是Paxos协议,日志复制都是核心的操作。今天,我们就以Raft算法为例,详细探讨一下日志复制的工作流程。
 图片
图片
2.Leader是如何添加指令到日志中的?
在Raft算法中,集群中的服务器分为三种角色:Leader、Follower和Candidate。在正常运行时,只有一个Leader,其他服务器都是Follower。Leader负责接收客户端的请求并将这些请求复制到其他Follower的日志中。
当Leader收到一个客户端的请求(例如要更新某个数据),它会先将这个请求添加到自己的日志中。这个过程可以简单理解为Leader在自己的笔记本上记了一笔账。记账完成后,Leader就要通知其他的服务器了。
3.RPC,消息的传递者
为了保证所有服务器上的日志都是一致的,Leader需要将刚才记下的那笔账复制到所有Follower的日志中。这个过程是通过RPC(远程过程调用)来实现的。Leader会向每一个Follower发送一个RPC请求,告诉他们“我要加一条日志,你们也要加上哦!”。
具体流程如下:
Leader发起RPC请求:Leader把刚添加到日志中的指令封装成一个RPC请求,发送给所有的Follower。
Follower接收并处理请求:Follower收到请求后,会将这条指令添加到自己的日志中,并返回一个ACK(确认响应)给Leader,表示自己已经接收到并记录了这条日志。
Leader等待ACK:Leader会等待所有Follower的ACK,以确保所有的Follower都接收到并记录了这条日志。
4.Leader的重试机制
在实际的网络环境中,由于网络延迟或者其他故障,Follower可能会没有及时响应Leader的RPC请求。这时,Leader并不会放弃,而是会不断地重试,直到收到所有Follower的ACK为止。
重试机制的具体实现
Leader在发送RPC请求后,会启动一个定时器。如果在规定的时间内没有收到某个Follower的ACK,Leader就会再次发送这个请求,直到这个Follower响应为止。这种重试机制保证了即使某些Follower暂时不可用,当它们恢复后,仍然能够接收到所有的日志条目,从而保持日志的一致性。
5.提交日志,最终一致性的保证
当Leader收到了所有Follower的ACK后,就意味着这条日志已经被复制到了集群中的大多数服务器上(通常是超过半数的服务器)。这时,Leader就可以认为这条日志是“安全”的,可以提交了。
通知Follower提交日志
Leader会向所有Follower发送一个“提交”消息,告诉他们可以提交这条日志了。提交日志的意思是将这条日志中的指令应用到服务器的状态机中(比如更新数据库中的某个数据)。
更新日志状态
Leader在提交日志后,会更新这条日志的状态,标记为“已提交”。然后,Leader会将操作的结果返回给客户端。
整个流程总结
客户端请求:客户端向Leader发送一个请求。
Leader添加日志:Leader将请求添加到自己的日志中。
Leader发起RPC:Leader向所有Follower发送RPC请求,复制日志。
Follower响应ACK:Follower接收并记录日志,返回ACK给Leader。
Leader重试:Leader在未收到所有Follower的ACK前,不断重试。
Leader提交日志:收到所有Follower的ACK后,Leader提交日志并通知Follower提交。
Leader返回结果:Leader将操作结果返回给客户端。
6.日志复制中的挑战
虽然日志复制看起来流程很简单,但在实际应用中会遇到很多挑战。
网络分区
在分布式系统中,网络分区是不可避免的。当网络分区发生时,集群可能会被分割成两个或多个部分,部分服务器之间无法通信。此时,Leader可能无法收到所有Follower的ACK,导致日志无法提交。
解决网络分区的问题通常有两种方法:
- 超时机制:Leader在等待ACK时设置一个超时时间,如果超时未收到ACK,则认为Follower不可用,进行重试。
- 领导选举:如果Leader认为自己与大多数Follower失去了联系,会触发领导选举,选出新的Leader。
日志一致性
在分布式系统中,确保所有服务器的日志一致性是一个重要挑战。任何一个服务器的日志与其他服务器不一致,都会导致系统状态的不一致。
为了保证日志一致性,Raft算法采用了以下几种策略:
- 强制日志匹配:当一个Follower的日志与Leader的日志不一致时,Leader会强制Follower与自己保持一致,丢弃Follower多余的日志条目。
- 日志压缩:为了防止日志无限增长,系统会定期进行日志压缩,删除已经提交并应用到状态机的日志条目。
END
日志复制是分布式系统中保证数据一致性和系统高可用性的核心技术。通过Leader发起RPC请求,Follower响应ACK,Leader重试机制以及最终提交日志,保证了系统在面对各种网络故障和服务器故障时,仍能保持一致性和高可用性。
希望今天的分享能让大家对日志复制有一个更深入的理解。