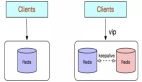
在工作中Redis已经成为必备的一款高性能的缓存数据库,但是在实际的使用过程中,我们常常会遇到两个常见的问题,也就是文章标题所说的大 key与热 key。

一、定义
1.什么是大key
大 key 指的是一个键中包含了大量的数据。(总结一个字就是大)
- 占用空间:大key 通常指的是一个键包含了大量的数据,使得该键对应值的占用的内存超出了正常范围。这个大小的阈值并不是固定的,而是相对于 Redis 实例的可用内存而言。当一个键的大小超出了 Redis 实例可用内存时,就可以认为它是一个大key。
- 操作耗时:如果对一个 key 的操作所需的时间过长,导致性能下降或者影响其他请求的处理速度,也可以说这个 key 是 大key 。因为这种情况通常是由于该 key 下包含了大量的数据。
2.什么是热key
热 key 指的是频繁访问的键。(总结就是热,访问频繁。)
- 频繁访问:在某一段时间内被频繁访问的 key 就是 热key 。
- 业务方面:比如商城促销的场景下,某个商品的缓存可能就会成为 热key。这种情况下 热key 反应的不仅是该键的访问频率高,还反映了用户对某个业务功能的热度。
- 性能方面:热key 的频繁访问造成 Redis 的 CPU 占用率过高,造成响应时间延长或者请求阻塞,从而造成系统崩溃。
key 的大与不大,热与不热要根据自己的业务,从实际情况进行评估。
二、影响
1.大 key 的影响
- 内存消耗:在进行缓存时降低缓存的效率,占用大量的内存空间,使得 Redis 的内存消耗急剧增加,还可能导致 Redis 实例的内存资源不足,甚至出发内存淘汰策略,从而影响系统的正常运行。
- 性能下降:处理大的 key,会耗费更多的 CPU 时间以及带宽,导致 Redis 性能下降。由于 Redis 还是单线程的,处理 大key 的操作进而会阻塞其他请求的处理,从而影响系统性能。
- 持久化效率降低:在进行持久化操作时,AOF与RDB都会因为该 大key 耗费更多的时间,从而延迟持久化时间,分布式环境下甚至会造成缓存不一致。
- 网络传输延迟:大key 在进行网络传输时会增加网络传输的延迟,在分布式环境下进行数据同步时可能会造成数据的不一致。
2.热 key 的影响
- CPU占用率高:因为是 热key,所以 CPU 一直占用,进而导致Redis实例的CPU负载增加。
- 请求阻塞:如果 key 有访问优先级,热key 的存在可能导致请求队列中其他的请求被阻塞。
- 响应时间延长:因为 热key ,其他的请求被阻塞了造成响应时间延长。
- 性能不均衡:流量访问造成突刺,系统性能的不均衡。
3.小结
大key 与 热key 都会给 Redis 实例造成一系列的影响,如内存占用过高,CPU 负载增加,持久化时间变长,性能下降等。
三、原因分析
1.大 key 产生的原因
产生 大key 的原因有很多种,下面咱就一起看一下工作中经常遇到的这几种。
(1) 存储大量数据
存储了大量数据也是我们经常遇到 大key 的最多的原因了。
比如 String 类型直接保存了一个大的文本或者二进制数据;Hash 结构中存储大量的键值对。
- String
- Hash
(2) 缓存时间设置不合理
缓存时间设置不合理这个造成 大key 的原因大概是个隐藏挺深的老 bug,有的业务场景,使用 Redis 缓存数据,业务是定时往该 key 上写数据,由于该 key 是没有设置缓存时间的造成这个 key 随着时间的流逝,占用的内存越来越多,对于该点,只需要设置一个合理的过期时间即可。
前提是多次写入不是覆盖,而是追加才会有该问题。
(3) 数据结构使用不当
在使用 List 数据结构存储数据时,重复的添加数据,造成该 key 越来越大,实际上业务是不需要有重复的数据存在的。
List
(4) 小结
大key 的产生根本原因就是在一个 key 下面存储的数据多了。
2.热 key 产生的原因
(1) 热门数据
热key 的产生一般意味着系统访问火爆了,但是火爆的只是其中一个点或者n个点。类似微博中某个明星的瓜,当上头条的时候,大量的人去访问,造成了该明星所对应的 key 成为 热key。
(2) 频繁的更新
某些业务场景,单位时间内一直频繁的对 key 进行更新,该 key 也会成为 热key。
(3) 热门搜索
类似于第一中的热门数据,产生了热门数据,该数据对应的热门关键词也被大量的用户去搜索,造成该关键词被频繁访问,最终导致该 key 也称为 热key。
(4) 小结
热key 的产生无外乎热门数据,热门数据产生的热门关键词以及对同一个 key 在某段时间内的频繁访问。
四、解决方案
1.大key的解决方案
- 合理的数据结构
- 合理的缓存时间
- 大key 进行拆分为多个 小key
- 定期对 大key 进行清理
2.热key的解决方案
- 合理的缓存淘汰策略
- 热点数据分片:将热点数据分散到不同的Redis实例,提升系统的吞吐量。
- 缓存预热:在系统启动或者活动高峰开启之前进行缓存预热,提前将需要的数据加载到缓存,减少热点数据首次访问的时间。
- 随机缓存失效时间:避免大量的key同一时间批量失效,造成缓存雪崩与缓存穿透。
- 缓存穿透:使用布隆过滤器进行缓存请求过滤,防止无效请求进入到缓存层。
五、总结
针对 大key 我们要尽可能的避免同一个 key 下大量的数据。针对 热key 我们要合理设置过期时间,增加布隆过滤器等技术实现无效请求过滤,对即将到来的数据进行缓存预热、热点数据分片处理。