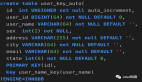
之前无意间看到群友讨论到用什么做主键比较好
 图片
图片
 图片
图片
 图片
图片
其实 UUID 和自增主键 ID 是常用于数据库主键的两种方式,各自具有独特的优缺点。
UUID
UUID 是一个由 128 位组成的唯一标识符,通常以字符串形式表示。它可以通过不同的算法生成,例如基于时间戳的 UUID(version 1)和基于随机数的 UUID(version 4)等。
UUID 的优点
- 全局唯一性:通过不同算法生成,几乎能够保证在全球范围内的唯一性,从而避免了多台机器之间可能发生的主键冲突问题。
- 不可预测性:随机生成的 UUID 很难被猜测,因此在需要保密性的应用场景下非常适用。
- 分布式应用:由于可以在不同的机器上生成 UUID,因此可以被广泛应用于分布式系统中。
然而,UUID 作为主键 ID 也存在一些缺点:
- 存储空间较大:UUID 通常以字符串形式存储,占用的存储空间较大。
- 不适合范围查询:由于不是自增的,不支持范围查询。新生成的 UUID 可能会插入到已有数据的中间位置,导致范围查询时出现数据重复或漏数据的情况。
- 不方便展示:UUID 通常比较长,且没有明确的业务含义,因此不太适合在系统间或前台页面进行展示。
- 查询效率低下:
在 UUID 列上创建索引会导致索引大小增加,从而影响缓存命中率,增加磁盘 I/O 需求,同时也增加了查询时的内存开销。
当使用 UUID 进行排序时,新生成的 UUID 通常会插入到叶子节点的中间位置,导致 B+树的频繁分裂和平衡操作,进而影响查询性能。
自增 ID
在 MySQL 中,可以通过设置 AUTO_INCREMENT 属性实现 ID 的自增长,通常用于作为主键 ID。
使用自增 ID 作为主键的好处包括:
- 存储空间节省:ID 为数字,占用的位数比 UUID 小得多,因此在存储空间上更加节省。
- 查询效率高:ID 递增,利于 B+Tree 索引的查询效率提高。
- 方便展示:ID 较短,方便在系统间或前台页面进行展示。
- 分页方便:ID 连续自增,有利于解决深度分页问题。
然而,使用自增主键也存在一些问题:
- 分库分表困难:在分库分表时,无法依赖单一表的自增主键,可能导致冲突问题。
- 可预测性:由于 ID 是顺序自增的,因此具有一定可预测性,存在一定的安全风险。
- 可能用尽:自增 ID 可能是 int、bigint 等,但它们都有范围限制,可能会用尽。
- 性能问题:在数据迁移期间,如果使用自增主键,数据库可能会产生额外的性能开销。这可能是由于重新计算主键值或更新相关索引所致。这可能会导致数据迁移过程变慢。
到底什么是 UUID,它能保证唯一吗?
UUID(Universally Unique Identifier)是一种全局唯一标识符,用于在同一时空中的各台机器上保证唯一性。
UUID 的生成基于特定算法,通常使用随机数生成器或基于时间戳的方式。生成的 UUID 以 32 位 16 进制数表示,总共 128 位(标准 UUID 格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx,共 32 个字符)。
由于 UUID 是由 MAC 地址、时间戳、随机数等信息生成的,因此具有极高的唯一性,几乎不可能重复。但在实际实现中,UUID 有多种版本,它们的唯一性指标也有所不同。
UUID 的具体实现版本包括基于时间的 UUID V1 和基于随机数的 UUID V4 等。
在 Java 中,java.util.UUID生成的 UUID 包括 V3 和 V4 两种版本。
 图片
图片
UUID 的优缺点
UUID 的优点在于其性能较高,不依赖网络,可以在本地生成,并且使用起来相对简单。
然而,UUID 也存在两个明显的缺点:
- 长度过长:UUID 通常由 32 位 16 进制数字组成,因此长度较长。例如,对于类似"550e8400-e29b-41d4-a716-446655440000"的字符串,几乎没有任何程序员能够直观理解其含义。
- 缺乏含义:UUID 是随机生成的,因此缺乏任何业务或语义上的含义。一旦将其用作全局唯一标识,可能导致在日后的问题排查和开发调试过程中遇到较大困难。
各个版本实现
- V1. 基于时间戳的 UUID
基于时间戳的 UUID 是通过计算当前时间戳、随机数和机器 MAC 地址得到的。由于算法中使用了 MAC 地址,这个版本的 UUID 能够确保在全球范围内的唯一性。然而,使用 MAC 地址也带来了安全性问题,因此这个版本的 UUID 受到了批评。如果应用只在局域网中使用,也可以使用一种简化的算法,以 IP 地址代替 MAC 地址。
- V2. DCE(Distributed Computing Environment)安全的 UUID
这个版本的 UUID 算法与基于时间戳的 UUID 相同,但会将时间戳的前 4 位替换为 POSIX 的 UID 或 GID。然而,实际中较少使用这个版本的 UUID。
- V3. 基于名称空间的 UUID(MD5)
基于名称空间的 UUID 通过计算名称和名称空间的 MD5 散列值得到。这个版本的 UUID 保证了以下几点:在相同名称空间中,不同名称生成的 UUID 具有唯一性;不同名称空间中的 UUID 是唯一的;在相同名称空间中,相同名称生成的 UUID 是重复的。
- V4. 基于随机数的 UUID
基于随机数的 UUID 是根据随机数或伪随机数生成的。该版本的 UUID 使用随机数生成器生成,保证了生成的 UUID 具有极佳的唯一性。然而,由于其基于随机数,因此不太适用于数据量特别大的场景。
- V5. 基于名称空间的 UUID(SHA1)
与版本 3 的 UUID 算法相似,但使用 SHA1(Secure Hash Algorithm 1)算法进行散列值计算。
各版本 UUID 简要总结如下:
Version 1 和 Version 2:
- 基于时间戳和 MAC 地址,适合分布式计算环境,具有高度唯一性。
Version 3 和 Version 5:
- 基于名称空间,在一定范围内是唯一的,可用于生成重复 UUID 的场景。
Version 4:
- 简单地基于随机数生成,适合数据量不是特别大的场景,但可靠性较低。