环境:SpringBoot3.3.0
1. 简介
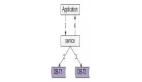
多租户表示应用程序的单个运行实例同时为多个客户机(租户)服务的体系结构。这在SaaS解决方案中非常常见。在这些系统中,隔离与各种租户相关的信息(数据、定制等)是一个特殊的挑战。这包括存储在数据库中的每个租户拥有的数据。以下是三种常用的多租户架构实现方案:
1.1 独立数据库(Separate database)
 图片
图片
每个租户的数据都保存在一个物理上独立的数据库实例中。JDBC连接将专门指向每个数据库,因此任何池都将按租户进行。这里,一种通用的应用程序方法是为每个租户定义JDBC连接池,并根据与当前登录用户相关联的租户标识符来选择要使用的池。
优点:
- 数据隔离级别高,安全性好
- 可以根据租户的需求进行数据库优化和扩展
- 备份和恢复操作相对简单
缺点:
- 成本较高,需要为每个租户购买和维护独立的数据库实例
- 可能存在硬件资源浪费,因为每个租户可能只使用了数据库的一部分功能
1.2 独立Schema(Separate schema)

每个租户的数据都保存在单个数据库实例上的不同数据库Schema中。这里有两种不同的定义JDBC连接的方法:
- 连接可以特定地指向每个Schema,就像单独的数据库方法中那样。这是一个选项,前提是驱动程序支持在连接URL中命名默认Schema,或者池机制支持命名用于其连接的Schema。使用这种方法,我们将为每个租户创建一个不同的JDBC连接池,使用的连接池将基于与当前登录用户相关联的“租户标识符”进行选择。
- 连接可以指向数据库本身(使用某些默认Schema),但使用SQL SET schema(或类似的)命令可以更改连接。使用这种方法,我们将有一个JDBC连接池用于为所有租户提供服务,但在使用连接之前,它将被更改为引用由与当前登录用户关联的“租户标识符”命名的模式。
优点:
- 降低了数据库成本,因为多个租户共享一个数据库实例
- 数据隔离级别仍然较高,因为每个租户使用独立的模式
缺点:
- 模式之间可能存在资源竞争和性能瓶颈
- 备份和恢复操作可能更加复杂,因为需要针对每个模式进行单独操作
1.3 分区数据(Partitioned (discriminator) data)

所有数据都保存在一个数据库Schema中。通过使用分区列对每个租户的数据进行分区。这种方法将使用单个连接池为所有租户提供服务。但是,在这种方法中,应用程序需要对每个SQL语句添加分区列(查询时where条件加入分区列作为查询条件)。
优点:
- 成本最低,因为所有租户都共享同一个数据库实例和模式
- 数据访问和查询效率可能较高,因为数据都在同一个表中
缺点:
- 数据隔离级别最低,可能存在安全风险
- 需要通过应用程序逻辑来确保数据的正确隔离和访问控制
- 数据备份和恢复操作可能非常复杂,因为需要考虑到所有租户的数据
接下来我会对分区数据和独立数据库2种架构进行详细的介绍。独立Schema方案其实与独立数据库模式挺像的,如果基于MySQL其实对应的就是不同数据库(可以是同一个MySQL实例,通过use xxx切换数据库),基于Oracle就是对应不同的用户上(并非schema与用户等同)。
2. 实战案例
2.1 分区数据
注:请先确保你当前使用的SpringBoot版本(Spring Data JPA)整合的Hibernate版本至少是6.0版本以上。
实体定义
@Entity
@Table(name = "t_person")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id ;
private String name ;
private Integer age ;
@TenantId
private String tenantId ;
}这里通过@TenantId注解标注,该字段专门用来分区租户的,Hibernate在查询数据时会自动添加该查询条件,如果你使用的本地SQL(自己编写SQL),那么需要你自行添加该条件(租户ID条件)。
编写DAO&Service
// DAO
public interface PersonRepository extends JpaRepository<Person, Long>, JpaSpecificationExecutor<Person> {
}
// Service
@Service
public class PersonService {
private final PersonRepository personRepository ;
public PersonService(PersonRepository personRepository) {
this.personRepository = personRepository ;
}
// 查询所有Person数据
public List<Person> persons() {
return this.personRepository.findAll() ;
}
}Controller接口
@GetMapping("")
public List<Person> persons() {
return this.personService.persons() ;
}以上是开发一个业务功能的基本操作,接下来才是重点
租户标识解析处理
该的作用获取当前租户ID,这里基于ThreadLocal实现
public class TenantIdResolver implements CurrentTenantIdentifierResolver<String> {
private static final ThreadLocal<String> CURRENT_TENANT = new ThreadLocal<>();
public void setCurrentTenant(String currentTenant) {
CURRENT_TENANT.set(currentTenant);
}
@Override
public String resolveCurrentTenantIdentifier() {
// 注意这里不能返回null
return Optional.ofNullable(CURRENT_TENANT.get()).orElse("default") ;
}
@Override
public boolean validateExistingCurrentSessions() {
return true;
}
}上面的组件用来从当前的ThreadLocal中获取租户ID,接下来就是像ThreadLocal存入租户ID。
Web拦截器
该拦截器的作用用来从请求Header中获取租户ID,存入ThreadLocal中。
@Component
public class TenantIdInterceptor implements HandlerInterceptor {
private final TenantIdResolver tenantIdResolver;
public TenantIdInterceptor(TenantIdResolver tenantIdResolver) {
this.tenantIdResolver = tenantIdResolver;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String tenantId = request.getHeader("x-tenant-id");
tenantIdResolver.setCurrentTenant(tenantId);
return true ;
}
}最后一步就是配置hibernate,设置租户ID的解析器。
配置租户标识解析器
spring:
jpa:
properties:
hibernate:
'[tenant_identifier_resolver]': 'com.pack.tenant.config.TenantIdResolver'完成以上类及配置的编写后就实现了基于列区分(分区)的多租户架构方案。
测试
准备数据:
 图片
图片
 图片
图片
 图片
图片
SQL执行情况:
 图片
图片
自动添加了tenant_id查询条件。
2.2 独立数据库
每租户对应一个数据库,这需要在项目中配置多个数据源,同时提供一个数据源路由的核心类。
定义多数据源配置
你也可以将数据源的信息专门存放在数据表中。
pack:
datasource:
defaultDs: ds1
config:
ds1:
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/tenant-01
username: tenant01
password: xxxooo
type: com.zaxxer.hikari.HikariDataSource
ds2:
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/tenant-02
username: tenant02
password: oooxxx
type: com.zaxxer.hikari.HikariDataSource在Spring实现多数据源切换,可以通过继承AbstractRoutingDataSource。
public class PackRoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get() ;
}
}
public class DataSourceContextHolder {
private static final ThreadLocal<String> HOLDER = new InheritableThreadLocal<>() ;
public static void set(String key) {
HOLDER.set(key) ;
}
public static String get() {
return HOLDER.get() ;
}
public static void clear() {
HOLDER.remove() ;
}
}配置数据源Bean
@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource(MultiDataSourceProperties properties) {
PackRoutingDataSource dataSource = new PackRoutingDataSource(properties.getDefaultDs()) ;
Map<Object, Object> targetDataSources = new HashMap<>() ;
// PackDataSourceProperties类仅仅就是继承DataSourceProperties
Map<String, PackDataSourceProperties> configs = properties.getConfig() ;
configs.forEach((key, props) -> {
targetDataSources.put(key, createDataSource(props, HikariDataSource.class)) ;
});
dataSource.setTargetDataSources(targetDataSources) ;
return dataSource ;
}
private static <T> T createDataSource(PackDataSourceProperties properties, Class<? extends DataSource> type) {
// 这里没有考虑池的配置
return (T) properties.initializeDataSourceBuilder().type(type).build();
}
}接下来定义拦截器,设置当前要操作的数据源。
Web拦截器
@Component
public class TenantIdInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String tenantId = request.getHeader("x-tenant-id");
DataSourceContextHolder.set(tenantId) ;
return true ;
}
}以上就完成了多数据源的所有类及配置的编写。