TinyLLaVA 项目由清华大学电子系多媒体信号与智能信息处理实验室 (MSIIP) 吴及教授团队和北京航空航天大学人工智能学院黄雷老师团队联袂打造。清华大学 MSIIP 实验室长期致力于智慧医疗、自然语言处理与知识发现、多模态等研究领域。北航团队长期致力于深度学习、多模态、计算机视觉等研究领域。
近日,清华和北航联合推出了 TinyLLaVA Factory, 一款支持定制、训练、评估多模态大模型的代码库,代码和模型全部开源。该代码库以软件工程的工厂模式作为设计理念,模块化地重构了 LLaVA 代码库,注重代码的可读性、功能的扩展性、和实验效果的可复现性。方便研究者和实践家们更容易地探索多模态大模型的训练和设计空间。

- Github 项目:https://github.com/TinyLLaVA/TinyLLaVA_Factory
- 论文地址:https://arxiv.org/abs/2405.11788
- Hugging Face 模型地址:https://huggingface.co/tinyllava/TinyLLaVA-Phi-2-SigLIP-3.1B or https://huggingface.co/bczhou/TinyLLaVA-3.1B-SigLIP
- 机器之心 SOTA 模型地址:https://sota.jiqizhixin.com/project/tinyllava
LLaVA 作为多模态社区的优质开源项目,备受研究者和开发者的青睐;新入坑多模态大模型的初学者们也习惯以 LLaVA 项目作为起点,学习和训练多模态大模型。但是 LLaVA 项目的代码较为晦涩难懂,一旦不慎更改错误,就可能会影响训练效果,对于新手来说,往往不敢轻易修改其中的细节,给理解和探索多模态大模型的本质细节造成了一定的困难。
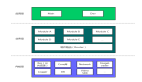
近日,清华和北航联合推出 TinyLLaVA Factory,将本来的 LLaVA 代码进行模块化重构,专注于简洁的代码实现、新功能的可扩展性、以及训练结果的可复现性,让你以最小的代码量,定制并训练属于自己的多模态大模型,同时减少代码错误率!相同的模型配置、训练数据和训练策略条件下,使用 TinyLLaVA Factory 可训练出比用 LLaVA 代码性能略胜一筹的模型。为了让用户更容易地读懂代码和使用模型,TinyLLaVA Factory 项目还配备了代码文档和 Demo 网站。其总体架构图如下。

数据预处理部分,TinyLLaVA Factory 摒弃了 LLaVA 代码中烧脑的图片处理和 Prompt 处理过程,提供了标准的、可扩展的图片和文本预处理过程,清晰明了。其中,图片预处理可自定义 Processor,也可使用一些官方视觉编码器的 Processor,如 CLIP ViT 和 SigCLIP ViT 自带的 Image Processor。对于文本预处理,定义了基类 Template,提供了基本的、共用的函数,如添加 System Message (Prompt)、Tokenize、和生成标签 Ground Truth 的函数,用户可通过继承基类就可轻松扩展至不同 LLM 的 Chat Template。


模型部分,TinyLLaVA Factory 很自然地将多模态大模型模块化成 3 个组件 —— 大语言模型组件、视觉编码器组件、中间的连接器组件。每个组件由一个工厂对象控制,负责新模型的注册和替换,使用户能够更容易地替换其中任何一个组件,而不会牵连到其他部分。

TinyLLaVA Factory 为每个组件提供了当前主流的模型,如下表所示。

训练器仍然仿照 LLaVA,采取 Hugging Face 自带的 Trainer,集成了 Gradient Accumulation,Wandb 做日志记录等特性,同样支持 DeepSpeed ZeRO2/ZeRO3 并行训练。对于评估部分,TinyLLaVA Factory 提供了 SQA/GQA/TextVQA/VQAv2/POPE/MME/MM-Vet/MMMU 8 个 Benchmark 的评估。
接下来,划重点!TinyLLaVA Factory Github 项目还手把手教你定制自己的多模态大模型。只需简单地添加 1-2 个文件,就可以轻松替换 LLM 组件、视觉编码器组件、连接器组件。
拿替换 LLM 模型举例。据使用过 LLaVA 代码库的同学反应,LLaVA 代码想替换非 Llama 系列的语言模型容易出错。而 TinyLLaVA Factory 可以方便地替换语言模型,只需添加 2 个 py 文件,一个是 Chat Template 文件,一个是模型文件。替换视觉编码器时,也只需添加 1 个 py 文件,继承视觉编码器的基类即可。

TinyLLaVA Factory 还支持对训练策略进行定制,对使用者来说只需在配置文件中进行修改,就能在 pretraining 和 finetuning 阶段对 3 个模块组件(LLM / 视觉编码器 / 连接器)实现冻住 / 全量微调 / 部分微调 /lora 微调的任意组合。堪称小白易上手式的教程!

早在今年 2 月,TinyLLaVA 项目就敏锐地捕捉到了 3B 以下 LLM 在多模态大模型中的潜力,利用市面主流的小规模 LLM,训练了一系列多模态大模型,参数量在 0.89B-3.1B。实验结果表明经过高质量的数据选择和更加细致的训练策略,利用小规模 LLM 同样可以实现和大模型相近甚至更加优越的任务表现。(细节详见技术报告 https://arxiv.org/abs/2402.14289)