














拉玛的故事
“在安第斯山脉崎岖的山区,生活着三种非常美丽的生物——里约、洛基和塞拉。它们有着光泽的皮毛和闪闪发光的眼睛,是力量和韧性的灯塔。
据说,从很小的时候起,它们对知识的渴望就永无止境。它们会寻找牛群中聪明的长者,聚精会神地听它们的故事,像海绵一样吸收它们的智慧。随着这一点的发展,它们的超能力不断增强,它们与其他动物合作,并了解到团队合作是在安第斯山脉这一充满挑战的地形上赢得选拔赛的关键。
如果它们遇到迷路或需要帮助的旅行者,里约会从它们的角度出发,安慰它们,洛基会迅速提供解决方案,而塞拉会确保它们有足够的力量继续前行。因此,它们赢得了动物族群的钦佩,并鼓励大家以它们为榜样。
当太阳在安第斯山脉上落山时,里约、洛基和塞拉站在一起,它们的精神像山脉一样交织在一起。因此,它们的故事作为知识、智慧和协作的力量以及有所作为的意愿的证明而流传至今。
它们是超级拉玛([译者注]“Llama”音译为拉玛,是一种哺乳动物,属于骆驼科,是南美洲安第斯地区的重要家畜),它们这个三人团队被亲切地称为LlaMA3!”
Meta公司的LlaMA 3
上面的这个故事与Meta开源的大型语言模型(LLM)——LlaMA 3(大型语言模型Meta AI)的故事并不遥远。2024年4月18日,Meta发布了其8B和70B参数大小的大型语言模型LlaMa 3家族,声称这是对LlaMa 2模型的重大飞跃,并努力在这一级别的规模上竞争成为最先进的LLM模型。
Meta公司表示(https://ai.meta.com/blog/meta-llama-3/),在构建LlaMA 3模型时,存在四个关键关注点——模型架构、预训练数据、扩展预训练和指令微调。这不由得让我们思考:如何才能从这种非常有能力的模型中获得最大收益,无论是从企业级规模上还是在基本规模级层面上。
为了帮助探索其中一些问题的答案,我与AWS生成式人工智能团队负责人Edurado Ordax和科罗拉多大学博尔德分校计算机科学专业的Tom Yeh教授展开合作。
接下来,让我们开始这趟“徒步旅行”吧……
如何利用LlaMA 3的威力?
API与微调
来自于最新的应用实践证明,访问和使用这些大型语言模型的主要方式有两种——一种是通过API调用,另一种是对现有模型进行微调。即使存在这样两种非常不同的方法,在此过程中也还存在其他方面的因素,而且这些因素可能会变得至关重要,如下图所示。
(注:本部分中的所有图片均由Eduardo Ordax提供。)
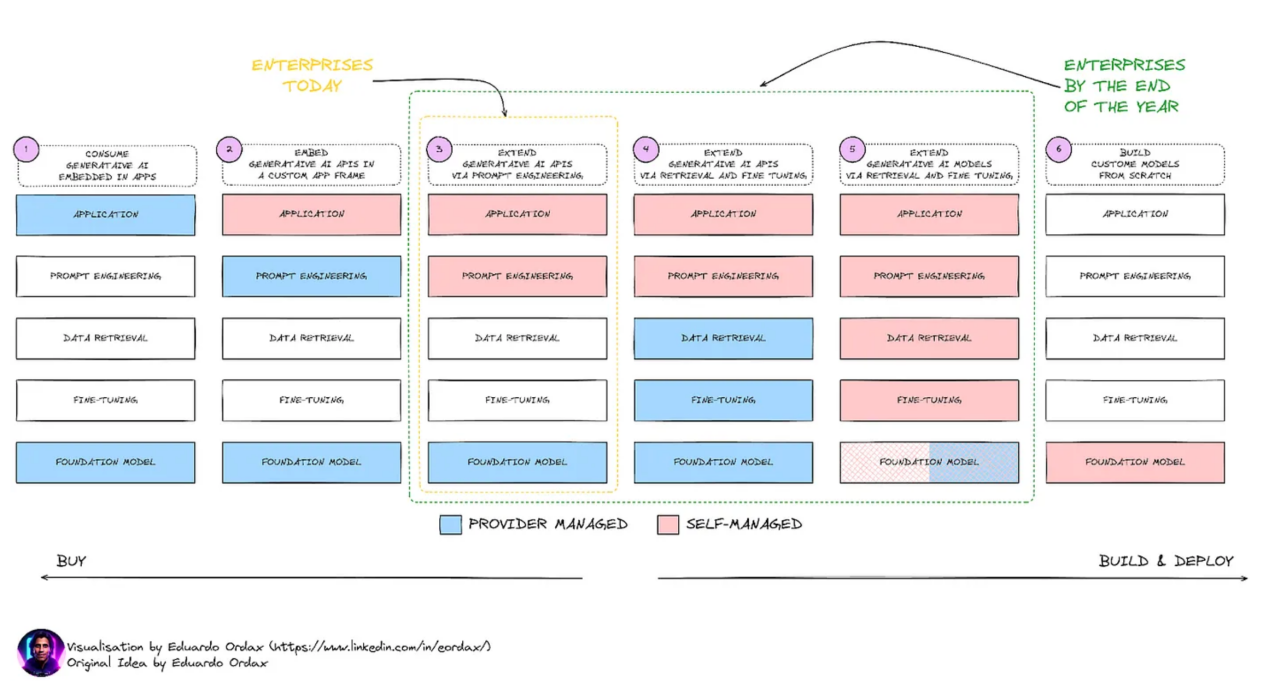
归纳来看,用户与LlaMA3进行交互的方式主要分为6个阶段。
第1阶段:通过按原样使用模型,以适应广泛的应用场景。
第2阶段:在用户自定义的应用程序中使用模型。
第3阶段:使用提示工程来训练模型,以产生所需的输出。
第4阶段:在用户端使用提示工程,同时深入研究数据检索和微调,这仍然主要由LLM提供商管理。
第5阶段:把大部分事情掌握在自己(用户)手中,从提示工程到数据检索和微调(RAG模型、PEFT模型等)等诸多任务。
第6阶段:从头开始创建整个基础模型——从训练前到训练后。
为了最大限度地利用这些模型,建议最好的方法是使用上面的第5阶段,因为灵活性很大程度上取决于用户自身。能够根据领域需求定制模型对于最大限度地提高其收益至关重要。因此,如果不参与到系统开发中,是不能产生最佳回报的。
为了实现上述过程,下图给出的是一些可能经证明是非常有用的一些开发工具的列表:
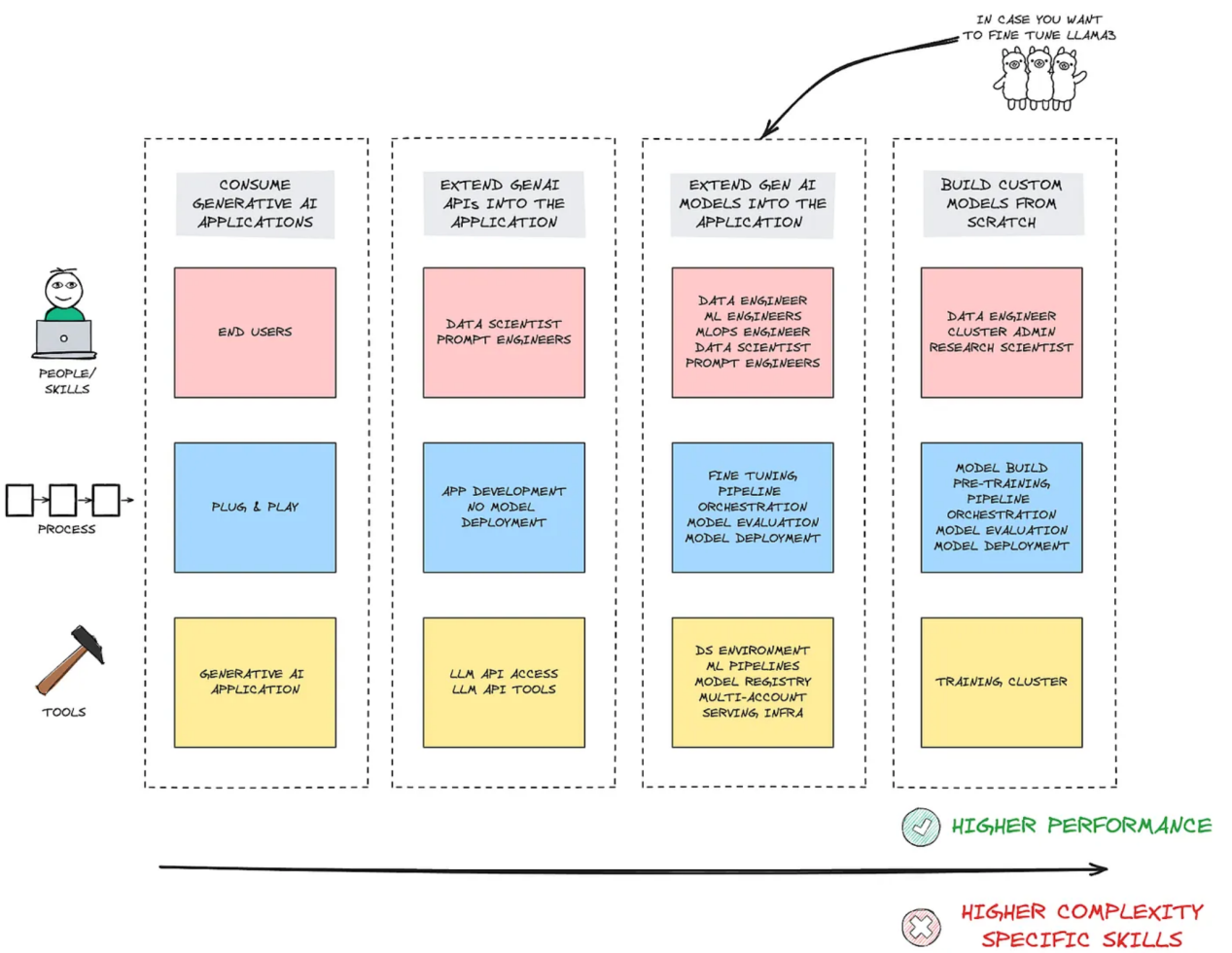
从图中可以看出,为了从模型中获得最大的利益,掌握一系列组件和开发路线图是必不可少的。归纳起来看,这可以分为三个组成部分:
- 人员:不仅是最终用户,整个数据工程师、数据科学家、MLOps工程师、ML工程师以及Prompt工程师都很重要。
- 流程:不仅是将LLM以API形式实现,更应专注于模型评估、模型部署和微调的整个生命周期,以满足特定需求。
- 工具:不仅仅是API访问和API工具,还有整个环境、不同的ML管道、用于访问和运行检查的单独帐户等。
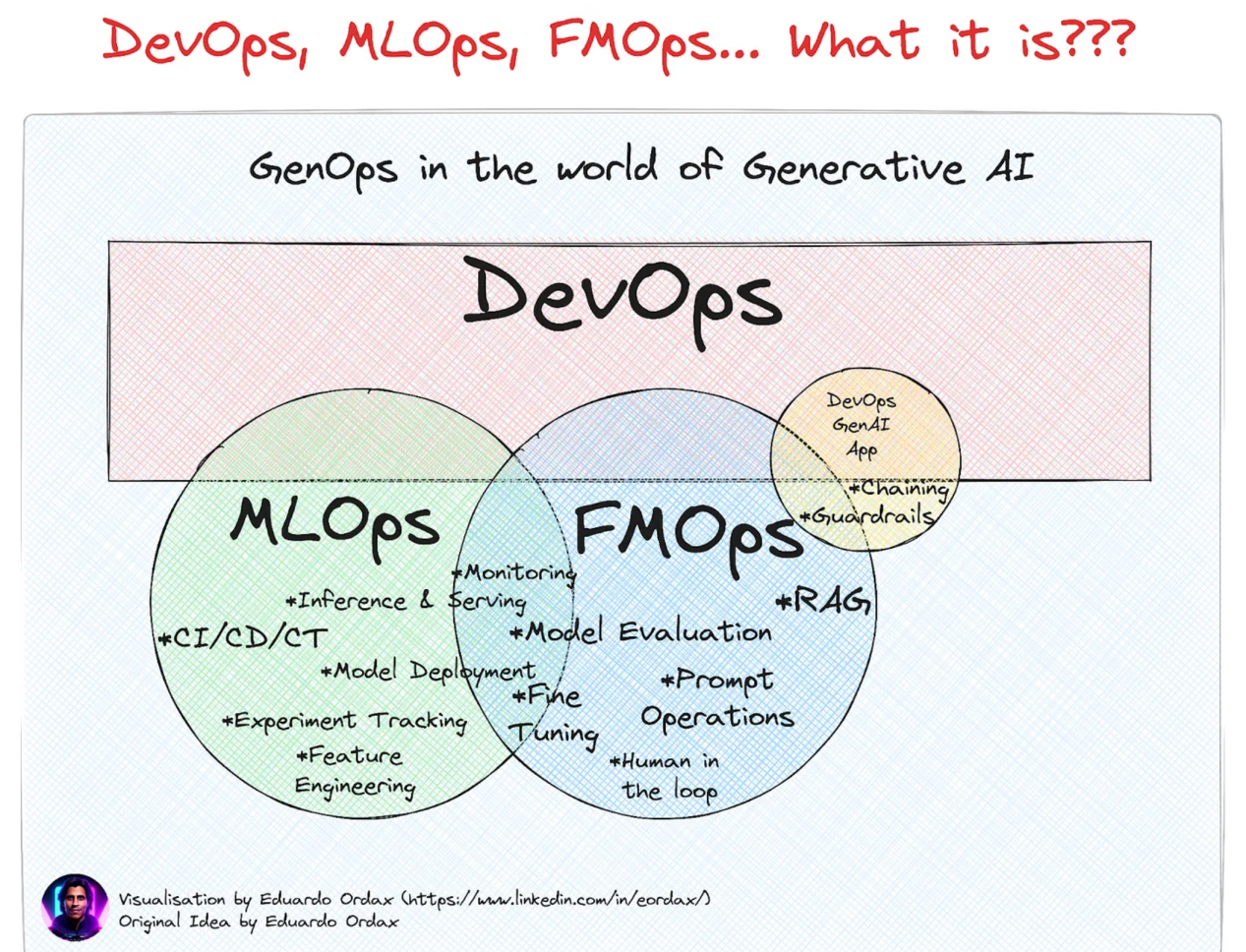
当然,企业级部署也是如此,这样可以获得模型的实际好处。要做到这一点,MLOps相关的工具和实践变得非常重要。与FMOps相结合,这些模型非常有价值,有助于丰富整个生成式人工智能生态系统。
补注

MLOps也称为机器学习操作,是机器学习工程的一部分,专注于ML模型的开发、部署和维护,确保它们可靠高效地运行。MLOps隶属于DevOps(开发和运营),但专门针对ML模型。
另一方面,FMOps(基础模型操作)通过选择、评估和微调LLM,为生成式人工智能场景工作。
尽管如此,有一点是不变的。LlaMA 3毕竟是一个大型语言模型;因此,只有在严格设置和验证了基础元素后,它在企业级的实现才是可能的,也是有益的。为了做到这一点,让我们接下来深入探索一下LlaMA 3模型背后的技术细节。
LlaMa 3成名的秘诀是什么?
在基本层面上,LlaMa 3就是一个转换器。如果我们在这个过程中站在更高一些的高度,答案将成为“转换器架构”,但是这种架构是经过高度优化的,可以在通用行业基准上实现卓越的性能,同时还可以实现更加新颖的功能。
由于LlaMa 3是开放式的(由Meta公司自行决定完全开放源码),我们可以访问此模型的完整资料,这为我们提供了如何配置这种强大架构的详细信息。
接下来,让我们深入了解并揭示其中的秘密:
转换器架构与自我关注是如何在LlaMA 3中发挥作用的?
首先,这里简要介绍一下转换器的工作原理:
- 转换器架构可以被视为注意力层和前馈层的组合。
- 注意力层水平组合跨特征,以产生新特征。
- 前馈层(FFN)将部件或特征的特性组合在一起,以产生新的部件/特征。它在各个维度上垂直进行。
(除非另有说明,本节中的所有图片均为Tom Yeh教授的作品,我经其许可进行了编辑。)
下图展示了该架构的外观及其运行机制。
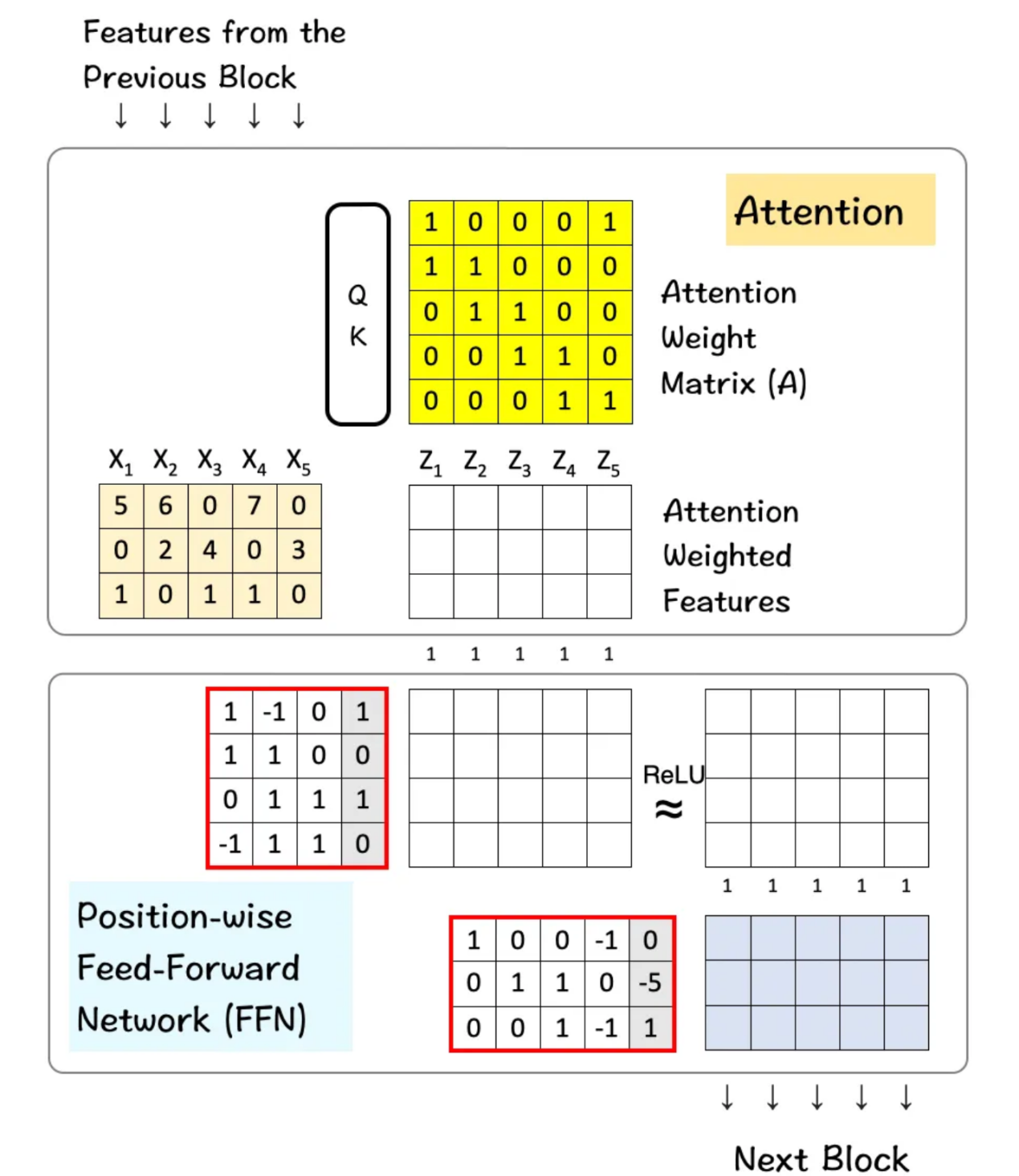
包含注意力和前馈块的转换器架构
链接https://medium.com/towards-data-science/deep-dive-into-transformers-by-hand-%EF%B8%8E-68b8be4bd813处提供了有关转换器的介绍,而链接https://medium.com/towards-data-science/deep-dive-into-self-attention-by-hand-%EF%B8%8E-f02876e49857提供了有关自注意力的深入探讨文章,有兴趣的读者可以参考阅读。
LlaMA 3的本质
现在,我们开始深入的探索,了解转换器数量在现实生活中的LlaMa 3模型中的重要表现。在我们的讨论中,我们将只考虑此模型的8B变体。
LlaMA 3-8B的模型参数是什么?
我们在这里需要探索的主要数字/值是针对在转换器架构中发挥关键作用的参数。这些参数包括:
- 层(Layers):这里的层指的是转换器的基本块——注意力层和FFN,如上图所示。这些层以堆叠方式排列,一层堆叠在另一层之上,输入流入一层,其输出传递到下一层,逐渐转换输入数据。
- 注意力头(Attention heads):注意力头是自我注意力机制的一部分。每个头独立扫描输入序列并执行注意步骤(请记住QK模块及SoftMax函数在其中的作用)。
- 词汇(Vocabulary words):词汇是指模型识别或知道的单词数量。从本质上讲,把它看作是人类构建单词库的方式,这样我们就可以发展语言的知识和通用性。大多数情况下,词汇表越大,模型性能越好。
- 特征维度(Feature dimensions):这些维度指定表示输入数据中每个标记的向量的大小。从输入嵌入到每一层的输出,这个数字在整个模型中保持一致。
- 隐藏层维度(Hidden dimensions):这些维度是模型中层的内部尺寸,更常见的是前馈层的隐藏层的尺寸。通常情况下,这些层的大小可以大于特征维度,这有助于模型从数据中提取和处理更复杂的表示。
- 上下文窗口大小(Context-window size):这里的“窗口大小”是指模型在计算注意力时同时考虑输入序列中的标记数量。
根据定义的术语,让我们参考LlaMA 3模型中这些参数的实际数字。(这些数字的原始源代码可以从链接https://github.com/meta-llama/llama3/tree/main/llama处找到。)
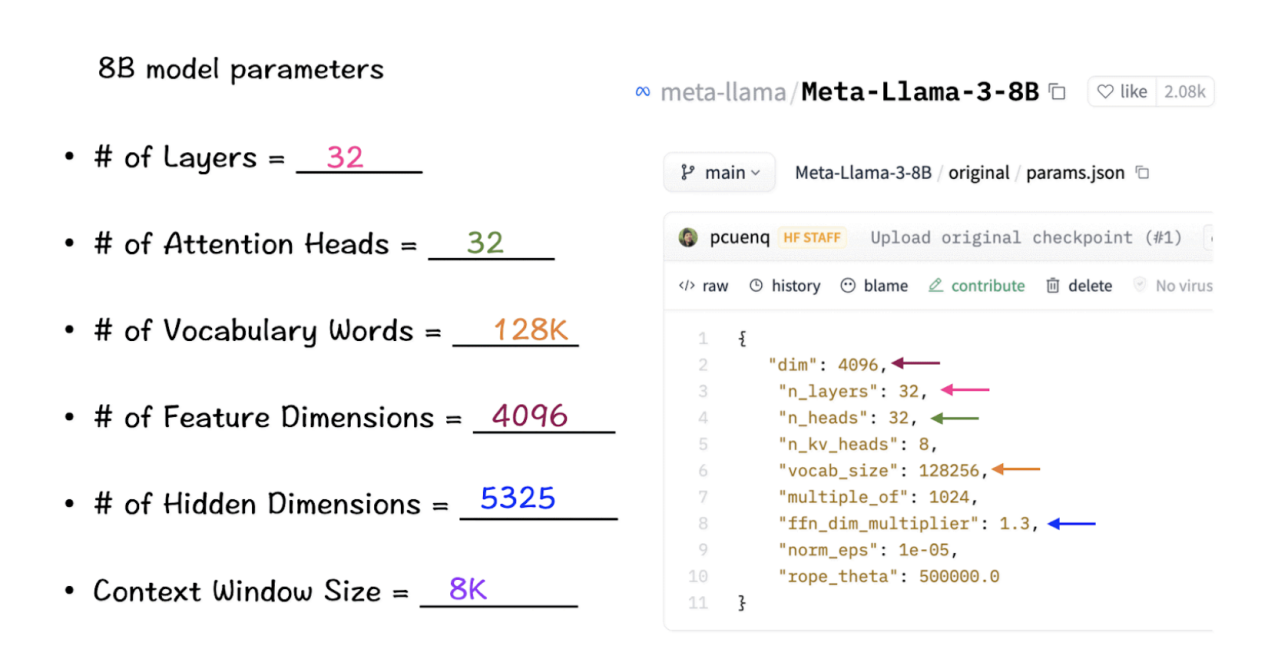
请牢记这些数值,接下来的步骤将说明它们中的每一个如何在模型中发挥作用。注意,它们在源代码中是按出现顺序列出的。
上下文窗口
在实例化LlaMa类时,变量max_seq_len用于定义上下文窗口。当然,这个类中还包含其他一些参数,但是这一个参数符合我们关于转换器模型的目的。这里的max_seq_len是8K,这意味着注意力头能够一次扫描8K个标记。

词汇大小和注意力层
接下来是Transformer类,它定义了词汇表的大小和层数。这里的词汇表大小仍然指的是模型可以识别和处理的一组单词(和标记)。此外,这里的注意层是指模型中使用的转换器块(注意力层和前馈层的组合)。
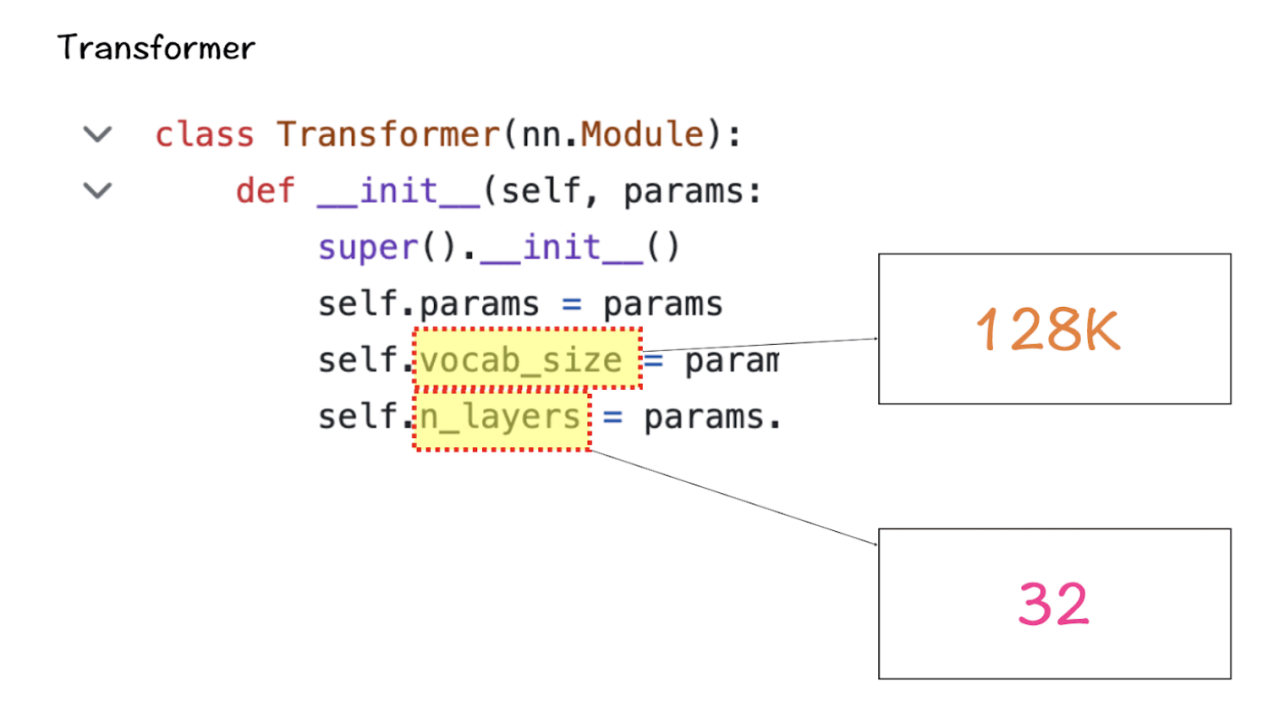
基于这些数字,LlaMA 3的词汇量将达到128K,这是相当大的一个量级。此外,该模型还有32个转换器块的副本。
特征尺寸和注意力头
在自我注意力模块中,主要的组成是特征维度和注意力头。其中,特征维度是指嵌入空间中标记的向量大小,注意力头由QK模块组成,该模块负责为转换器中的自注意力机制提供动力。

隐藏层维度
前馈类中的隐藏层维度特征用于指定模型中的隐藏层数。对于LlaMa 3模型来说,隐藏层的大小是特征尺寸的1.3倍。大量的隐藏层允许网络在将其投影回较小的输出维度之前,在内部创建和操作更丰富的表示。

将以上参数组合形成转换器
- 第一个矩阵是输入特征矩阵,它通过注意力层来创建注意力加权特征。在该图像中,输入特征矩阵的大小仅为5 x 3矩阵,但在真实世界的Llama 3模型中,它增长到8K x 4096,这个尺寸是巨大的。
- 下一个矩阵是前馈网络中的隐藏层,它增长到5325,然后在最后一层回落到4096。
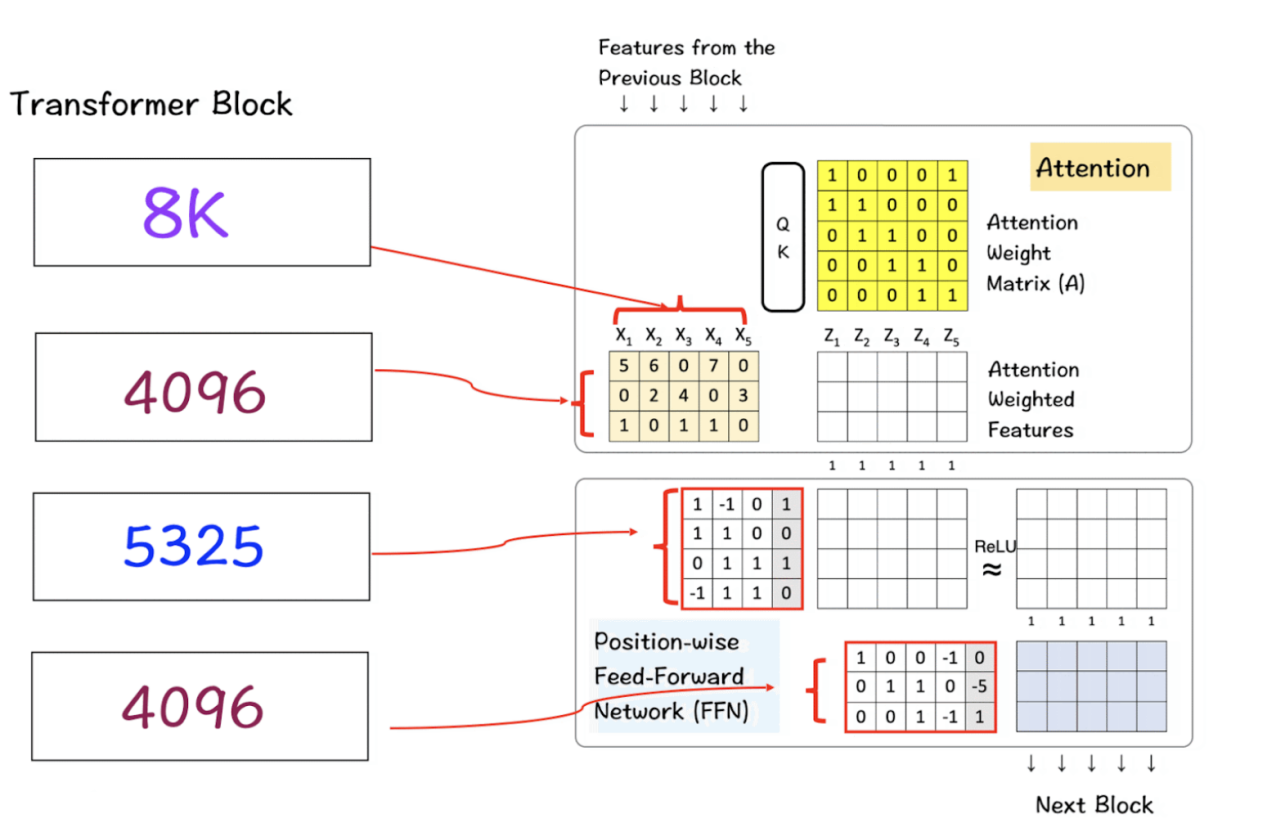
转换器块中的多层
LlaMA 3将上述转换器块中的32个块与向下传递到下一个块中的一个块的输出相组合,直至到达最后一个块。
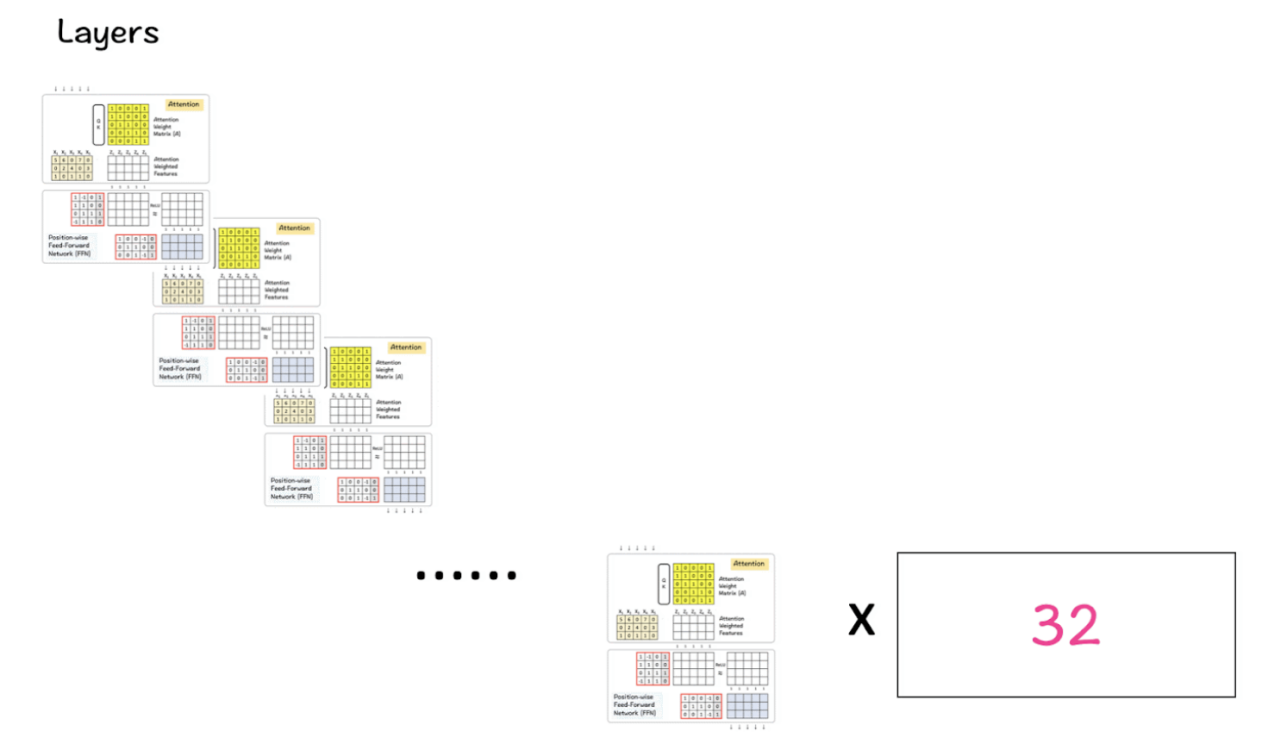
组合到一起
到现在为止,我们了解了上述各个部分的组成与作用。接下来,我们就可以把它们组合到一起,看看它们是如何产生LlaMA模型的结果的,请参考下图。
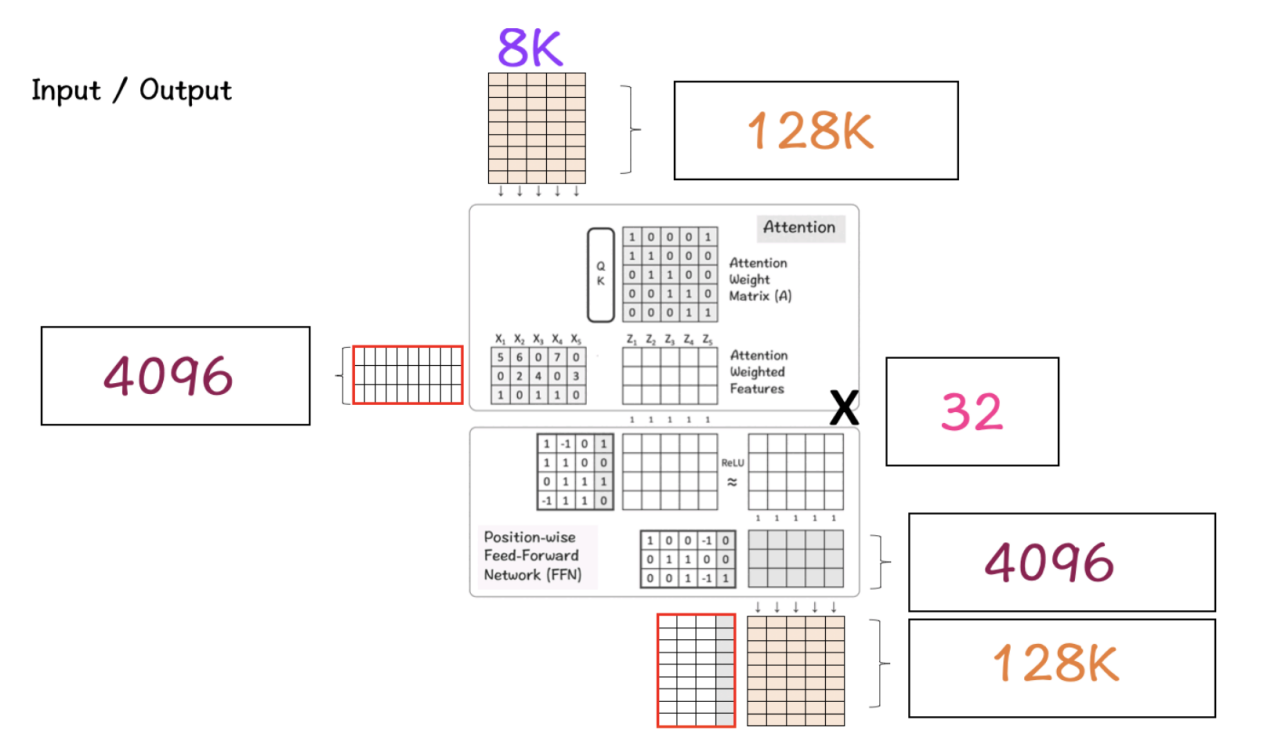
这一阶段会发生什么呢?
步骤1:首先,我们有一个输入矩阵,它的大小是8K(上下文窗口)x 128K(词汇大小)。该矩阵经历将该高维矩阵带入低维的嵌入过程。
步骤2:在这种情况下,这个较低的维度是4096,这是我们之前看到的LlaMA模型中特征的指定维度。(从128K减少到4096是极大幅度的减少,这一点值得注意。)
步骤3:此功能经过Transformer块,首先由Attention层处理,然后由FFN层处理。注意力层负责在水平方向上处理特征,而FFN层负责在垂直方向上处理维度。
步骤4:对转换器块的32层重复执行步骤3。最终,得到的矩阵具有与用于特征维度的矩阵相同的维度。
步骤5:最后,将该矩阵转换回128K大小的词汇表矩阵的原始大小,以便模型可以选择并映射词汇表中可用的单词。
总之,上述步骤解释了为什么LlaMA 3模型在有关基准上得分很高,并产生了Lla MA 3效应。
LlaMA3效应
当前,LlaMA 3发布了两个模型版本——8B和70B参数,以服务于广泛的应用场景。除了在标准基准上实现最先进的性能外,还开发了一套新的、严格的人类评估集。最近,Meta公司还承诺将会陆续发布更好、更强的模型版本,并使其成为多语言和多模式的。有消息说,Meta公司即将推出更新和更大的模型,参数将超过400B(链接https://ai.meta.com/blog/meta-llama-3/处早期报告显示,这一模型已经超过了基准指标,与LlaMA 3模型相比增加了近20%的得分)。
然而,必须指出的是,尽管存在即将到来的模型更改和更新,但有一点将保持不变——所有这一切更改和更新的基础——实现这一令人难以置信的技术进步的转换器架构和转换器块。
最后,LlaMA模型被如此命名可能是巧合,但根据安第斯山脉的传说,真正的美洲驼一直因其力量和智慧而备受尊敬,这与第二代人工智能“LlaMA”模型没有太大区别。
所以,让我们跟随GenAI安第斯山脉的这段激动人心的旅程,同时牢记这些大型语言模型的基础吧!
【附言】如果你想自己完成本文中介绍的这个练习,下面链接提供一个空白的模板,供你使用。
徒手练习空白模板地址:https://drive.google.com/file/d/1NfHBSQQTgH1bPXiNUHyMhT2UGXqUaTPE/view?usp=drive_link。
现在,您可以尽情去把玩LlaMA3模型,创造一些美妙的LlaMA3效果了!
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Deep Dive into LlaMA 3 by Hand,作者:Srijanie Dey
链接:https://towardsdatascience.com/deep-dive-into-llama-3-by-hand-%EF%B8%8F-6c6b23dc92b2。





























